原文:http://see.xidian.edu.cn/cpp/html/475.html
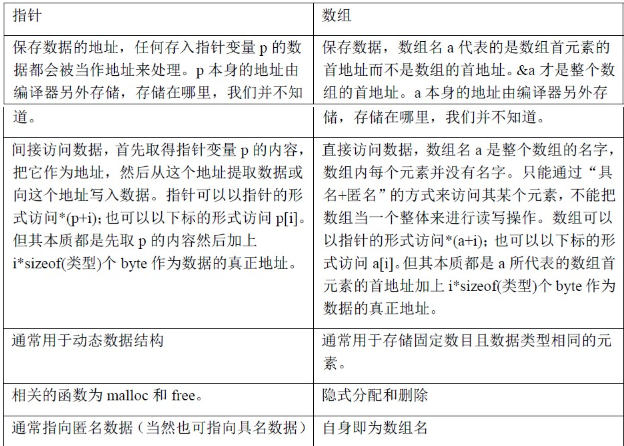
指针就是指针,指针变量在32 位系统下,永远占4 个byte,其值为某一个内存的地址。指针可以指向任何地方,但是不是任何地方你都能通过这个指针变量访问到。
数组就是数组,其大小与元素的类型和个数有关。定义数组时必须指定其元素的类型和个数。数组可以存任何类型的数据,但不能存函数。
既然它们之间没有任何关系,那为何很多人把数组和指针混淆呢?甚至很多人认为指针和数组是一样的。这就与市面上的C 语言的书有关,几乎没有一本书把这个问题讲透彻,讲明白了。
一、以指针的形式访问和以下标的形式访问 下面我们就详细讨论讨论它们之间似是而非的一些特点。例如,函数内部有如下定义: A) char *p = “abcdef”; B) char a[] = “123456”;
1、以指针的形式访问和以下标的形式访问指针 例子A)定义了一个指针变量p,p 本身在栈上占4 个byte,p 里存储的是一块内存的首地址。这块内存在静态区,其空间大小为7 个byte,这块内存也没有名字。对这块内存的访问完全是匿名的访问。比如现在需要读取字符‘e’,我们有两种方式: 1) 以指针的形式:*(p+4)。先取出p 里存储的地址值,假设为0x0000FF00,然后加上4 个字符的偏移量,得到新的地址0x0000FF04。然后取出0x0000FF04 地址上的值。
2) 以下标的形式:p[4]。编译器总是把以下标的形式的操作解析为以指针的形式的操作。p[4]这个操作会被解析成:先取出p 里存储的地址值,然后加上中括号中4 个元素的偏移量,计算出新的地址,然后从新的地址中取出值。也就是说以下标的形式访问在本质上与以指针的形式访问没有区别,只是写法上不同罢了。
2、以指针的形式访问和以下标的形式访问数组 例子B)定义了一个数组a,a 拥有7 个char 类型的元素,其空间大小为7。数组a 本身在栈上面。对a 的元素的访问必须先根据数组的名字a 找到数组首元素的首地址,然后根据偏移量找到相应的值。这是一种典型的“具名+匿名”访问。比如现在需要读取字符‘5’,我们有两种方式: 1) 以指针的形式:*(a+4)。a 这时候代表的是数组首元素的首地址,假设为0x0000FF00,然后加上4 个字符的偏移量,得到新的地址0x0000FF04。然后取出0x0000FF04 地址上的值。
2) 以下标的形式:a[4]。编译器总是把以下标的形式的操作解析为以指针的形式的操作。a[4]这个操作会被解析成:a 作为数组首元素的首地址,然后加上中括号中4 个元素的偏移量,计算出新的地址,然后从新的地址中取出值。
由上面的分析,我们可以看到,指针和数组根本就是两个完全不一样的东西。只是它们都可以“以指针形式”或“以下标形式”进行访问。一个是完全的匿名访问,一个是典型的具名+匿名访问。一定要注意的是这个“以XXX 的形式的访问”这种表达方式。
另外一个需要强调的是:上面所说的偏移量4 代表的是4 个元素,而不是4 个byte。只不过这里刚好是char 类型数据1 个字符的大小就为1 个byte。记住这个偏移量的单位是元素的个数而不是byte 数,在计算新地址时千万别弄错了。
二、a 和&a 的区别 通过上面的分析,相信你已经明白数组和指针的访问方式了,下面再看这个例子: main() { int a[5]={1,2,3,4,5}; int *ptr=(int *)(&a+1); printf("%d,%d",*(a+1),*(ptr-1)); } 打印出来的值为多少呢? 这里主要是考查关于指针加减操作的理解。
对指针进行加1 操作,得到的是下一个元素的地址,而不是原有地址值直接加1。所以,一个类型为T 的指针的移动,以sizeof(T) 为移动单位。因此,对上题来说,a 是一个一维数组,数组中有5 个元素; ptr 是一个int 型的指针。
&a + 1: 取数组a 的首地址,该地址的值加上sizeof(a) 的值,即&a + 5*sizeof(int),也就是下一个数组的首地址,显然当前指针已经越过了数组的界限。
(int *)(&a+1): 则是把上一步计算出来的地址,强制转换为int * 类型,赋值给ptr。
*(a+1): a,&a 的值是一样的,但意思不一样,a 是数组首元素的首地址,也就是a[0]的首地址,&a 是数组的首地址,a+1 是数组下一元素的首地址,即a[1]的首地址,&a+1 是下一个数组的首地址。所以输出2*(ptr-1): 因为ptr 是指向a[5],并且ptr 是int * 类型,所以*(ptr-1) 是指向a[4] ,输出5。
这些分析我相信大家都能理解,但是在授课时,学生向我提出了如下问题:在Visual C++6.0 的Watch 窗口中&a+1 的值怎么会是(x0012ff6d(0x0012ff6c+1)呢?
