课后作业-结对编程项目总结
结对编程作业-英文词频检测
结对成员:杨琳、刘文帅
关于该项目我们一开始是查阅了大量的资料,先制定了计划分步实施,期间遇到了太多困难和波折,很多想要实现的效果通过自己能力写出来的代码并不能实现,所以我们又查阅大量资料,找了老师和一些有经验的同学,让他们交我们如何实现,也借鉴了很多前人的文件,最后我们完成到现在这样。我们从一开始的设想到现在的实际代码,中间经历了太多的波折付出了太多的时间和精力。
最初的设计,我使用了MYSQL数据库来存储每一个单词的词频变化,最终寄希望于在数据库中生成一个每个单词的词频统计数据。
当时建立了一个表,该表极为简单,只有两列:单词,词频。这样做显然也是很简单的,我只需要做 查找、修改和更新的操作。而大部分的程序就不需要我自己写了。
我来呈现一下当时的想法:
1.对文本中非英语的一切字符进行过滤,只留下英语和必要的空格(标点符号换成空格,空格能够区分不同单词,同时对于英语中特别的字符要加以处理)
2、过滤出单词
3、对单词首先在数据表中“查找”操作,如果存在,则更新值,如果不存在,则插入值。
4、寻找合适的呈现方法,将最终的数据呈现出来,表格、文件等
在实施过程中,遇到了一个棘手的问题,在对单个年份的文档进行处理的时候是可以的,但是对于数十年的文档处理时候,会报一个数据库连接池到达最大连接数的错误。
在该错误出现后,对该错误进行反复测试,发现为可重现错误,首先对自己的程序进行检查,尽量再次优化减少存储数据库的次数,我修改了数据库,但最终失败了。
接下来总结了一下我们的思路:
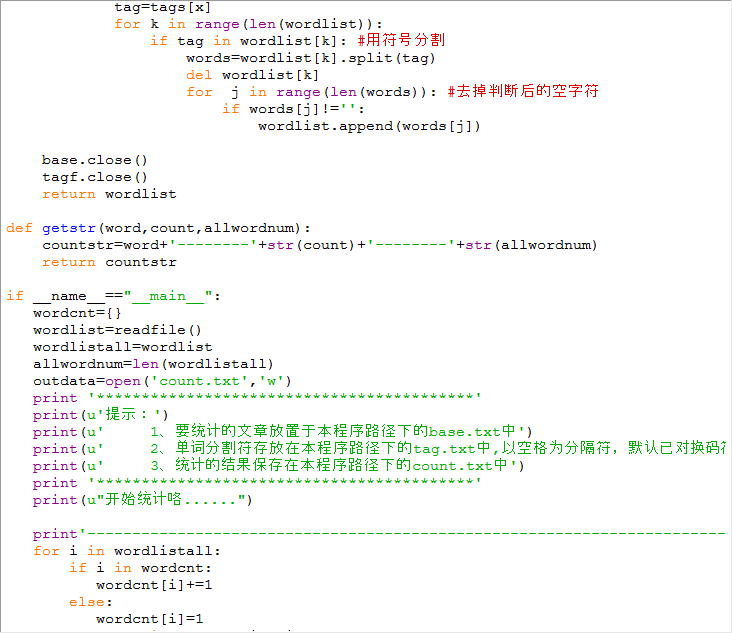
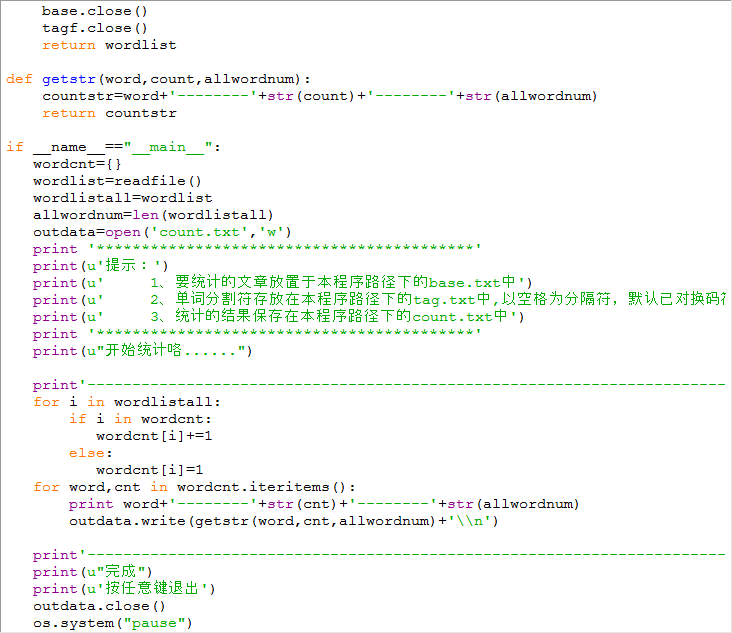
1.文本读取模块(txt文本)
2.以空格为分隔符的txt文档
3.过滤模块(不过滤字母,单引号和-符)
4.统计模块
5.输出模块(CSV文件)
实现方式
[x] 使用open函数, 将数据整理为列表
[x] 使用re包, 通过简单的正则过滤列表
[x] 遍历列表, 使用字典和sort函数存储统计
[x] 输出模块, 采用代码
项目托管平台地址:https://gitee.com/w789369/YingWenCiPinJianCe/blob/master/text.py
通过这次的结队编程发现了自己在对代码的实际应用里有许多问题,对代码的理解还不够。思路不够清晰,经常要想很久再写下一步。通过这次我想以后更多机会尝试使用这些代码,要很熟练的掌握它们。