提高db查询效率的函数
only(),
only()与values()的区别是:values只返回指定的field,而only一定会隐含id
defer()
1、查看query
str(User.objects.all().query)
2. And条件查询
以下4种查询,效果相同
qs1 = User.objects.filter(first_name="John", is_active=True)
qs2 = User.objects.filter(first_name="John").filter(is_active=True)
qs3 = User.objects.filter(first_name="John") & User.objects.filter(is_active=True)
qs4 = User.objects.filter(Q(first_name="John") & Q(is_active=True)
3、Or 或者条件查询
以下效果相同
qs1 = User.objects.filter(Q(first_name="John") | Q(first_name="Jane"))
qs2 = User.objects.filter(first_name="John") | User.objects.filter(first_name="Jane")
from django.db.models import Q qs = User.objects.filter(Q(first_name__startswith='R')|Q(last_name__startswith='D'))
4. 不等于 !=条件查询
以下效果相同
qs1 = User.objects.filter(~Q(first_name="John"))
qs2 = User.objects.exclude(first_name="John")
高端举例
queryset = User.objects.filter(~Q(id__lt=5))
5. 范围条件判断
qs = User.objects.filter(pk__in=[1, 4, 7])
6. Null空判断
qs = User.objects.filter(first_name__isnull=True)
qs = User.objects.filter(first_name__isnull=False)
7. 暧昧查询 like
% : 任意多个字符
_ : 一个字符
qs = User.objects.filter(first_name__startswith="Jo") 前匹配 Jo%
qs = User.objects.filter(last_name__endswith="yan") 后匹配 %yan
qs = User.objects.filter(last_name__contains="oh") 包含 或 中间匹配 %oh%
qs = User.objects.filter(last_name__regex=r"^D.e$") D_e (3个字符,前后固定,中间任意 例如 D1e Dxe等)
用法总结:startswith, istartswith, endswith, iendswith, contains, icontains, regex, iregex
8. 大、小 、>、<判断
s = User.objects.filter(id__gt=3) 大于
qs = User.objects.filter(id__lt=4) 小于
qs = User.objects.filter(id__lte=4) 小于等于
gte>=lte<=.
9. 范围条件判断 between
import pytz
from django.utils import timezone
start = timezone.make_aware(timezone.datetime(year=2019, month=1, day=1), pytz.utc)
end = timezone.make_aware(timezone.datetime(year=2019, month=12, day=31), pytz.utc)
qs = User.objects.filter(date_joined__range=[start, end])
10. 限制查询结果返回的数量
qs = User.objects.all()[:10]
等同于:
SELECT ... FROM "auth_user" LIMIT 10
10. 排序
qs = User.objects.order_by('date_joined', '-first_name')
等同于“
SELECT ... FROM "auth_user" ORDER BY "auth_user"."date_joined" ASC, "auth_user"."first_name" DESC
不区分大小写排序
>>> from django.db.models.functions import Lower
>>> User.objects.all().order_by(Lower('username')).values_list('username', flat=True)
<QuerySet ['Billy', 'John', 'johny', 'johny1', 'paul', 'Radha', 'Raghu', 'Ricky', 'rishab', 'Ritesh', 'sharukh', 'sohan', 'yash']>
也可以如下: 效果一样
User.objects.annotate(
uname=Lower('username')
).order_by('uname').values_list('username', flat=True)
跨表order by
class Category(models.Model): name = models.CharField(max_length=100) class Hero(models.Model): name = models.CharField(max_length=100) category = models.ForeignKey(Category, on_delete=models.CASCADE) Hero.objects.all().order_by( 'category__name', 'name' )
11.如何取得一个对象
qs = User.objects.all(), User.object.filter() 得到的不是single object instance, 而是queryset
得到一个对象有以下方法
User.objects.all()[0] 异常: 无数据 IndexError
User.objects.get(pk=1) 可能的异常:无数据 DoesNotExist exception 或者 多个数据 MultipleObjectsReturned exception
user = User.objects.order_by('first_name').last()
以下2个效果相同:
user = User.objects.order_by('date_joined', '-first_name').first()
和
try: user = User.objects.order_by('date_joined', '-first_name')[0] except IndexError: user = None
12 . 合并记录集 union
合并后仍然支持filter
q1 = User.objects.filter(id__gte=5) q2 = User.objects.filter(id__lte=9) q1.union(q2)
13. 不与外界数据比较,而是table不同列column之间的比较查询
查询: 前后姓名相等
User.objects.filter(last_name=F("first_name"))
#前后姓名,第一个字母相同
User.objects.annotate(first=Substr("first_name", 1, 1), last=Substr("last_name", 1, 1)).filter(first=F("last"))
F函数,可以用于model的计算函数,如Substr ,Fcan also be used with__gt,__ltand other expressions
14 . 查询文件 字段
A FileField or ImageField stores the path of the file or image. At the DB level they are same as a CharField.
no_files_objects = MyModel.objects.filter(
Q(file='')|Q(file=None)
)
15. 跨表查询 主表:reporter 明细表article, 也就是说,article有一个reportid是外键
a2 = Article.objects.filter(reporter__username='John')
16. 查询重复的数据
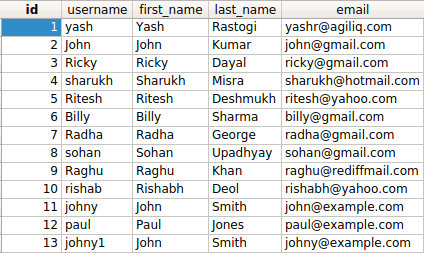
查询first_name重名的人
>>> duplicates = User.objects.values(
'first_name'
).annotate(name_count=Count('first_name')).filter(name_count__gt=1)
>>> duplicates
<QuerySet [{'first_name': 'John', 'name_count': 3}]>
列出重名的明细行
>>> records = User.objects.filter(first_name__in=[item['first_name'] for item in duplicates]) >>> print([item.id for item in records]) [2, 11, 13]
17. 按上图数据,查询distinct 'first_name'
distinct = User.objects.values( 'first_name' ).annotate( name_count=Count('first_name') ).filter(name_count=1) records = User.objects.filter(first_name__in=[item['first_name'] for item in distinct])
17.1 查询非重复数据 如:判断多少机构有学生? select distinct jg_id from Student
#正确写法
alljg=Student.objects.values_list('jg_id',flat=True).distinct()
#这种有写数据库不支持,sqlite不支持
alljg=Student.objects.distinct('jg_id')