一、什么是Xpath
1、什么是xml
用来存储和传输数据的
2、xml和html的区别
(1)html是用来显示数据的,xml是用来传输数据的
(2)html标签是固定的,xml标签是自定义的
(3)html可以理解为属于xml
3、Xpath定义
用来在xml中查找指定的元素,是一种路径表达式,根据路径表达式可以找到你想要的指定内容。
4、Xpath常用的路径表达式
(1)//:不考虑位置的查找,从任意位置开始查找
(2)./:从当前节点开始往下查找
(3)@:选取属性
(4)实例
1⃣️/bookstore/book:选取根节点bookstore下面的所有book
2⃣️//book:选取所有的book,任意位置的
3⃣️bookstore//book:查找bookstrore下面所有的book,包括子节点/孙子节点....
4⃣️/bookstore/book[1]:查找bookstore下面的第一个book
5⃣️/bookstore/book[last()]:查找bookstore下面的最后一个book
6⃣️/bookstore/book[position()<3]:查找bookstore下面的前两个book
7⃣️//title[@lang]:查找所有lang属性的title
8⃣️//title[@lang='eng']:查找所有的lang值等于eng的title
9⃣️*:匹配任何元素节点
二、Xpath使用
1、首先需要下载安装xpath插件到谷歌浏览器(xpath.crx)
xpath.crx下载下来之后直接拖到谷歌浏览器扩展程序里面即可。
下载链接:https://chromecj.com/downloadstart.html#2170
