《Linux及安全》实践三 字符集总结与分析
【by lwr】
一、ISO、UCS/UTF、GB系列字符集分析
1.字符集&字符编码
-
字符集(Charset):是一个系统支持的所有抽象字符的集合。也就是说,这是相对固定的、包含大量字符的集合。
-
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。也就是说,这是动态的、方法性质的编码规则。
2.ASCII码
-
总述:
- ASCII(美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统,等同于国际标准ISO/IEC 646
-
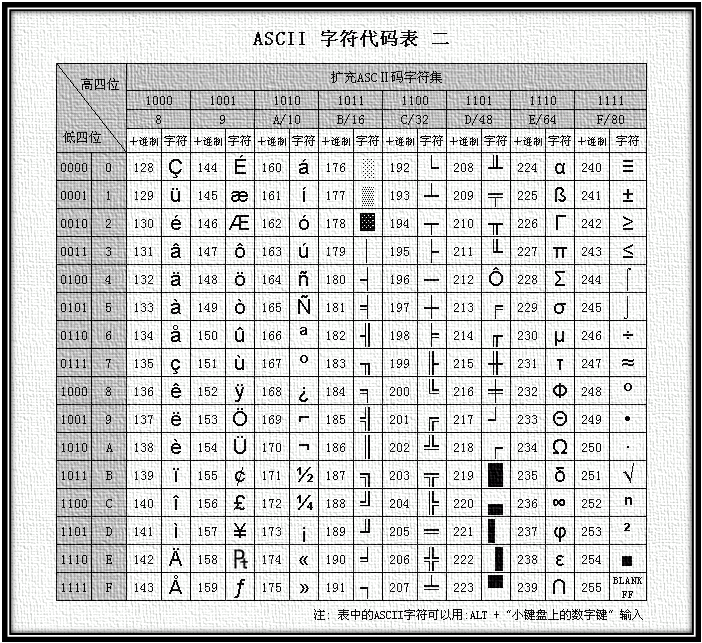
码字表
- ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语。
3.GB码
- 总述:
- GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布
- GB2312规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样就可以组合出大约7000多个简体汉字
- 在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符。
4.UCS/UTF
- 总述:
- 通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集
- Unicode 是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式[1]对外发表。Unicode 还不断在扩增, 每个新版本插入更多新的字符。
- 以UTF-8为例
- UTF-8使用一至四个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
- 其他极少使用的Unicode辅助平面的字符使用四字节编码。
- UTF-8使用一至四个字节为每个字符编码:
二、设置、修改系统默认字符集
1.查看虚拟机的字符集:
-
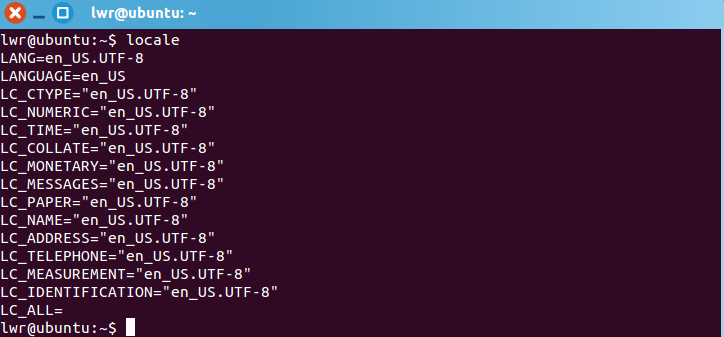
- 由此可见,该虚拟机的字符集为zh_US.UTF-8。
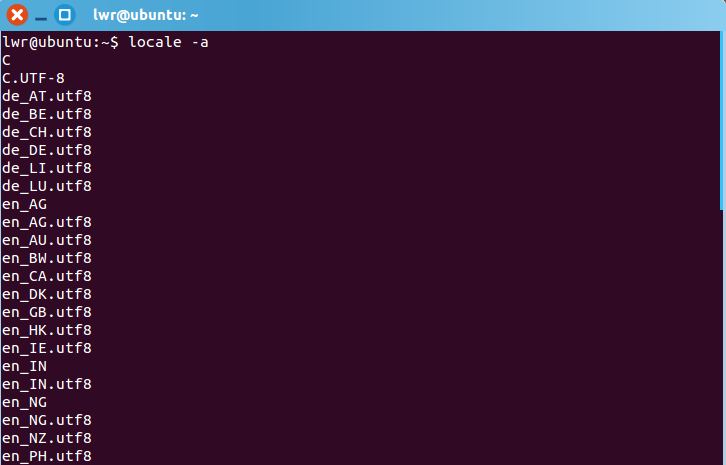
2.查看服务器支持的编码方式
3.修改字符集类型
-

- 上图可见,LANG字符集类型修改为en_CA.utf-8。
4.查看某个文件的字符类型
-

- 由此可见,我选择的hello.c文件是ASCII编码方式的
三、同一文件的不同存储方式
1.编写文件并以不同方式存储
-
编写内容均为“20135216刘蔚然[回车]LWR”的文本文件,分别用ANSI、Unicode、Unicode big endian、UTF-8的编码方式存储
-
下载并安装UltraEdit
-
用该软件打开对应文件之后,转换为16进制
-
查看编码表,找到分别对应ANSI、Unicode、UTF-8的本人姓名编码
- C1F5 5218 E5 88 98 刘
- CEB5 851A E8 94 9A 蔚
- C8BB 7136 E7 84 B6 然
-
查看各编码方式
-

- 汉字部分为C1F5 CEB5 C8B8就是“刘蔚然”的gb3212编码,而阿拉伯数字20135216(32 30 31 33 35 32 31 36)和英文字母LWR(4C 57 52)都是用ascii编码表示,大端方式编码。
-

- 最开头有一个FE FF ,代表采用大端方式,依然是unicode编码,5218 851A 7136仍然是Unicode表示本人姓名的编码,而阿拉伯数字20135216(0032 0030 0031 0033 0035 0032 0031 0036)和英文字母LWR(004C 0057 0052)都是用ascii编码表示,也采用大端
-

- 最开头有一个FF FE,代表着ucs-2,采用小端方式,其他同上面的Unicode big endian
-

- 开头是EF BB BF是utf-8的标志,之后的编码按照大端方式排列,汉字实用的是utf-8格式:E5 88 98 E8 94 9A E7 84 B6;而数字20135216仍然是ASCII码(32 30 31 33 35 32 31 36),字母也是ASCII码(LWR)
-
-
总结
- 我们发现这4种编码方式只是汉字不同格式运用不同编码,而阿拉伯数字和英文字母都是用ascii编码表示,也就是为什么我们有时候打开一个文件会出现乱码,而阿拉伯数字和英文字母都是正常的原因,汉字在不同的编码格式中都是有不同的汉字编码,而阿拉伯数字和英文字母通用ascii编码表示。