1.背景

5.关键路径

目前收包存在的问题:
第一:inpterrupt livelock, 当收到包的时候,网卡驱动程序就会产生一次中断。在大流量的情况下,操作系统将花费大量时间用于处理中断,而只有
少量的时间用于其他任务。
第二:将包从网卡移动到用户层花费的时间太久。
2.PF_RING的目标
1. 充分利用 device polling 机制
2. 减少内核开销,开辟一条新的通道将收包从网卡传输到用户态
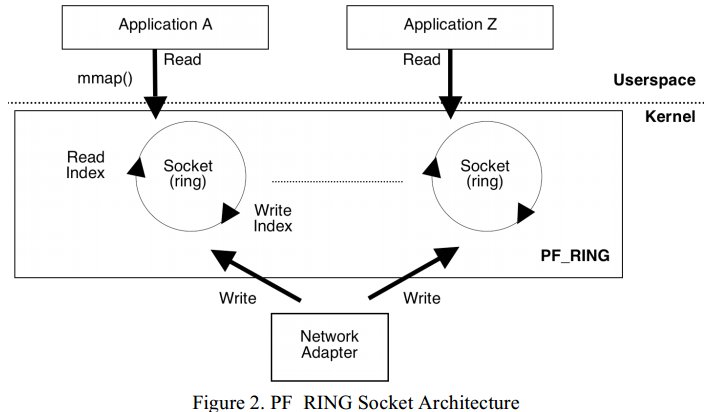
其架构图如下:
PF_RING实现功能如下:
1. 创建一种新的套接字类型 PF_RING, 用于将收包拷贝到一个环形缓冲区
2. 环形缓冲区和PF_RING套接字一同创建和销毁,各个缓冲区为套接字私有
3.如果一个网卡适配器被PF_RING套接字利用系统调用bind()绑定,这个网卡只能用于只读直到套接字销毁
4.对于PF_RING套接字,收包将会被拷贝到套接字缓冲区或被丢包
5.套接字缓冲区将会利用mmap功能
6.用户态程序通过mmap()系统调用访问套接字缓冲区
7.内核拷贝包到环形队列并移动写指针,用户态程序读包并移动读指针
8.新来的包将会覆盖原有包,因此不需要进行内存的分配和释放
9.套接字的缓冲区的长度和桶大小可被用户配置
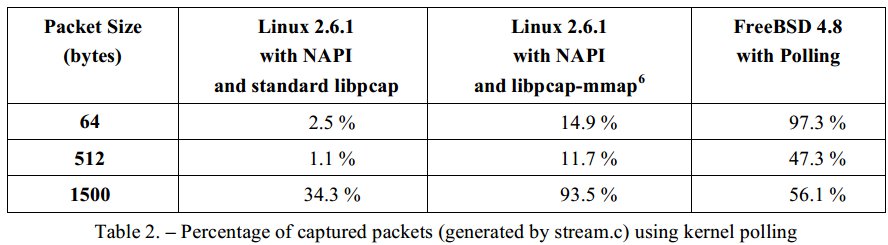
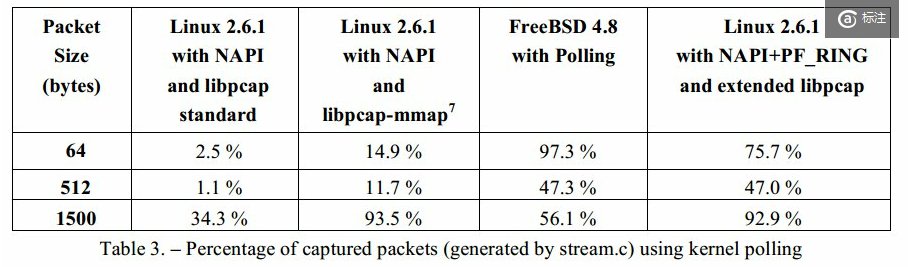
3.实验效果
使用PF_RING之前:
使用PF_RING之后:
以上依然有丢包主要是因为用户态程序阻塞在poll(),可通过内核补丁优化。
4.PF_RING 模式1和2的实现
处理流程图:
5.关键路径
函数igb_clean_rx_irq的内部实现:
第8080行函数nap_gro_receice实际上是一个宏:
#define napi_gro_receive(_napi, _skb) netif_receive_skb(_skb)
函数netif_receive_skb分析分组类型,以便根据分类类型将分组传递到网络层的接收函数,为此该函数遍历所有可能负责当前
分组类型的所有网络层函数,这样的话就将包发送至了内核协议栈。而第8075行的函数pf_ring_handle_skb函数将调用PF_RING的注册函数进行处理。
6.考虑方案
在函数igb_clean_rx_irq增加包过滤函数,UDP且端口53发送至PF_RING处理,而其余包走内核协议栈。
7.需要考虑的问题
- 修改网卡驱动且需要维护多个网卡驱动
- 性能上不一定能到达DPDK的效果,因为DPDK丢弃了无关包
- PF_RING的发包需要使用DNA技术,而此功能需要费用。如果不使用DNA,发包将会走协议栈
- PF_RING是否对驱动进行了优化
备注:DNA功能和普通PF_RING比较减少一次内存拷贝
8.待做实验
实验目的:验证模式0,1,2之间的差异
参考文献:
Improving Passive Packet Capture: Beyond Device Polling - Luca Deri