如下图则表示安装成功,黑色的框可以通过快捷键crtl+shift+x开启/关闭xpath

说明:黑色的框中左边为路径表达式,右边为结果,当左边写对时,右边才展示结果。
2、xpath定位元素的方法(以百度为例演示)
(1)属性定位(定位百度首页输入框,通过属性id或者class)
A、通过id定位
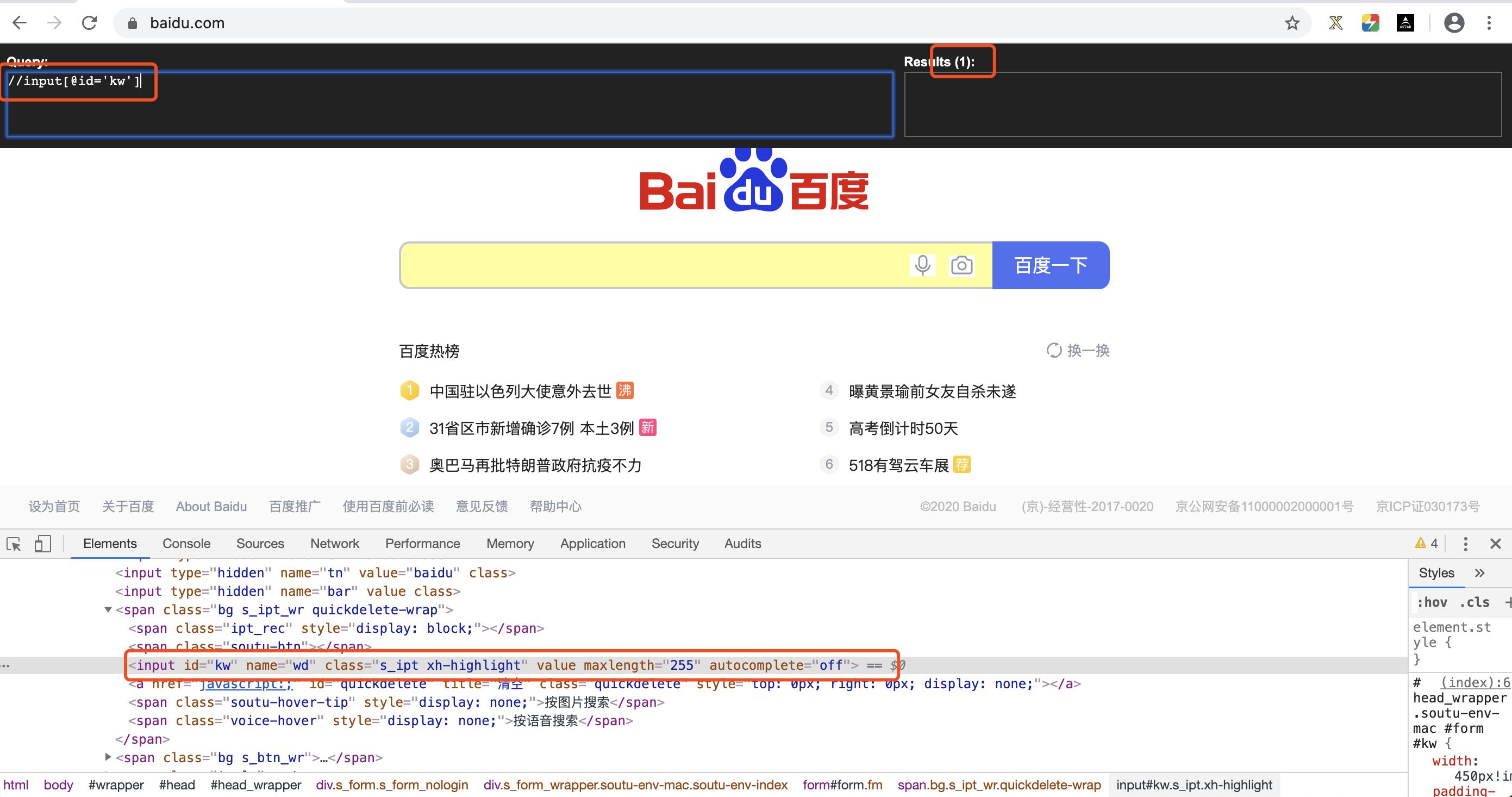
B、通过class定位

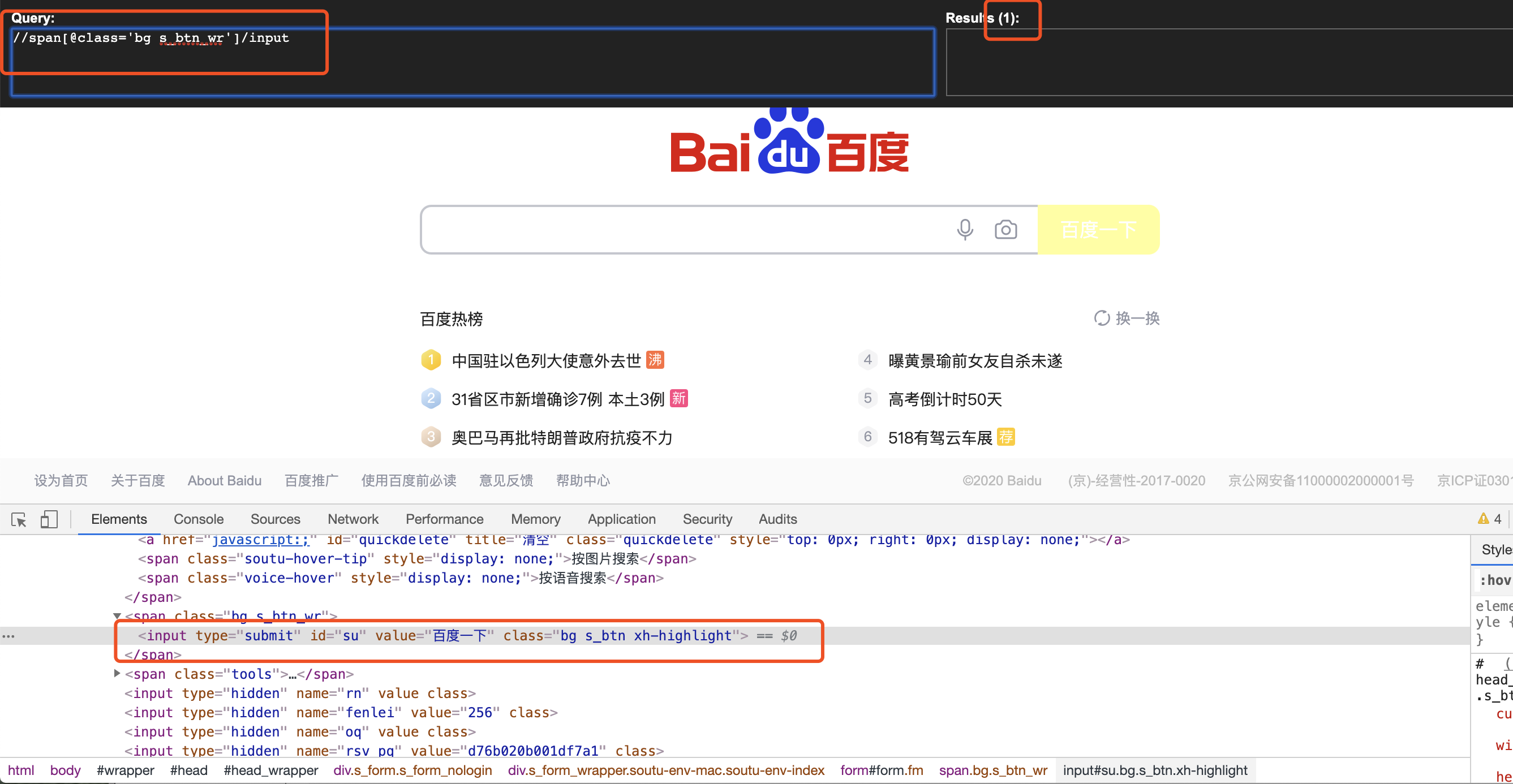
(2)层级定位(定位‘百度一下’按钮)
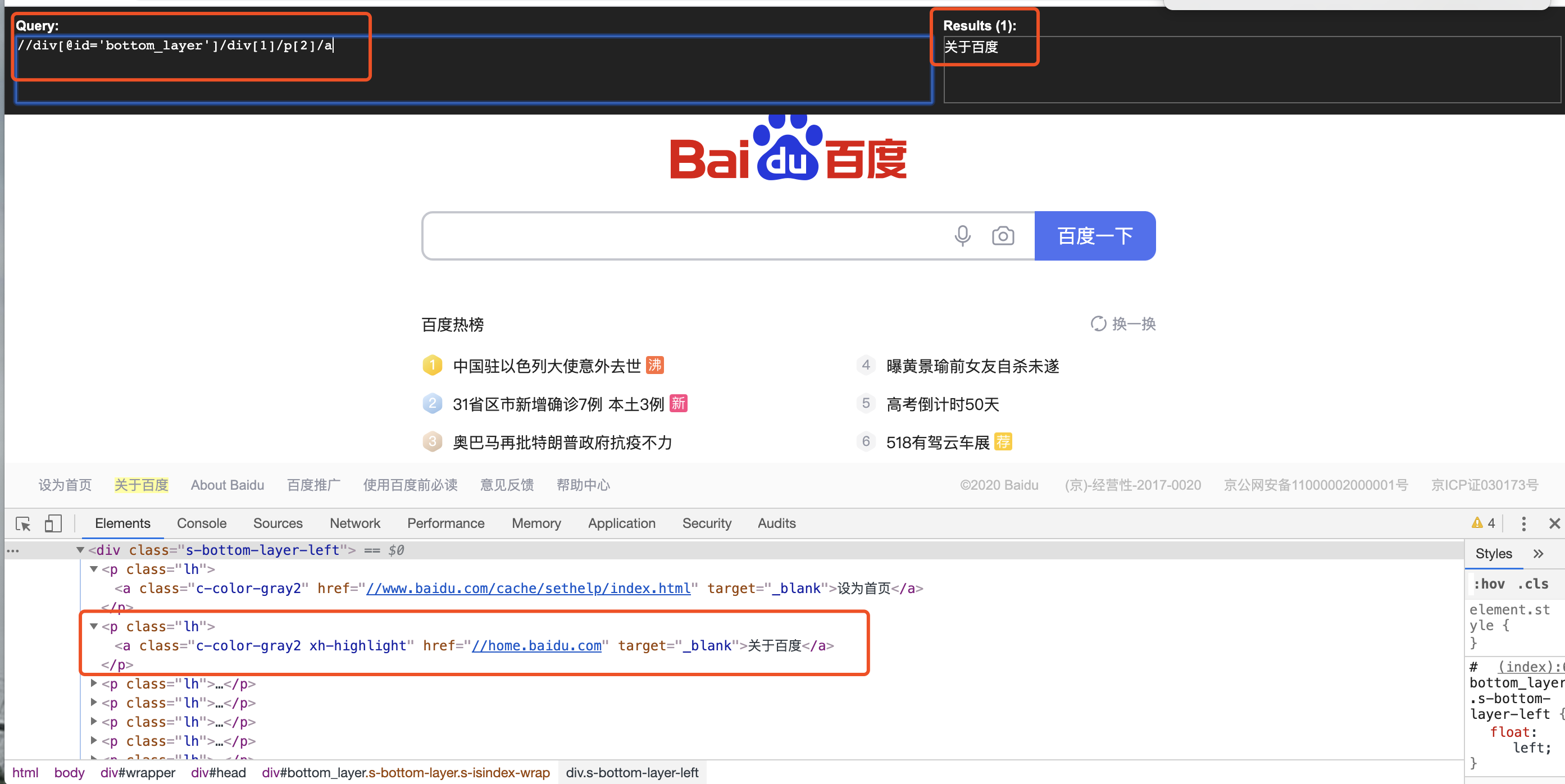
(3)索引定位(定位‘关于百度’)
注意:索引从1开始,不是0
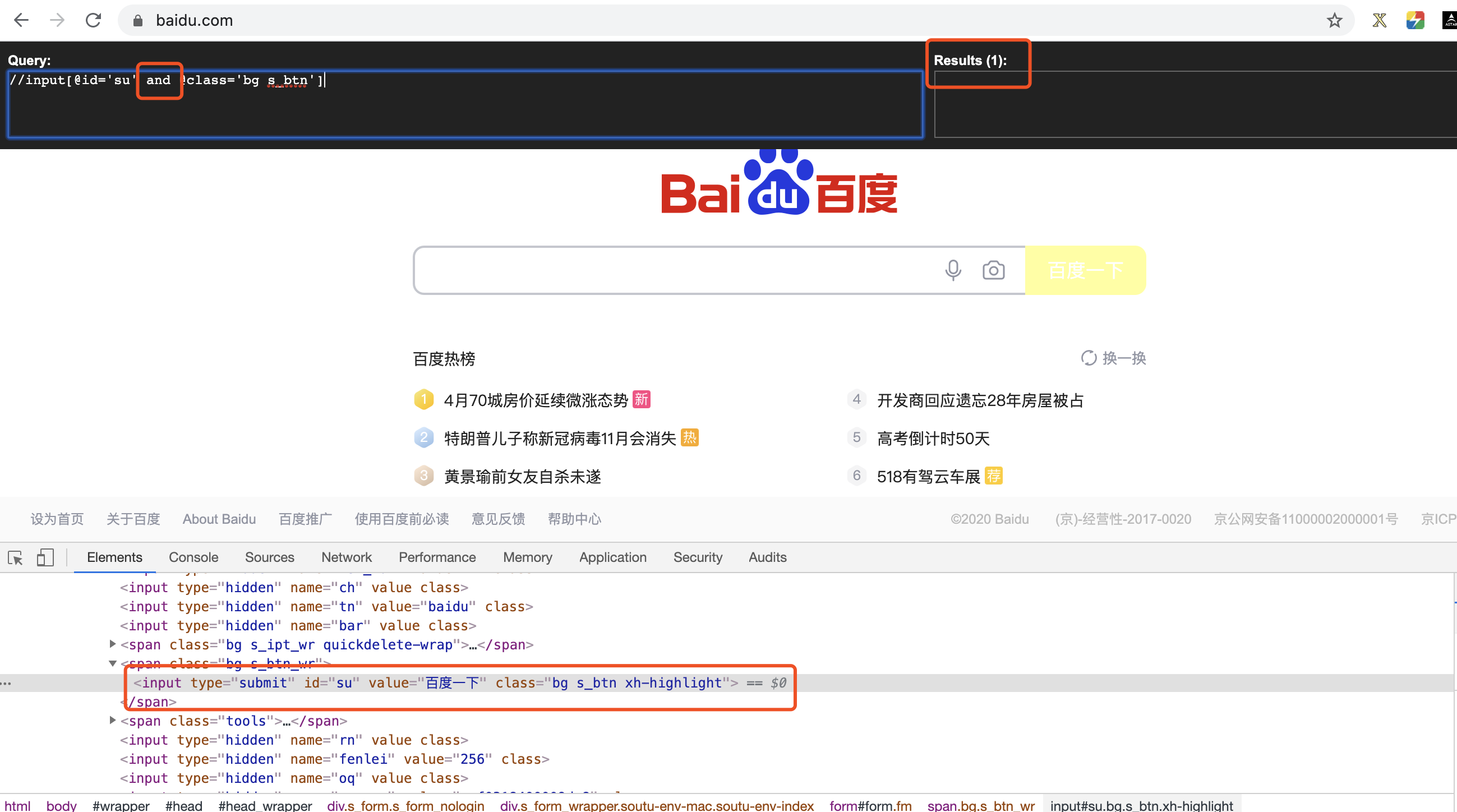
(4)逻辑运算(定位‘百度一下’)
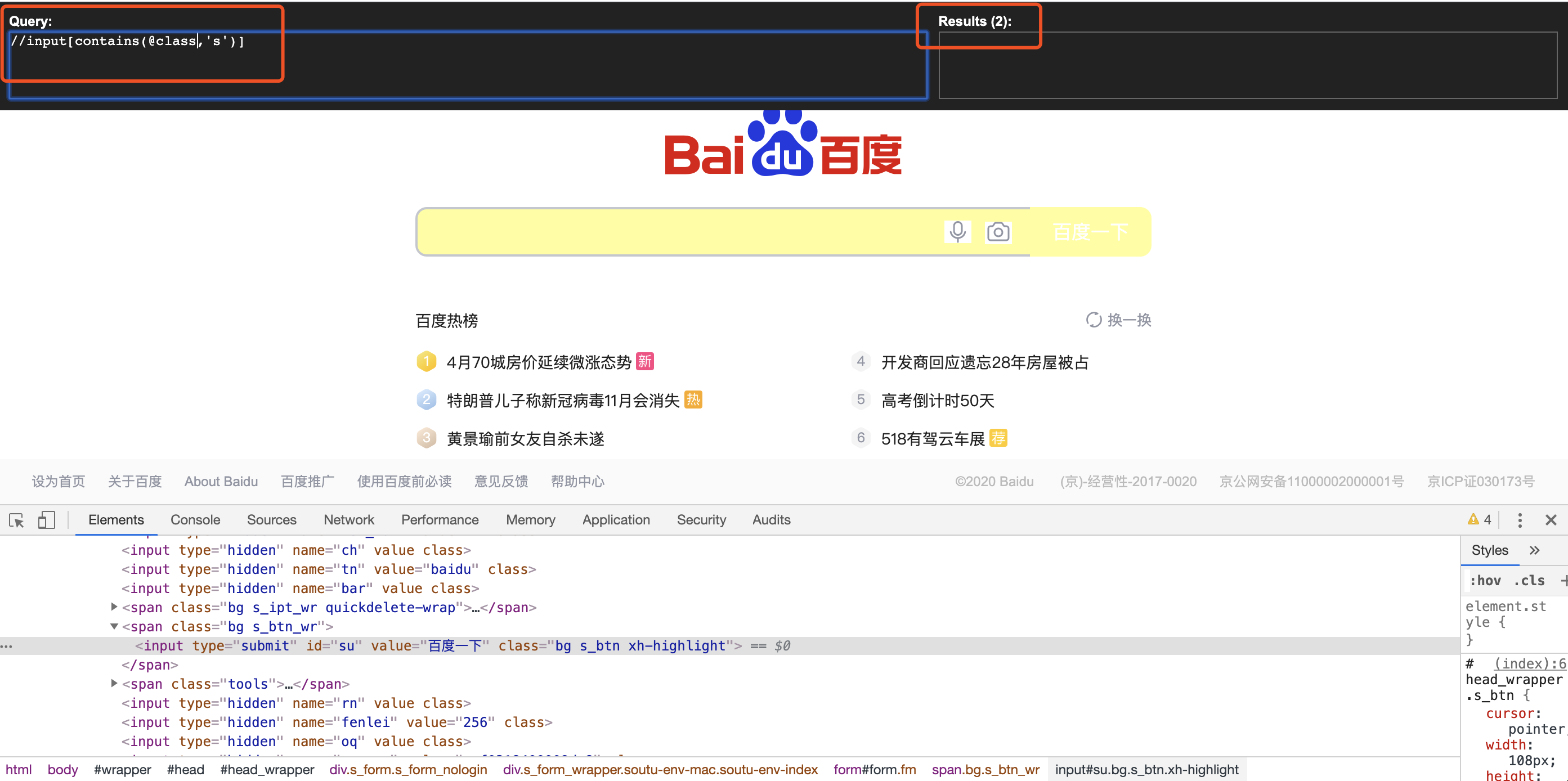
(5)模糊搜索
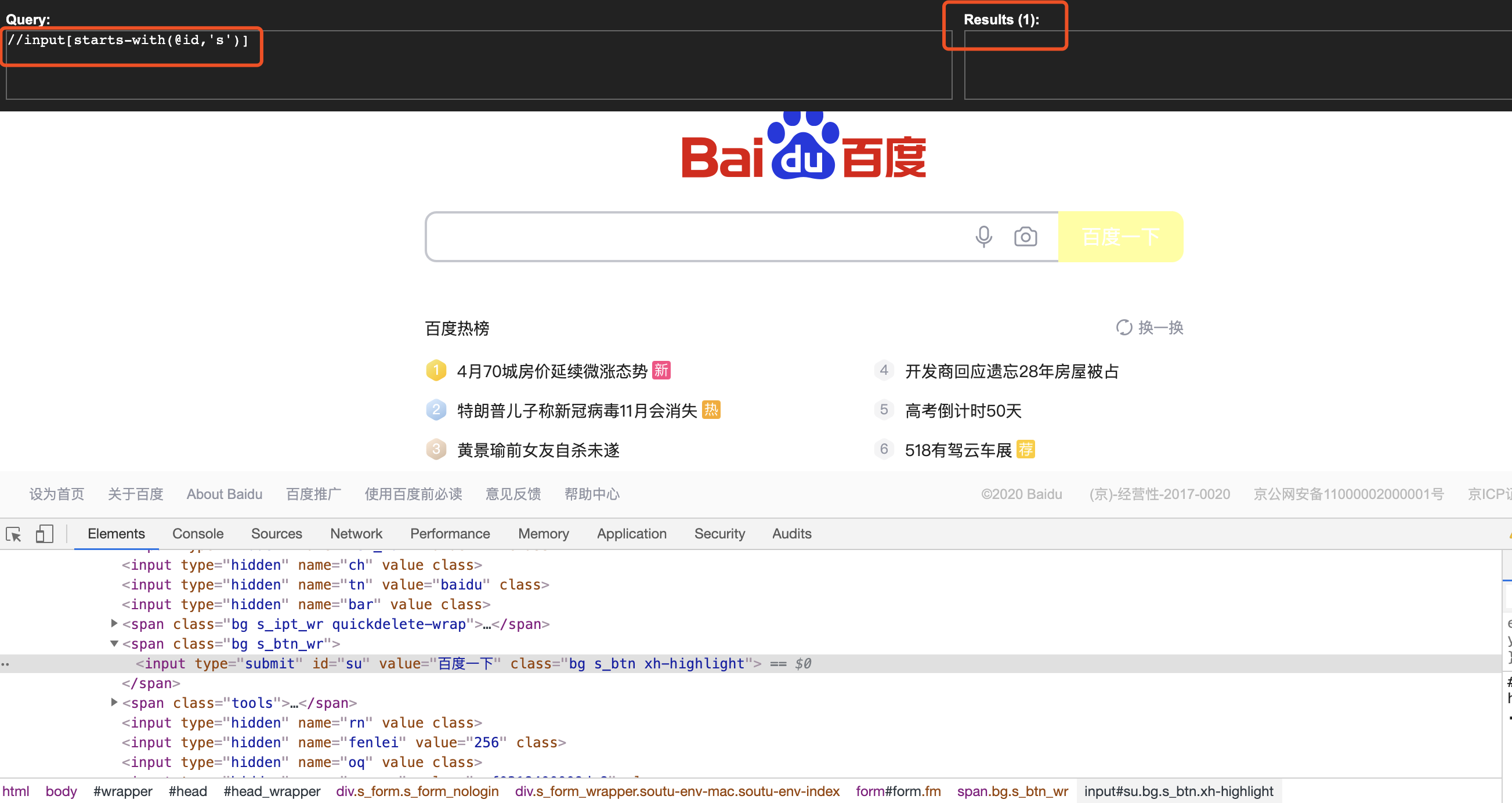
A、contains(定位input标签中,class以s开头的元素,id也同样)
B、starts_with(定位input标签中id以s开头的元素)
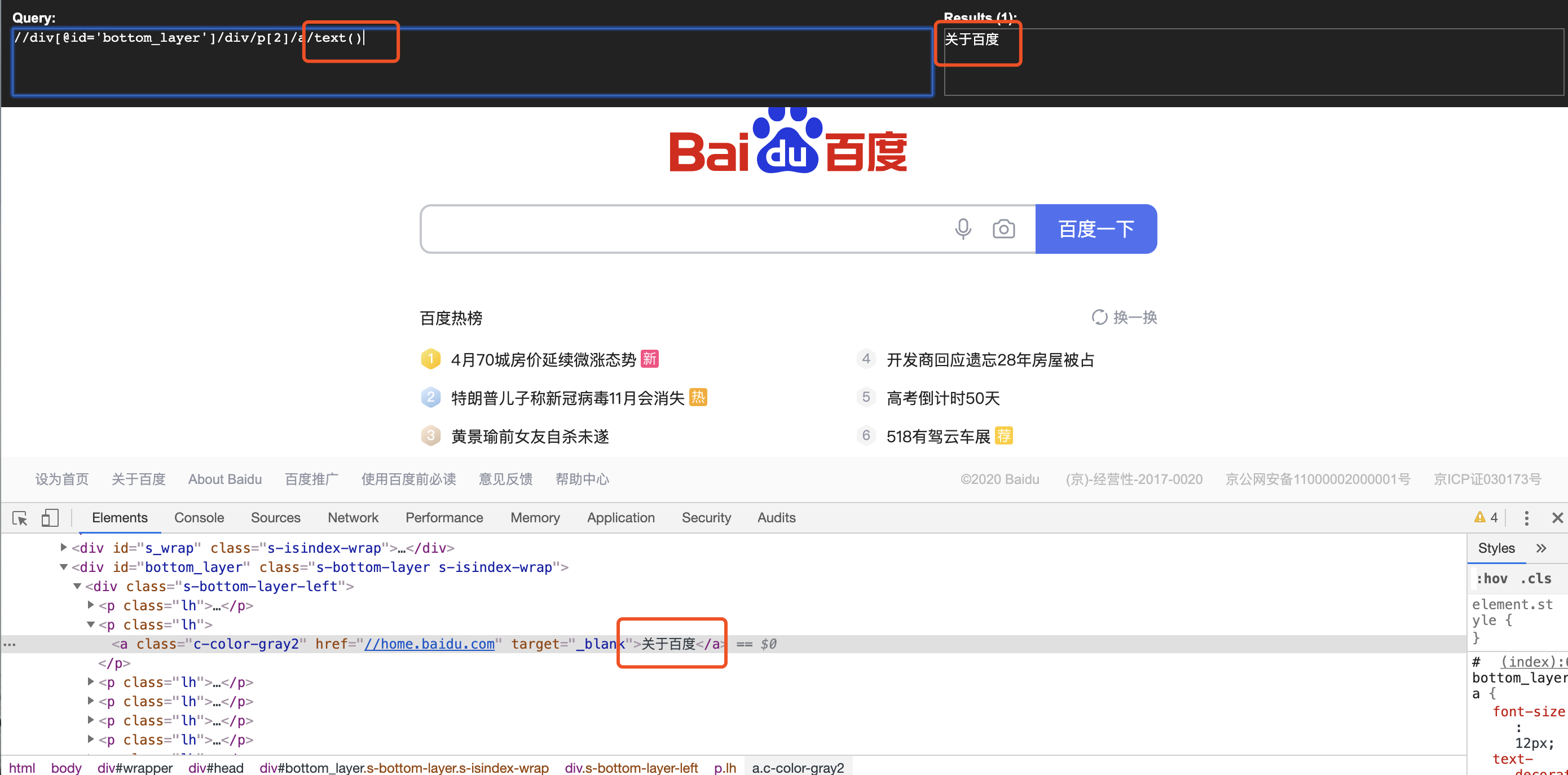
(6)取文本(获取关于百度的文本内容)
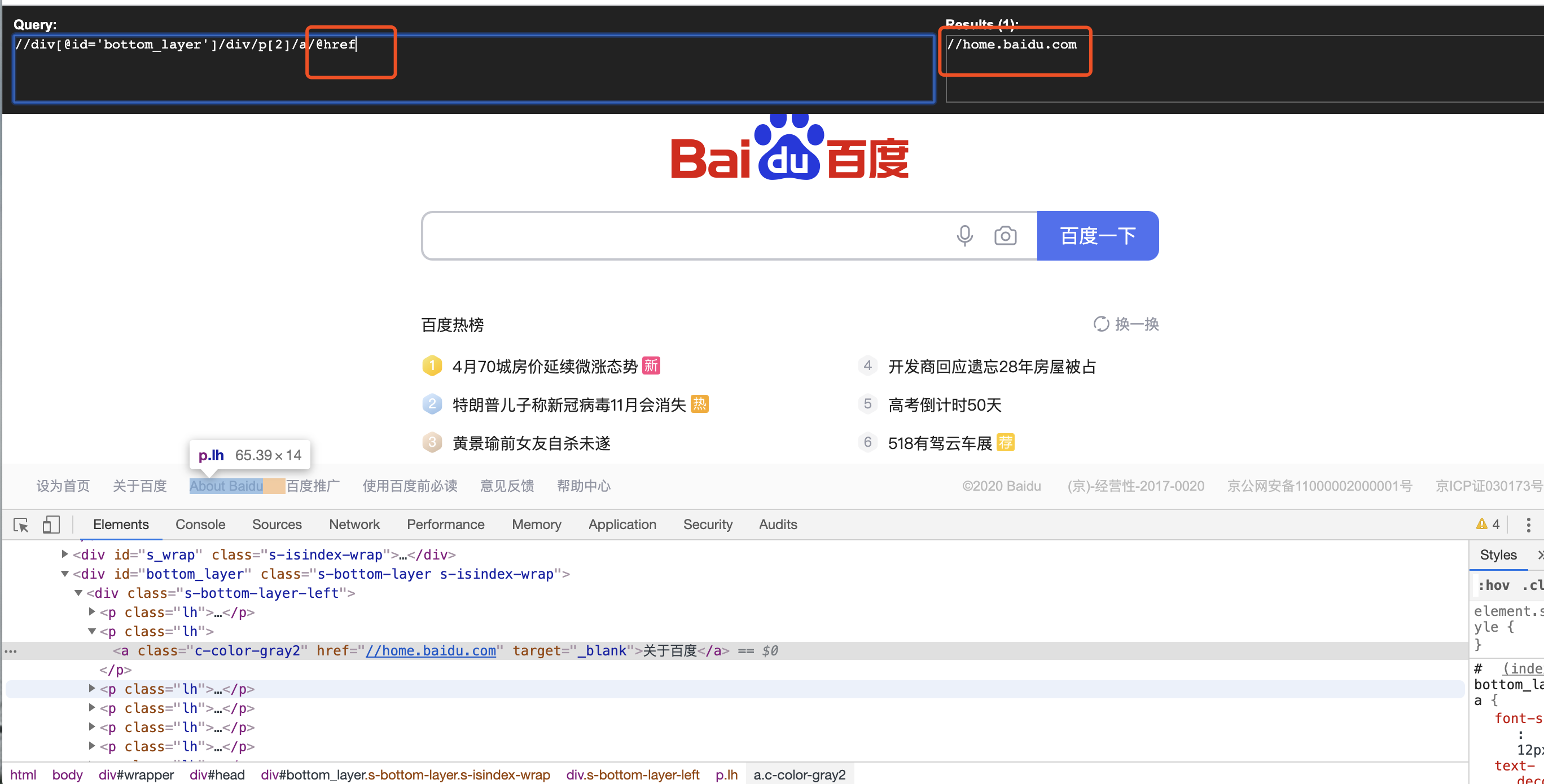
(7)取属性(获取关于百度a标签的href属性,class/id,同样的写@class/@id)
(8)获取所有div下面的文本内容
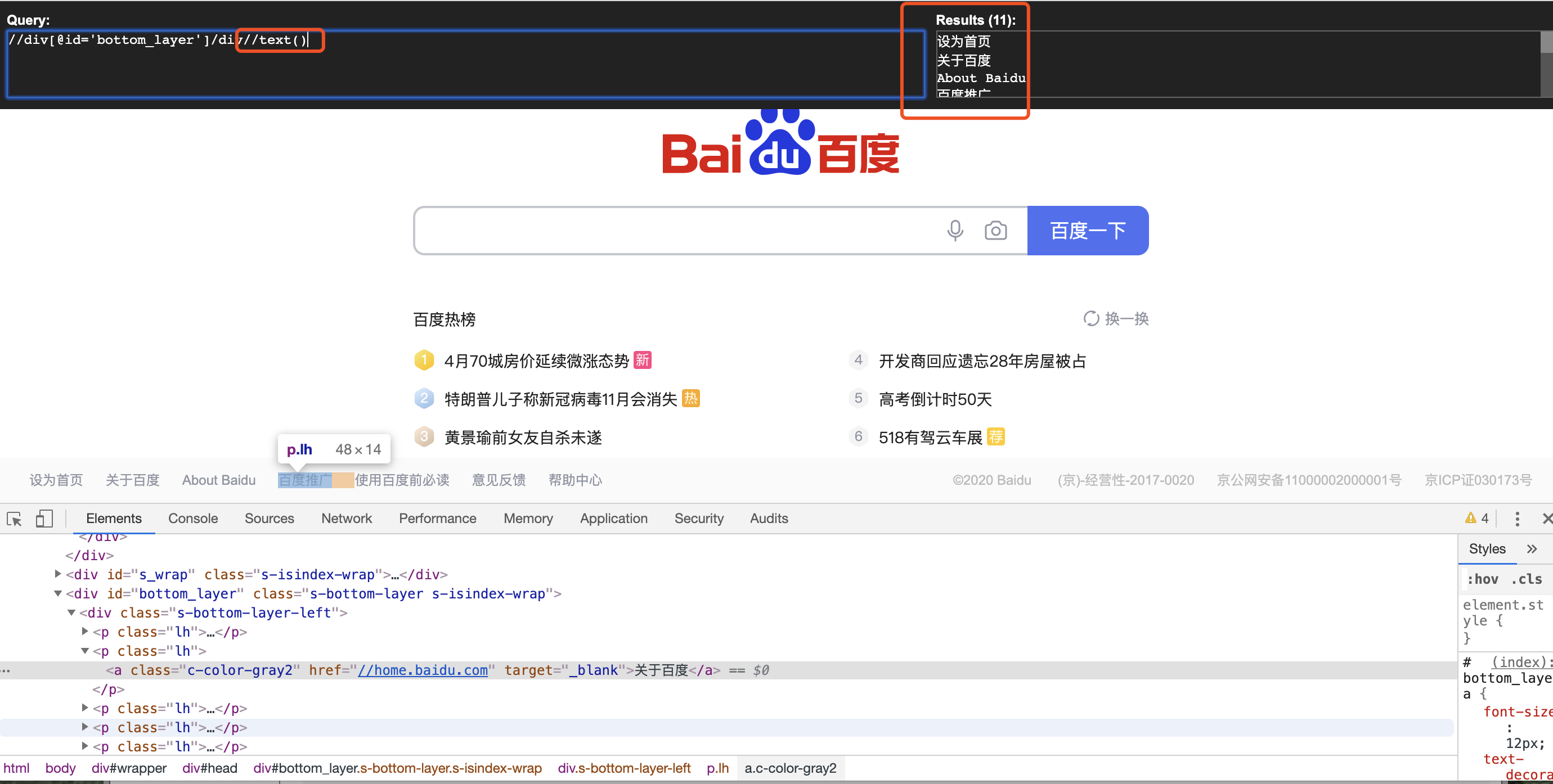
三、实例
xpath_exam.py
#!/usr/local/bin/python3.7 from lxml import etree # 创建对象 tree = etree.parse('Reptile/xpath.html') # print(tree) # 定位元素‘千山鸟飞绝’ ret = tree.xpath("//div[@class='tangshi']/ul/li[1]") print(ret) # 定位元素‘孤舟蓑笠翁’ ret1 = tree.xpath("//div[@class='tangshi']/ul/li[@id='gu' and @class='zhou']") print(ret1) # 定位a标签中的内容 ret2 = tree.xpath("//div[@class='tangshi']/ul/li[8]/a/text()") print(ret2[0]) # 定位诗句中包含‘一’字的诗句 ret3 = tree.xpath("//div/ul/li[contains(text(),'一')]/text()") print(ret3) # 定位诗句中以‘千’开头的诗句 ret4 = tree.xpath("//div/ul/li[starts-with(text(),'千')]/text()") print(ret4) # 定位a标签的href属性 ret5 = tree.xpath("//div[@class='tangshi']/ul/li[8]/a/@href") print(ret5[0]) # 连接内容 ret5 = tree.xpath("//div[@class='shiren']") string = ret5[0].xpath('string(.)') print(string) print(string.replace(' ', '').replace(' ', ''))
xpath.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <div class="tangshi"> <ul> <li class="qian" id="gu">千山鸟飞绝</li> <li class="wan">万径人踪灭</li> <li id="gu" class="zhou">孤舟蓑笠翁</li> <li class="zhou" name='chongfu'>重复上一句</li> <li class="yi">一曲新词酒一杯</li> <li id="qu">去年天气旧池台</li> <li id="du">独钓寒江雪</li> <li><a href="https://www.baidu.com">百度一下</a></li> <li class="qian" id="san">千金散尽还复来</li> </ul> </div> <div class="songci"> <ul> <li class="bo">薄雾浓云愁永昼</li> <li id="rui">瑞脑消金兽</li> <li id="jia">佳节又重阳</li> <li class="yu">玉枕纱橱</li> <li id="ban">半夜凉初透</li> </ul> </div> </body> </html>