1.本周学习总结
1.1思维导图
1.2.对线性表的认识及学习体会
个人感觉线性表是一种用基础语言构造出来的一种常用算法,并不是来源于语言自身所带的。也就感觉是新学了一种算法。对于线性表的顺序储存结构的编程倒是没什么问题,但对于链式储存结构——链表编程题,虽然能够理解每个语句的意思以及它的逻辑结构,但是编程时不断的出现编程错误,接着就是段错误,而且函数的缺失,使代码无法在编译器内运行,很难找出错误,可谓是困难重重,个人认为还需要一段时间来加深对链表的理解。
2.PTA实验作业
2.1.题目1:
从顺序表中删除重复的元素,并使剩余元素间的相对次序保存不变。
输入格式:
第一行输入顺序表长度。 第二行输入顺序表数据元素。中间空格隔开。
输出格式:
数据之间空格隔开,最后一项尾部不带空格。
2.1.1设计思路
CreateSqList建立顺序表
定义i
顺序表L申请空间
L的长度置为n
for i=0 to n
L->data[i]=a[i] 顺序表置赋值
//此函数申请顺序表空间,将数组a[i]的值放入顺序表中
DelSameNode 删除重复数据
定义 i,j
定义 k=0
定义 len=0 新表的长度
定义 b[10]={0,0,0,0,0,0,0,0,0,0} 新表的赋值数组
for i=0 to L->length
b[L->data[i]]++ 将相应元素值放入数组b[i]中
for j=0 to 10
if b[j] 大于 0 如果b[j]>0,则将其下标的值放入新表中
{
L->data[k]=j 下标的值
k++
len++
}
L->length=len 将长度置为len
//主要是将每个数值当作新数组的下标,并对这个下标代表的值++,再对这个数组b[j]扫描,凡是大于0的则放入新表中,重构数组和顺序表,免去了复杂的数组a[i]删除操作
DispSqList 顺序表的输出
定义 i
for i=0 to L->length 循环输出顺序表
if i 等于 L->length-1
输出 L->data[L->length-1]
else
输出 L->data[i] 空格
//利用循环结构输出顺序表,在最后一个输出时控制一下空格问题
2.1.2代码截图


2.1.3本题PTA提交列表说明。

-
Q1:出现编译错误
-
A1:L=new SqList;语句出现问题,导致一开始顺序表L的申请就出错了
-
Q2:部分正确
-
A2:原因在定义的数组b[j]没有进行初始化为0,导致结果出现错误,反映了我对于未初始化的数组的掌握并不完全
2.2.题目2:
已知一个带有表头节点的单链表,查找链表中倒数第m个位置上的节点。
输入格式
先输入链表结点个数,再输入链表数据,再输入m表示倒数第m个位置。
输出格式
若能找到则输出相应位置,要是输入无效位置,则输出-1。
2.2.1设计思路
Finding 寻找导数m个数
LinkList p 定义一个结构体指针
定义 i k=0
p=L
while (L!=NULL) 得出整个链表的元素的个数
L=L->next
k++ 用k来计数
if k > m 能找到的情况下
{
for i=0 to k-m 直接找到倒数第m个数
p=p->next
if p不为空
return p->data
else
return -1
}
else
return -1
2.2.2代码截图


2.2.3本题PTA提交列表说明。

- Q1:答案部分正确
- A1:第一步的调整并无加入判断条件
 ,编程时想着能先把大结构写出来再进行调试
,编程时想着能先把大结构写出来再进行调试 - A2:因为第一步没有加入if语句的判断,自然没有else返回值,则答案还是部分正确
- A3:再进行修改,发现是for循环内的结点取值错误,会取到后面一个去了,进行修改至
2.3.题目3:
已知两个递增链表序列L1与L2,2个链表都是带头结点链表。设计函数实现L1,L2的合并,合并的链表仍然递增有序,头结点为L1的头结点。 合并后需要去除重复元素。
输入格式
输入分两行,先输入数据项个数,再输入数据项,数字用空格间隔。
输出格式
在一行中输出合并后新的递增链表,数字间用空格分开,结尾不能有多余空格。
2.3.1设计思路
MergeList 归并函数
{
定义结构体指针 pa=L1->next pb=L2->next r s;
r=L1 r指向L1
while(pa!=NULL&&pb!=NULL) 两个指针指向都不为空的时候
{
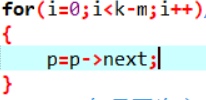
if (pa->data==pb->data) 两元素值都相等的时候,进行重复数据的判断
{
if (pa->next!=NULL) 判断哪个不是空的,不空的那个指针就往下移
指针 pa 往下移
else
指针 pb 往下移
}
if (pa->data<pb->data)
{
s申请空间
s->data=pa->data pa赋值给s
r->next=s 和r连接起来
r=s 将指针往下传递
pa指针往下移
}
else
{
s申请空间
s->data=pb->data;
r->next=s 指针间的连接
r=s;
pb指针往下移
}
}
接着扫描剩下的的长度
while(pa!=NULL)
{
s申请空间
s->data=pa->data;
r->next=s;
r=s;
pa指针往下移
}
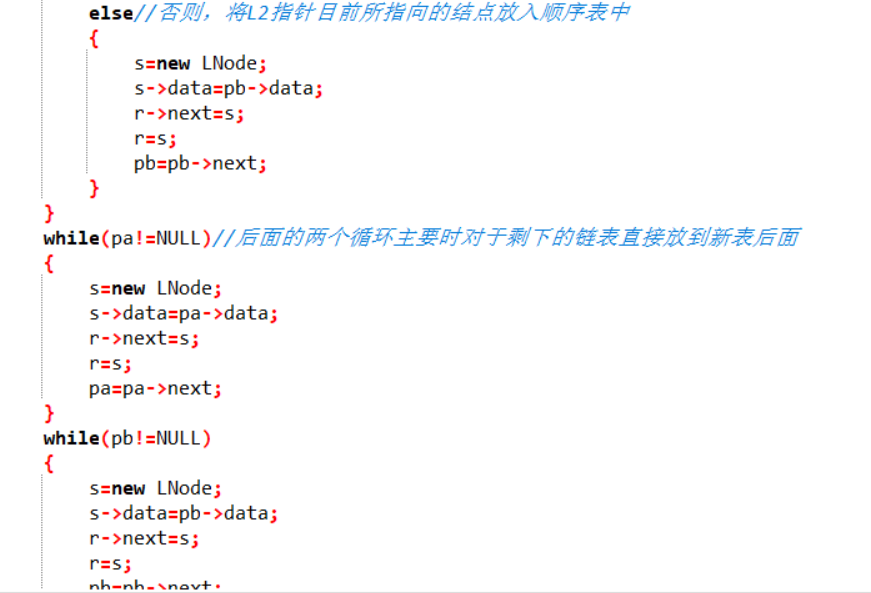
while(pb!=NULL)
{
s=new LNode;
s->data=pb->data;
r->next=s;
r=s;
pb=pb->next;
}
r的后续置为NULL
}
2.3.2代码截图

2.3.3本题PTA提交列表说明。

-
Q1:编译错误
-
A1:在判断重复数据的时候,把if条件放入判断不重复的数据的分支内
-
Q2:部分正确
-
A2:
 ,当其出现重复数据的时候,若只将pa指针往后移,则会出现空的状况,加入一个else语句使pb也能往后移
,当其出现重复数据的时候,若只将pa指针往后移,则会出现空的状况,加入一个else语句使pb也能往后移
3、阅读代码
3.1 题目
一个长度为L(L>=1)的升序序列S,处在第[L/2]个位置的数称为S的中位数。例如,若序列S1=(11,13,15,17,19),则S1的中位数是15。两个序列的中位数是含它们所有元素的升序序列的中位数。例如,若S2=(2,4,6,8,20),则S1和S2的中位数是11。现有两个等长的升序序列A和B,试设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列A和B的中位数。要求:
(1)给出算法的基本设计思想。
(2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
(3)说明你所设计计算法的时间复杂度和空间复杂度。
3.2 解题思路
此题思路主要是对于S1和S2两个序列的中位数的比较
(1)如果v1.data[mid1]==v2.data[mid2],则直接返回,它们的中位数相等。
(2)如果v1.data[mid1]<v2.data[mid2],则舍弃S1中比mid还要小的数(因为它们必不可能是中位数)。若序列数元素个数为偶数,则舍弃中位数前的元素;若序列元素个数是奇数,则舍弃包括中位数前的元 素以及中位数。同理,这时也要舍弃S2中较大的一半。
(3)如果v1.data[mid1]>v2.data[mid2],则舍弃S1中比mid大的数,同时也要舍弃S2中较小的一半,若序列元素个数为奇数则舍弃S2中位数的元素,若为偶数则舍弃包括中位数在内的元素。
3.3 代码截图

3.4 学习体会
此题为考研题,这个题目是找两个序列的中位数。可以说,这道题难度大倒是不大,但是算法的效率有大有小;我的第一直觉就是,先将两个序列合并,再用冒泡排序法排序,最后找出中位数。显而易见,这种算法效率不是最高的。而答案中的算法可以说是直接跳过两个序列合并,而且直接将中位数比较后的序列切去一半或者直接输出,大大提高算法效率;可以说,考研题的算法的确有种让人豁然开朗的感觉,一个思路的转变,就能够大大简化代码,只能说,算法之路,路漫漫其修远兮,吾将上下而求索。