一、css与xpath对比

二、css
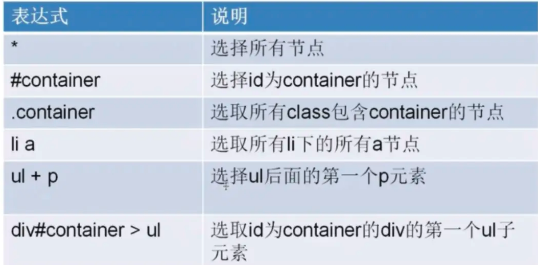
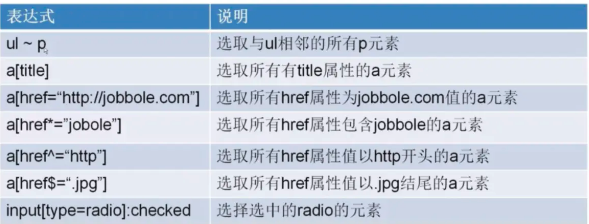

scrapy的选择器:以下样例的thml
<html> <head> <base href='http://example.com/' /> <title>Example website</title> </head> <body> <div id='images'> <a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> <a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> <a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> </div> </body> </html>
response.selector.xpath('//span/text()').get()
快捷方式:
response.css('span::text').get()
selector被省略掉,但是特殊时候,还是需要直接用selector,例如,不是request的到response,而是读取文本
>>> from scrapy.selector import Selector >>> body = '<html><body><span>good</span></body></html>' >>> Selector(text=body).xpath('//span/text()').get() 'good'
选择器使用的层次
1、 response.xpath() 和 response.css() 方法返回 SelectorList 实例,它是新选择器的列表
>>> response.xpath('//title/text()') 或者
>>> response.css('title::text')
[<Selector xpath='//title/text()' data='Example website'>,<Selector xxxx>]
2、提取文本,要用 get和getall.get()始终返回单个结果;如有多个,则取第一个,没有也不会报错,返回none,。.getall()返回包含所有结果的列表
>>> response.css('title::text').get()
'first'
>>> response.css('titlexxxxwtwrweewwddd::text').get(default='nofound')
'nofound'
>>> response.css('titlexxxxwtwrweewwddd::text').get()
None
>>> response.css('title::text').getall()
['first','second','xxxxx']
get() 约等于extract_first() ,getall() 约等于extract() ,extract是以前的用法,有缺陷,新版本scrapy不用extract了。
3、根据属性提取
>>> [img.attrib['src'] for img in response.css('img')] ['image1_thumb.jpg', 'image2_thumb.jpg', 'image3_thumb.jpg', 'image4_thumb.jpg', 'image5_thumb.jpg']
#attrib直接作为selectlist的提取方法,但只返回第一个匹配的值
>>> response.css('img').attrib['src']
'image1_thumb.jpg'
>>> response.css('base').attrib['href'] 'http://example.com/'
>>> response.css('base::attr(href)').get()
'http://example.com/'
>>> response.css('base').attrib['href']
'http://example.com/'
>>> response.css('a[href*=image]::attr(href)').getall()
['image1.html',
'image5.html']
>>> response.css('a[href*=image] img::attr(src)').getall()
['image1_thumb.jpg',
'image5_thumb.jpg']
4、scrapy对css选择器的扩展
标准的css选择器,是不能提取text的,也就是说会带着标签 <p><div>等tag
scrapy做了扩展:
- 选择文本,使用
::text - 选择属性值,使用
::attr(name)
>>> response.css('title::text').get() #get返回单个 'Example website'
>>> response.css('a::attr(href)').getall() #getall返回列表list ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
tmp1=Selector(text=html_text).css('title') tmp2 = Selector(text=html_text).css('title').get() tmp3=Selector(text=html_text).css('title::text') tmp4=Selector(text=html_text).css('title::text').get() print(tmp1) print(tmp2) print(tmp3) print(tmp4)
输出结果:
[<Selector xpath='descendant-or-self::title' data='<title>Example website</title>'>]
<title>Example website</title>
[<Selector xpath='descendant-or-self::title/text()' data='Example website'>]
Example website
总结:
css('tag')得到的是的 [selector list],里面有html标签; css('tag').get()可以得到HTML标签文本
css('tag::text')得到的是的 [selector list],里面去除了标签,只有text,css('tag::text').get()得到纯文本。
text可换成 attr(href)等属性,取得属性值
参考:https://www.osgeo.cn/scrapy/topics/selectors.html#selecting-attributes