scrapy框架:
下载页面;解析;并发,深度。
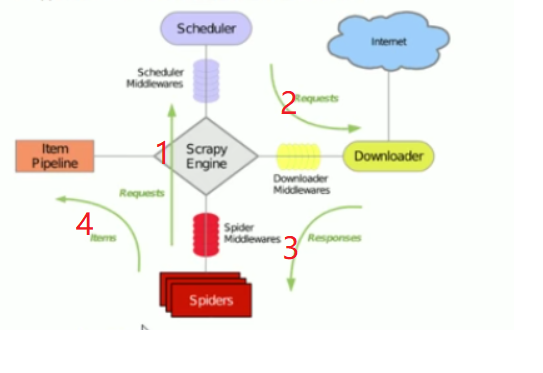
scrapy engine:相当于while循环,调用调度器的url。
scheduler(调度器):所以的url存储。
在实际中,只需要编写spiders即可。
使用scrapy:指定初始的url;
解析器响应内容
-给调度器
-给item,pipeline,用于格式化,持久化。(相当于导出数据)
例子:
在cmd中,scrapy startproject day5_21
cd day5_21
scrapy genspider chouti chouti.com
打开chouti.py进行编辑,
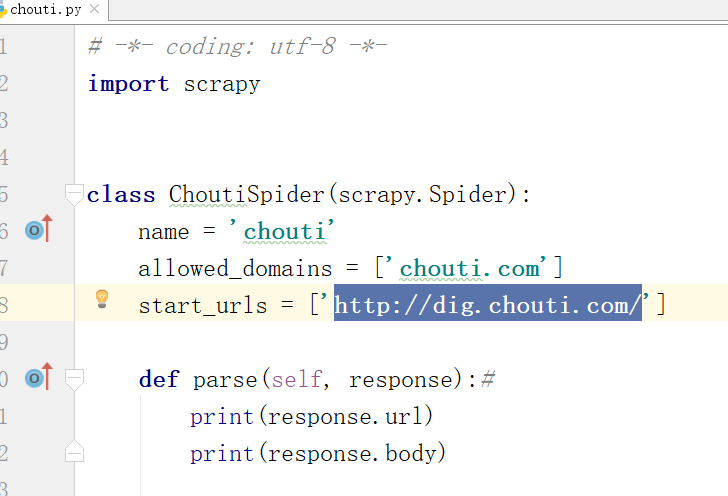
scrapy crawl chouti --nolog(scrapy -help)
没有运行出结果。