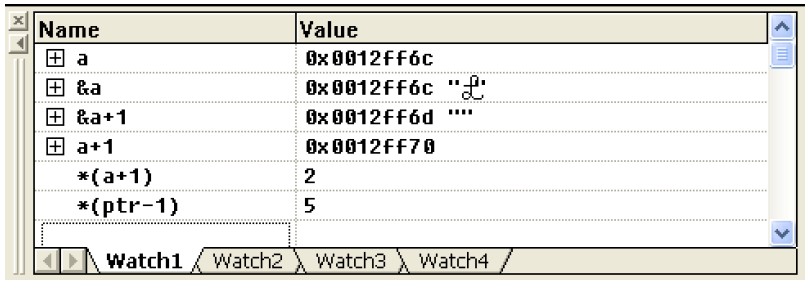
上图是在Visual C++6.0 调试本函数时的截图。 a 在这里代表是的数组首元素的地址即a[0]的首地址,其值为0x0012ff6c。 &a 代表的是数组的首地址,其值为0x0012ff6c。 a+1 的值是0x0012ff6c+1*sizeof(int),等于0x0012ff70。
问题就是&a+1 的值怎么会是(x0012ff6d(0x0012ff6c+1)呢?
按照我们上面的分析应该为0x0012ff6c+5*sizeof(int)。其实很好理解。当你把&a+1放到Watch 窗口中观察其值时,表达式&a+1 已经脱离其上下文环境,编译器就很简单的把它解析为&a 的值然后加上1byte。而a+1 的解析就正确,我认为这是Visual C++6.0 的一个bug。既然如此,我们怎么证明证明&a+1 的值确实为0x0012ff6c+5*sizeof(int)呢?很好办,用printf 函数打印出来。这就是我在本书前言里所说的,有的时候我们确实需要printf 函数才能解决问题。你可以试试用printf("%x",&a+1);打印其值,看是否为0x0012ff6c+5*sizeof(int)。注意如果你用的是printf("%d",&a+1);打印,那你必须在十进制和十六进制之间换算一下,不要冤枉了编译器。
另外我要强调一点:不到非不得已,尽量别使用printf 函数,它会使你养成只看结果不问为什么的习惯。比如这个列子,*(a+1)和*(ptr-1)的值完全可以通过Watch 窗口来查看。
平时初学者很喜欢用“printf("%d,%d",*(a+1),*(ptr-1));”这类的表达式来直接打印出值,如果发现值是正确的就欢天喜地。这个时候往往认为自己的代码没有问题,根本就不去查看其变量的值,更别说是内存和寄存器的值了。更有甚者,printf 函数打印出来的值不正确,就措手无策,举手问“老师,我这里为什么不对啊?”。长此以往就养成了很不好的习惯,只看结果,不重调试。这就是为什么同样的几年经验,有的人水平很高,而有的人水平却很低。其根本原因就在于此,往往被一些表面现象所迷惑。printf 函数打印出来的值是对的就能说明你的代码一定没问题吗?我看未必。曾经一个学生,我让其实现直接插入排序算法。很快他把函数写完了,把值用printf 函数打印出来给我看。我看其代码却发现他使用的算法本质上其实是冒泡排序,只是写得像直接插入排序罢了。等等这种情况数都数不过来,往往犯了错误还以为自己是对的。所以我平时上课之前往往会强调,不到非不得已,不允许使用printf 函数,而要自己去查看变量和内存的值。学生的这种不好的习惯也与目前市面上的教材、参考书有关,这些书甚至花大篇幅来介绍scanf 和printf 这类的函数,却几乎不讲解调试技术。甚至有的书还在讲TruboC 2.0 之类的调试器!如此教材教出来的学生质量 可想而知。
三、指针和数组的定义与声明 1、定义为数组,声明为指针 文件1 中定义如下: char a[100]; 文件2 中声明如下(关于extern 的用法,以及定义和声明的区别,请复习第一章): extern char *a; 这里,文件1 中定义了数组a,文件2 中声明它为指针。这有什么问题吗?平时不是总说数组与指针相似,甚至可以通用吗?但是,很不幸,这是错误的。通过上面的分析我们也能明白一些,但是“革命尚未成功,同志仍需努力”。你或许还记得我上面说过的话:数组就是数组,指针就是指针,它们是完全不同的两码事!他们之间没有任何关系,只是经常穿着相似的衣服来迷惑你罢了。下面就来分析分析这个问题:
在第一章的开始,我就强调了定义和声明之间的区别,定义分配的内存,而声明没有。
定义只能出现一次,而声明可以出现多次。这里extern 告诉编译器a 这个名字已经在别的文件中被定义了,下面的代码使用的名字a 是别的文件定义的。再回顾到前面对于左值和右值的讨论,我们知道如果编译器需要某个地址(可能还需要加上偏移量)来执行某种操作的话,它就可以直接通过开锁动作(使用“*”这把钥匙)来读或者写这个地址上的内存,并不需要先去找到储存这个地址的地方。相反,对于指针而言,必须先去找到储存这个地址的地方,取出这个地址值然后对这个地址进行开锁(使用“*”这把钥匙)。如下图:
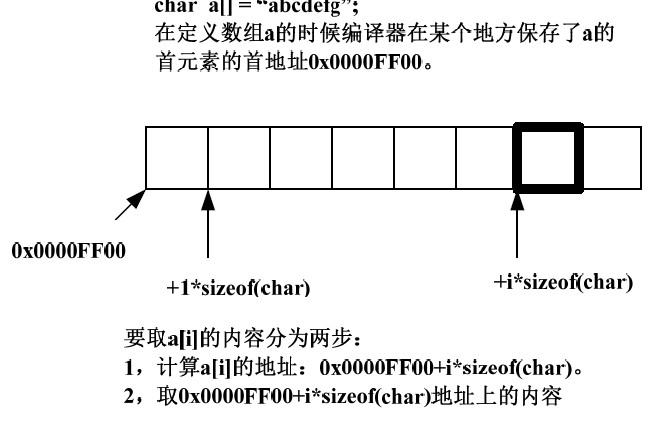
这就是为什么extern char a[]与extern char a[100]等价的原因。因为这只是声明,不分配空间,所以编译器无需知道这个数组有多少个元素。这两个声明都告诉编译器a 是在别的文件中被定义的一个数组,a 同时代表着数组a 的首元素的首地址,也就是这块内存的起始地址。数组内地任何元素的的地址都只需要知道这个地址就可以计算出来。
但是,当你声明为extern char *a 时,编译器理所当然的认为a 是一个指针变量,在32 位系统下,占4 个byte。这4 个byte 里保存了一个地址,这个地址上存的是字符类型数据。虽然在文件1 中,编译器知道a 是一个数组,但是在文件2 中,编译器并不知道这点。大多数编译器是按文件分别编译的,编译器只按照本文件中声明的类型来处理。所以,虽然a 实际大小为100 个byte,但是在文件2 中,编译器认为a 只占4 个byte。
我们说过,编译器会把存在指针变量中的任何数据当作地址来处理。所以,如果需要访问这些字符类型数据,我们必须先从指针变量a 中取出其保存的地址。如下图:

2、定义为指针,声明为数组 显然,按照上面的分析,我们把文件1 中定义的数组在文件2 中声明为指针会发生错误。
同样的,如果在文件1 中定义为指针,而在文件中声明为数组也会发生错误: 文件1 char *p = “abcdefg”; 文件2 extern char p[]; 在文件1 中,编译器分配4 个byte 空间,并命名为p。同时p 里保存了字符串常量“abcdefg”的首字符的首地址。这个字符串常量本身保存在内存的静态区,其内容不可更改。在文件2中,编译器认为p 是一个数组,其大小为4 个byte,数组内保存的是char 类型的数据。在文件2 中使用p 的过程如下图: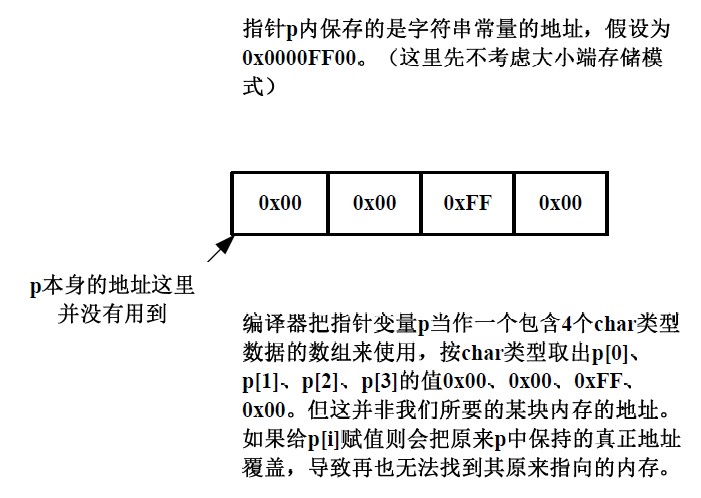
通过上面的分析,相信你已经知道数组与指针的的确确是两码事了。他们之间是不可以混淆的,但是我们可以“以XXXX 的形式”访问数组的元素或指针指向的内容。以后一定要确认你的代码在一个地方定义为指针,在别的地方也只能声明为指针;在一个的地方定义为数组,在别的地方也只能声明为数组。切记不可混淆。下面再用一个表来总结一下指针和数组的特性: