static的作用:
1.第一条也是最重要的一条:隐藏
当我们同时编译多个文件时,所有未加static前缀的全局变量和函数都具有全局可见性。如果加了static,就会对其它源文件隐藏。例如在a和msg的定义前加上static,main.c就看不到它们了。利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。Static可以用作函数和变量的前缀,对于函数来讲,static的作用仅限于隐藏
2.static的第二个作用是保持变量内容的持久
3.static的第三个作用是默认初始化为0
虚函数,具体怎么实现
https://blog.csdn.net/weixin_40237626/article/details/82313339
指针和引用的区别:
内存分配:指针是一个实体,需要分配内存空间。引用只是变量的别名,不需要分配内存空间。
初始化:引用在定义的时候必须进行初始化,并且不能够改变。指针在定义的时候不一定要初始化,并且指向的空间可变。
使用级别:有多级指针,但是没有多级引用,只能一级引用。
自增运算:指针和引用的自增运算结果不一样。(指针是指向下一个空间,引用时引用的变量值加1)
使用sizeof时:引用得到的是所指向的变量(对象)的大小,而sizeof 指针得到的是指针本身的大小。
直接与间接访问:引用访问一个变量是直接访问,而指针访问一个变量是间接访问。
野指针:使用指针前最好做类型检查,防止野指针的出现;
参数传递:作为参数时,传指针的实质是传值,传递的值是指针的地址;传引用的实质是传地址,传递的是变量的地址。
new能free么
不可以,new对应delete不可以张冠李戴。
malloc/free,new/delete必需配对使用。
malloc与free是c++、c语言的标准库函数,new、delete是c++的运算符。它们都可用用申请动态内存和释放内存。对于非内部数据类型的对象而言,光用malloc/free无法满足动态对象的要求。对象在创建的同时要自动执行函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。因此c++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
malloc,free和new,delete的区别
C/C++生成可执行文件过程
编译的概念:编译程序读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,再由汇编程序转换为机器语言,并且按照操作系统对可执行文件格式的要求链接生成可执行程序。
编译的完整过程:C源程序-->预编译处理(.c)-->编译、优化程序(.asm、.s)-->汇编程序(.obj、.o、.a)-->链接程序(.exe等可执行文件)
1. 编译预处理(Preprocess)
读取C源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理。主要包括四类:宏定义、条件编译指令、头文件和特殊符号。
预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。
2. 编译、优化阶段(Compile)
经过预编译得到的输出文件中,只有常量;如数字、字符串、变量的定义,以及C语言的关键字,如main,if,else,for,while,{,}, +,-,*,/等等。
编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放的有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
经过优化得到的汇编代码必须经过汇编程序的汇编转换成相应的机器指令,方可能被机器执行。
3. 汇编过程(Assemble)
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。
目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
Win32平台上一般生成.obj文件,其拥有PE(Portable Executable,即Windows可执行文件)文件格式,包含的是二进制代码,但是不一定能执行。当编译器将一个工程里的所有.cpp文件以分离的方式编译完毕后,再由链接器进行链接成为一个.exe或.dll文件。
4. 链接程序(Link)
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。
例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够诶操作系统装入执行的统一整体。
根据开发人员指定的同库函数的链接方式的不同,链接处理
可分为两种:
(1)静态链接
在这种链接方式下,函数的代码将从其所在地静态链接库中被拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
(2)动态链接
在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其它少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比使用静态链接要优越。在某些情况下动态链接可能带来一些性能上损害。
多进程与多线程的选择
https://blog.csdn.net/q_l_s/article/details/52608734
1)需要频繁创建销毁的优先用线程
2)需要进行大量计算的优先使用线程
所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。
游戏服务器TCP与UDP的抉择
https://blog.csdn.net/w00w12l/article/details/45077821
https://www.zhihu.com/question/23356564
TCP的特点:
从原理上,TCP的优势有:
- 简单直接的长连接
- 可靠的信息传输
- 数据包的大小没有限制
TCP最糟糕的特性是它对阻塞的控制。一般来说,TCP假定丢包是由于网络带宽不够造成的,所以发生这种情况的时候,TCP就会减少发包速度。
在3G或WiFi下,一个数据包丢失了,你希望的是立马重发这个数据包,然而TCP的阻塞机制却完全是采用相反的方式来处理!
而且没有任何办法能够绕过这个机制,因为这是TCP协议构建的基础。这就是为什么在3G或者WiFi环境下,ping值能够上升到1000多毫秒的原因。
UDP的特点:
UDP相对TCP来说既简单又困难。
举个例子来说,UDP是基于数据包构建,这意味着在某些方面需要你完全颠覆在TCP下的观念。UDP只使用一个socket进行通信,不像TCP需要为每一个客户端建立一个socket连接。这些都是UDP非常不错的地方。
但是,大多数情况下你需要的仅仅是一些连接的概念罢了,一些基本的包序功能,以及所谓的连接可靠性。可惜的是,这些功能UDP都没有办法简单的提供给你,而你使用TCP却都可以免费得到。
使用TCP失败的地方:
可靠的UDP也是有延迟的,但是由于它是在UDP的基础之上建立的通信协议,所以可以通过多种方式来减少延迟,不像TCP,所有的东西都要依赖于TCP协议本身而无法被更改。
魔兽世界以及其他的一些游戏是怎么处理延迟问题的呢?
一些类似发起攻击动作和释放技能特效就能够在没有收到服务器确认的情况下就直接执行,比如展现冰冻技能的效果就可以在服务器没有返回数据前在客户端就做出来。
客户端直接开始进行计算而不等待服务端确认是一种典型的隐藏延迟的技术。
这也意味着,我们到底是使用TCP还是UDP取决于我们能否隐藏延迟。
TCP在什么时候失效
一个采用TCP的游戏必须能够处理好突发的延迟问题(纸牌客户端就很典型,对突发性的一秒的延迟,玩家也不会产生什么抱怨)或者是拥有缓解延迟问题的好方法。
如果你运行的是一个无法使用任何减缓延迟措施的游戏呢?玩家对玩家的动作类游戏通常就属于这个范畴,但是这也不仅仅限于动作类游戏。
一种常见的操作是,你快速的移动你的角色通过一张充满战争迷雾的世界地图,但是一旦你探索过,迷雾就会被打开。
为了确保游戏的规则,防止玩家作弊,服务器只能显示玩家当前位置附近的信息。这意味着不像魔兽世界,玩家无法在没有得到服务器响应的情况下,做出完整的动作。战争迷雾的探开必须依靠服务器传过来的响应。
而当出现丢包时,由于拥塞控制的原因,服务器的响应速度就从100-150毫秒上升到1000-2000毫秒
没有任何办法可以绕过TCP的这个设置来避开这个问题。
我们替换了TCP的代码,用了自定义的可靠的UDP来实现,把大量的丢包产生的延迟降到了仅仅只有50毫秒,甚至比以前TCP不丢包的情况一个来回的延迟还要小。当然,这只可能建立在UDP之上,这样我们才对可靠性拥有完全的掌控力。
可靠的UDP一点也不像TCP,要去实现一个特殊的阻塞控制。事实上,这也是你使用可靠UDP代替TCP的最大的原因,避免TCP的阻塞控制。
底线
那么到底是用UDP还是TCP呢?
- 如果是由客户端间歇性的发起无状态的查询,并且偶尔发生延迟是可以容忍,那么使用HTTP/HTTPS吧。
- 如果客户端和服务器都可以独立发包,但是偶尔发生延迟可以容忍(比如:在线的纸牌游戏,许多MMO类的游戏),那么使用TCP长连接吧。
- 如果客户端和服务器都可以独立发包,而且无法忍受延迟(比如:大多数的多人动作类游戏,一些MMO类游戏),那么使用UDP吧。
死锁条件?怎么解决?具体形容一下怎么个情况是死锁
必要条件
互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
占有和等待:已经得到了某个资源的进程可以再请求新的资源。
不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
处理方法
主要有以下四种方法:
鸵鸟策略
死锁检测与死锁恢复
死锁预防
死锁避免
select、poll、epoll
HTTP1.0与HTTP1.1的区别
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
-
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
HTTP2.0
HTTP/1.x 缺陷
HTTP/1.x 实现简单是以牺牲性能为代价的:
客户端需要使用多个连接才能实现并发和缩短延迟;
不会压缩请求和响应首部,从而导致不必要的网络流量;
不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
HTTP2.0与HTTP1.x的区别:
1.二进制分帧层
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧(一个报文拆分成两部分分别传送),它们都是二进制格式的,HTTP1.x的解析是基于文本。。
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
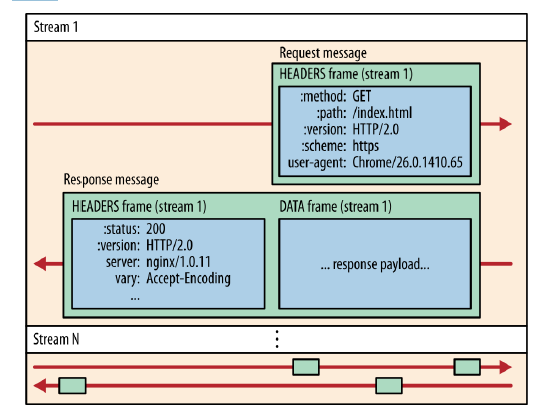
2.服务端推送
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
3.首部压缩
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
HTTPS
HTTP 有以下安全性问题:
使用明文进行通信,内容可能会被窃听;
不验证通信方的身份,通信方的身份有可能遭遇伪装;
无法证明报文的完整性,报文有可能遭篡改。
加密:
1. 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
优点:运算速度快;
缺点:无法安全地将密钥传输给通信方。
2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
优点:可以更安全地将公开密钥传输给通信发送方;
缺点:运算速度慢。
真正使用时,实际上是先用发送方得到接收方非对称密钥加密的公开密钥,然后用这个公开密钥将其对称密钥进行加密,接受方收到后解密得到对称密钥,之后就以这个对称密钥进行通信。

认证
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
首先看为什么要认证?
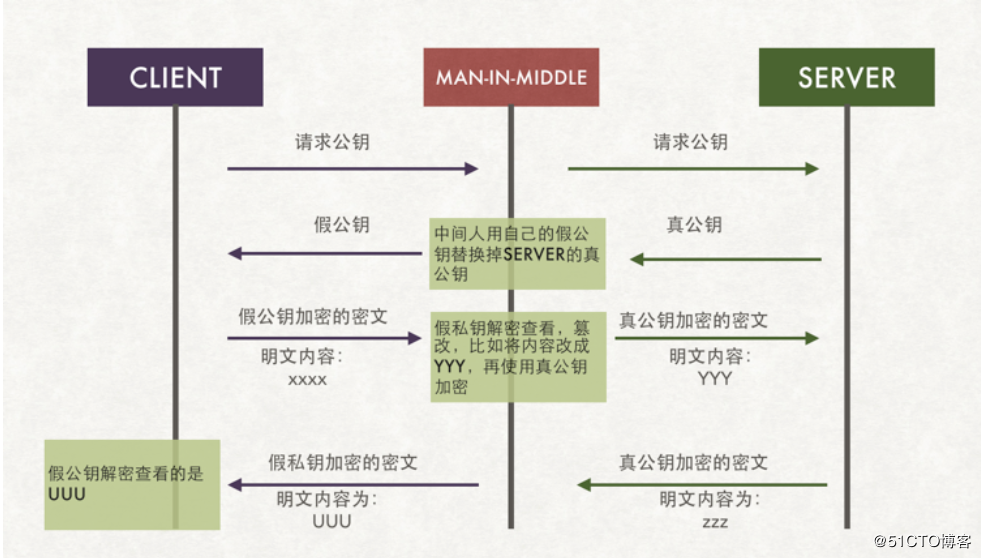
细心的人可能已经注意到了如果使用非对称加密算法,我们的客户端A,B需要一开始就持有公钥,要不没法开展加密行为啊。
这下,我们又遇到新问题了,如何让A、B客户端安全地得到公钥?
client获取公钥最最直接的方法是服务器端server将公钥发送给每一个client用户,但这个时候就出现了公钥被劫持的问题,如上图,client请求公钥,在请求返回的过程中被×××劫持,那么我们将采用劫持后的假秘钥进行通信,则后续的通讯过程都是采用假秘钥进行,数据库的风险仍然存在。在获取公钥的过程中,我们又引出了一个新的话题:如何安全的获取公钥,并确保公钥的获取是安全的, 那就需要用到终极武器了:SSL 证书(需要购买)和CA机构
解决:
在第 ② 步时服务器发送了一个SSL证书给客户端,SSL 证书中包含的具体内容有证书的颁发机构、有效期、公钥、证书持有者、签名,通过第三方的校验保证了身份的合法,解决了公钥获取的安全性(中间人的公钥没有第三方的保证)
以浏览器为例说明如下整个的校验过程:
(1)首先浏览器读取证书中的证书所有者、有效期等信息进行一一校验
(2)浏览器开始查找操作系统中已内置的受信任的证书发布机构CA,与服务器发来的证书中的颁发者CA比对,用于校验证书是否为合法机构颁发
(3)如果找不到,浏览器就会报错,说明服务器发来的证书是不可信任的。
(4)如果找到,那么浏览器就会从操作系统中取出 颁发者CA 的公钥,然后对服务器发来的证书里面的签名进行解密
(5)浏览器使用相同的hash算法计算出服务器发来的证书的hash值,将这个计算的hash值与证书中签名做对比
(6)对比结果一致,则证明服务器发来的证书合法,没有被冒充
(7)此时浏览器就可以读取证书中的公钥,用于后续加密了
图里的DATA相当于要发送的公钥。
首先服务器向CA请求,CA对这个公钥进行数字签名,然后放入证书。
服务器将这个证书发送给对端,对端接收到后首先判断CA是不是合法机构,如果是就拿出一个CA的公钥,对签名进行解密,解密得到数字签名。然后将数据(也就是公钥)进行hash,将得到的结果与数字签名进行对比,如果相同则证明合法,就可以用这个公钥进行对称密钥的加密了。

完整性保护
SSL 提供报文摘要功能来进行完整性保护。
HTTP 也提供了 MD5 报文摘要功能,但不是安全的。例如报文内容被篡改之后,同时重新计算 MD5 的值,通信接收方是无法意识到发生了篡改。
HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。试想一下,加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
URL输入过程
memcpy,memmove,memset,strcpy,strncpy,strlcpy等等
strcpy与memcpy:
区别:
strcpy与memcpy不同存在于:strcpy只复制字符串,而memcpy可以复制任何内容(字符数组、结构体、类)等。strcpy不需要指定长度由结束符”�”而结束战斗的,memcpy由第三个参数所决定
strcpy:
功能:char *strcpy(char *dest,char *src);
把src所指由NULL结束的字符串复制到dest所指的数组中
src和dest所指内存区域不可以重叠且dest必须有足够的空间来容纳src的字符串。
问题:
strcpy只是复制字符串,但不限制复制的数量。很容易造成缓冲溢出,也就是说,不过dest有没有足够的空间来容纳src的字符串,它都会把src指向的字符串全部复制到从dest开始的内存
内存重叠的问题:
char s[10]="hello";
strcpy(s, s+1); //应返回ello,
//strcpy(s+1, s); //应返回hhello,但实际会报错,因为dst与src重叠了,把'�'覆盖了
当dst在src和src的结尾之间时会出现问题:
比如hello,dst=ello,src=hello:先把h赋值到e,整体变为hhllo,现在src为hllo,dst为llo;再复制一次,变为hhhllo....持续到dst指向'�'而现在src指向的是h,然后这次复制相当于把字符串的�覆盖了,也就是说这个复制永远不会停下来。最后变为hhhhhhhhhhhhhhhhhhhhh直到复制到不可访问的内存
这是由于src后面准备复制到dst中的数据被dst所覆盖的原因
不考虑内存重叠的stcpy的实现:
char * strcpy(char *dst,const char *src) //[1]
{
assert(dst != NULL && src != NULL); //[2]
char *ret = dst; //[3]
while ((*dst++=*src++)!='�'); //[4]
return ret;
}
也就是说,如果dst位于src~src+strlen(src)+1之间(+1是'�'),则由于会覆盖'�'而导致无法停止
因此对于这时,要从后往前拷贝,复制前统计长度,用长度来控制停止。
char * strcpy(char *dst,const char *src)
{
assert(dst != NULL && src != NULL);
int cnt=strlen(src)+1;
char *ret = dst;
if (dst >= src && dst <= src+cnt-1) //内存重叠,从高地址开始复制
{
dst = dst+cnt-1;
src = src+cnt-1;
while (cnt--)
*dst-- = *src--;
}
else //正常情况,从低地址开始复制
{
while (cnt--)
*dst++ = *src++;
}
return ret;
}
memcpy:
void *memcpy(void *destin, void *source, unsigned n);
功能:
将src逐字节拷贝到dst,拷贝n个字节
memcpy不会添加'�',只是机械地拷贝,由n来决定停止。
问题:
同样,当出现内存重叠时,如dst在src和src+strlen(stc)+1中间时:src后面还没有复制到dst中的数据会被覆盖掉
解决办法也是从高地址往低地址拷贝
void *memcpy(void *dest, const void *src, size_t count)
{
char *d;
const char *s;
if (dest > (src+size)) || (dest < src))
{
d = dest;
s = src;
while (count--)
*d++ = *s++;
}
else /* overlap */
{
d = (char *)(dest + count - 1); /* offset of pointer is from 0 */
s = (char *)(src + count -1);
while (count --)
*d-- = *s--;
}
return dest;
memmove:
void *memmove( void* dest, const void* src, size_t count );
功能:
memmove用于拷贝字节,如果目标区域和源区域有重叠的话,memmove能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中,但复制后源内容会被更改。但是当目标区域与源区域没有重叠则和memcpy函数功能相同。
void* memmove(void* dest, const void* src, size_t n)
{
char * d = (char*) dest;
const char * s = (const char*) src;
if (s>d)
{
// start at beginning of s
while (n--)
*d++ = *s++;
}
else if (s<d)
{
// start at end of s
d = d+n-1;
s = s+n-1;
while (n--)
*d-- = *s--;
}
return dest;
}
memset:
功能:
void *memSet(void *s, int c, size_t n)
{
if (NULL == s || n < 0)
return NULL;
char * tmpS = (char *)s;
while(n-- > 0)
*tmpS++ = c;
return s;
}
strncpy:
strncpy(char *to,const char *from,int size);
char *strncpy(char *dst, const char *src, size_t len)
{
assert(des != NULL && src != NULL);
int offset = 0;
char *ret = dst;
char *tmp;
if(strlen(src) < len)
{
offset = len - strlen(src);//补齐0的个数
len = strlen(src);//复制的个数
}
if(dst >= src && dst <= src + len -1)
{
dst = dst + len - 1;
src = src + len - 1;
tmp = dst;//记录补0的位置
while(len--)
*dst-- = *src--;
}
else
{
while(len++)
*dst++ = *src++;
tmp = dst;
}
while(offset--)
*tmp++ = '�';//补0
return ret;
}
strlcpy:
size_t strlcpy(char *dest, const char *src, size_t size)
实现:
size_t Test_strlcpy(char *dest, const char *src, size_t size)
{
size_t ret = strlen(src);
if (size) {
//这句判断大赞,起码有效防止源字符串的越界问题
size_t len = (ret >= size) ? size - 1 : ret;//防止缓冲区溢出,如果不够则只复制到缓冲区满.ret等于size也要考虑到size-1里,因为'�'是后面统一加的
memcpy(dest, src, len);
dest[len] = '�';
}
return ret;
}
哈希冲突怎么解决
1.开放定址法:
Hi=(H(key)+di)Mod m;m为哈希表长度
分为三种:
1).线性探测再散列:
di={1,2,3,4,5,...m-1}
2).二次探测再散列:
di={1,-1,4,-4,9,-9....,k^2,-k^2},k<=m/2;
3).伪随机探测再序列
2.再哈希
Hi=RHi(key) i=1,2,3,4...k
换其他的哈希方法来计算地址,直到可以生成不冲突的哈希
3.开链法:
链表
拉链法中链表太长了应该如何解决
当bucket中有3/4的有负载时,要进行rehash,重建一个2倍大小的bucket数组,由于重建后hash长度变了,所以要重新对其中的值进行哈希并开链。
当链表长度超过8,要将链表转为红黑树。
为什么临界值是8?
理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件
而且n=8时,8与log28=3差距不算太大,综合考虑建树产生的消耗。
CPU读取数据
CPU缓存(Cache Memory)位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。由此可见,在CPU中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。缓存对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。
缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
如何选取N个不重复的随机数?复杂度要低(洗牌算法)
time的头文件为time.h
rand和srand头文件为stdlib.h
比如5 200 9 12 33 44
第一次随机选中200,将200与44交换。
下一次就只在0~4间选取
在下一次就只在0~3件选取
第一次概率为1/n
第二次的概率为,第一次没选中这个数的概率,也就是(n-1)/n;乘上第二次被选中的概率,也就是1/(n-1),为1/n
第三次为(n-1)/n*(n-2)/(n-1)*1/(n-2)=1/n
....
void shuffle(vector<int> arr,int k)
{
int count=0;
for(int i=0;i<k;i++)
{
srand(time(NULL));
int idx=rand()%(arr.size()-count);
swap(arr[idx],arr[arr.size()-1-count]);
count++;
}
}
LRU缓存
vector的push_back手撕
逆波兰表达式的转换与求值
https://www.cnblogs.com/hantalk/p/8734511.html
转换为逆波兰表达式:
'('与')'有最高的优先级;*,/有次级的优先级;+,-最低优先级
遇到字母直接输出;
遇到的运算符,如果比栈顶的运算符优先级低,且栈顶不为(,则输出栈顶内的元素直到栈顶的优先级小于当前运算符,然后将运算符push进栈:因为当前的运算符优先级低,所以数字应该优先与优先级高的向结合。
遇到')',则输出栈内元素直到栈顶为(,再将(pop掉。
最后,如果栈不为空,则将栈内元素依次输出
class Solution
{
public:
string Trans(string in)
{
stack<char> aux;
int p1=0;
string ans;
while(p1<in.size())
{
if(isNum(in[p1]))//a+b*c+(d*e+f)*g
ans+=in[p1];
else
{
if(aux.empty())
aux.push(in[p1]);
else if(in[p1]==')')//遇到),pop到栈顶为(
{
while(aux.top()!='(')
{
ans+=aux.top();
aux.pop();
}
aux.pop();
}
else
{
while(!aux.empty()&&Jugde(aux.top())>=Jugde(in[p1])&&aux.top()!='(')//只有当前运算符优先级比栈顶低,且栈顶不为(
{
ans+=aux.top();
aux.pop();
}
aux.push(in[p1]);
}
}
p1++;
}
while(!aux.empty())
{
ans+=aux.top();
aux.pop();
}
return ans;
}
bool isNum(char str)//判断是否是字母
{
if(str!='('&&str!=')'&&str!='+'&&str!='-'
&&str!='*'&&str!='/')
return true;
else
return false;
}
int Jugde(char str)//评判优先级
{
if(str=='('||str==')')
return 2;
else if(str=='*'||str=='/')
return 1;
else
return 0;
}
};
二层,三层转发(ping的过程)
PC1准备向PC2发送数据包
(1)PC1检查报文的目的IP地址,发现和自己不在同一网段,则需要进行三层转发,通过网关转发报文信息;
(2)PC1检查自己的ARP表,发现网关的MAC地址不在自己的ARP表里;
(3)PC1——>Router(网关)发出ARP请求报文;
(4)Router将PC1的MAC地址学习到自己的ARP表
(5)Router(网关)——>PC1发出ARP应答报文;
(6) PC1学习到Router(网关)的mac地址,发出报文,此时源ip、目的ip不变,目的mac为Router(网关)的mac;
(7)PC1——> Router(网关)发出报文;
(8)Router(网关)收到报文,发现是三层报文(原因是报文的目的mac是自己的mac);
(9)Router(网关)检查自己的路由表(FIB),发现目的ip在自己的直连网段;
(10)Router检查自己的arp表,如果发现有与目的ip对应的mac地址则直接封装报文(目的ip、源ip不变,目的mac为查arp表所得mac)发送给PC2;
(11)如果查ARP表没有得到与目的ip对应MAC,则重复(3)发arp请求;
(12)PC2收到ARP广播报文,发现目的IP是自己的IP,于是给Router发送ARP应答报文。报文中会附上自己的mac地址;
(13)Router收到应答报文后,目的mac改为PC2的mac,然后向PC2发送数据帧;
(14)PC2向Router发送报文;
如何处理的topk问题,如果突然有大量玩家,需要找大量的topok怎么办
第一、100000名实时遍历系统一定承受不了或者说这样做代价太大,那么可以首先遍历一遍,挑选出战斗力最高的1000名,然后后面只遍历这1000名就可以了,因为前500名大概率都是前一千名产生的,减少系统开销。
第二、为了防止某些玩家充钱了,大幅提升战斗力,那么可以设置一个阈值,如果某个玩家战斗力增加速度超过阈值,那么这个玩家也应该纳入实时排序过程中。
第三、最后100000名玩家的战斗力可以定期在服务器压力不大的时候,比如休服时期或者夜间,做整体排序,以便校验数据的准确性。
C++指针和引用的参数传递区别
1.指针参数传递本质上是值传递,它所传递的是一个地址值。值传递的特点是,被调函数对形式参数的任何操作都是作为局部变量进行的,不会影响主调函数的实参变量的值(形参指针变了,实参指针不会变)。
2.引用参数传递过程中,被调函数的形式参数也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址.因此,被调函数对形参的任何操作都会影响主调函数中的实参变量。
3.从编译的角度来讲,程序在编译时分别将指针和引用添加到符号表上,符号表中记录的是变量名及变量所对应地址。指针变量在符号表上对应的地址值为指针变量的地址值,而引用在符号表上对应的地址值为引用对象的地址值(与实参名字不同,地址相同)。符号表生成之后就不会再改,因此指针可以改变其指向的对象(指针变量中的值可以改),而引用对象则不能修改。
new和malloc的区别
1. 申请的内存所在位置
new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存
new在静态存储区上分配内存
2.返回类型安全性
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
3.内存分配失败时的返回值
new内存分配失败时,会抛出bac_alloc异常,它不会返回NULL;malloc分配内存失败时返回NULL。
new的检查:
1.try后通过catch捕捉异常
try{
int* p = new int[SIZE];
//其他代码
}catch( const bad_alloc& e ){
return -1;
}
2.抑制new抛出异常,而返回空指针
int* p = new (std::nothrow) int; //这样,如果new失败了,就不会抛出异常,而是返回空指针
if( p==0 )//如此这般,这个判断就有意义了
return -1;
4.是否需要指定内存大小
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸
5.是否调用构造函数/析构函数
使用new操作符来分配对象内存时会经历三个步骤:
第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
第三部:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
第一步:调用对象的析构函数。
第二步:编译器调用operator delete(或operator delete[])函数释放内存空间
5.是否可以被重载
opeartor new /operator delete可以被重载。
6.能够直观地重新分配内存
使用malloc分配的内存后,如果在使用过程中发现内存不足,可以使用realloc函数进行内存重新分配实现内存的扩充。realloc先判断当前的指针所指内存是否有足够的连续空间,如果有,原地扩大可分配的内存地址,并且返回原来的地址指针;如果空间不够,先按照新指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来的内存区域。new没有这样直观的配套设施来扩充内存

new.new[],delete,delete[]的瞎比使用:
合法的new/delete和mallc/free示意图

new [] 时多分配 4 个字节,用于存储用户实际分配的对象个数。而new不会多分配。
mallc和free的实际大小,这个信息存储在内存块的块头里面。其中最重要的就是指示实际分配的内存大小(单位:字节),那么在free时,就要将用户的传入的地址,减去块头长度找到实际分配内存的起始地址然后释放掉。块头的长度是8字节。
Q1: new为什么使用delete[]失败?
首先new不会偏移四个字节,因此new返回的地址实际上就是对象的地址。而当使用delete[]时,会首先向前(低地址)方向移动四个字节,这四个字节记录了分配对象的个数。而现在由于使用的是new,也就是说实际上是不存在这四个字节的,因此实际上delete[]向前移动四个字节,这个地址落在了块头里,然后按块头里后四个字节的值进行析构,而这是一个比较偏大的值,最终导致内存越界。
new时不会偏移4字节,delete[]时,编译器就是通过标识符[]而执行减4字节操作。从上图可知,减后的地址值会落到块头中(块头有8个字节),同时编译器从块头中提取4字节中的值作为自己执行析构对象的个数,而这4个字节是实际内存的长度,这是一个比较偏大的值,比如256,然后编译器对随后的内存对象执行析构,基本上都会导致内存越界,这必然失败。
也就是说,将new里块头的前四个字节当做了析构的个数,最终导致内存越界
Q2:new[]为什么内嵌类型使用delete成功,自定义类型delete失败?
new[],如果是内嵌类型,比如char或者int等等,就是C数组,那么它不会向后(地址变大的方向)偏移4个字节,也就是说他没有自定义类型的记录对象个数的4个字节(可能是因为trivial的原因?),因此执行delete时,显然不会出现任何问题(因为实际上对于基本数据类型来说,new[]等价于new)。
但是如果是自定义类型呢?那么new[]时就会向后偏移4个字节(因为有4个字节用于存放对象个数,而实际上第一个对象的地址在malloc分配的内存的四个字节之后),从malloc的返回地址偏移4个字节用来存储对象个数,如果使用delete,编译器是识别不出释放的是数组,那么它会直接将传入对象的首地址值处执行一次对象析构,这个时候还不会出现问题(因为地址值就是第一个对象的位置,也就是malloc返回的地址的后面四个字节的位置),但是再进一步,它把对象的首地址值传递给free时,那么这个地址值并不是malloc返回的地址,而是相差了4个字节,此时free向前偏移取出malloc的实际长度时,就会取出对象的个数值作为实际的分配长度进行释放(也就是说,free以当前位置为起点,向前找8个字节,因为这8个字节是块头信息,而由于实际上是用new[]分配的,因此实际上向前移动八个字节并没有移动到头,而是移动到了块头的后四个字节,这后四个字节与存储对象个数的4个字节一起组合在一起),显然这将导致只释放了n字节,其余的块头一部分和除n字节的所有内存都泄露了(因为实际上只释放了第一个对象以及第一个对象前面8个字节,这8个字节由记录对象个数的4个字节和块头的后4个字节组成),并且只有第一个对象成功析构,其余都没有析构操作。一般对象个数n是个非常小的值,比如128个对象,那么free只释放了128字节。(注意:不同的libc实现不同,这里只示例阐述原理,不深究数字)
总而言之:
对于使用delete[]来释放new时:由于错误地认为有4个字节存放对象个数,而导致偏移到块头中,失败的原因是析构对象个数错误(过多)而导致内存越界。
对于使用delete来释放new[]时:第一个对象的析构是不会出问题的,问题出在free,由于使用delete因此认为不会有4个字节存放对象个数,因此向前偏移8个字节而找到了块头的后四个字节的位置,从此处开始释放,因此会导致内存泄漏(至少块头的前4个字节是泄漏的),且大量对象没有析构(除了第一个)。
缺页中断处理过程
当进程执行过程中发生缺页中断时,需要进行页面换入,步骤如下:
<1> 首先硬件会陷入内核,在堆栈中保存程序计数器。大多数机器将当前指令的各种状态信息保存在CPU中特殊的寄存器中。
<2>启动一个汇编代码例程保存通用寄存器及其它易失性信息,以免被操作系统破坏。这个例程将操作系统作为一个函数来调用。
(在页面换入换出的过程中可能会发生上下文换行,导致破坏当前程序计数器及通用寄存器中本进程的信息)
<3>当操作系统发现是一个页面中断时,查找出来发生页面中断的虚拟页面(进程地址空间中的页面)。这个虚拟页面的信息通常会保存在一个硬件寄存器中,如果没有的话,操作系统必须检索程序计数器,取出这条指令,用软件分析该指令,通过分析找出发生页面中断的虚拟页面。
<4>检查虚拟地址的有效性及安全保护位。如果发生保护错误,则杀死该进程(看看访问的页面是否合法,如使用NULL导致被杀死)。
<5>操作系统查找一个空闲的页框(物理内存中的页面),如果没有空闲页框则需要通过页面置换算法找到一个需要换出的页框。
<6>如果找的页框中的内容被修改了,则需要将修改的内容保存到磁盘上,此时会引起一个写磁盘调用,发生上下文切换(在等待磁盘写的过程中让其它进程运行)。
(注:此时需要将页框置为忙状态,以防页框被其它进程抢占掉)
<7>页框干净后,操作系统根据虚拟地址对应磁盘上的位置,将保持在磁盘上的页面内容复制到“干净”的页框中,此时会引起一个读磁盘调用,发生上下文切换。
<8>当磁盘中的页面内容全部装入页框后,向操作系统发送一个中断。操作系统更新内存中的页表项,将虚拟页面映射的页框号更新为写入的页框,并将页框标记为正常状态。
<9>恢复缺页中断发生前的状态,将程序指令器重新指向引起缺页中断的指令。
<10>调度引起页面中断的进程,操作系统返回汇编代码例程。
<11>汇编代码例程恢复现场,将之前保存在通用寄存器中的信息恢复。
分段和分页的优缺点以及概念
在段式存储管理中,将程序的地址空间划分为若干段(segment),如代码段,数据段,堆栈段;这样每个进程有一个二维地址空间,相互独立,互不干扰。段式管理的优点是:没有内碎片(因为段大小可变,改变段大小来消除内碎片)。但段换入换出时,会产生外碎片(比如4k的段换5k的段,会产生1k的外碎片)
在页式存储管理中,将程序的逻辑地址划分为固定大小的页(page),而物理内存划分为同样大小的页框,程序加载时,可以将任意一页放入内存中任意一个页框,这些页框不必连续,从而实现了离散分离。页式存储管理的优点是:没有外碎片(因为页的大小固定),但会产生内碎片(一个页可能填充不满)
(1) 分页仅仅是由于系统管理的需要而不是用户的需要。段则是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好地满足用户的需要。
(2) 页的大小固定且由系统决定,由系统把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而在系统中只能有一种大小的页面;而段的长度却不固定,决定于用户所编写的程序,通常由编译程序在对源程序进行编译时,根据信息的性质来划分。
(3) 分页的作业地址空间是一维的,即单一的线性地址空间,程序员只需利用一个记忆符,即可表示一个地址;而分段的作业地址空间则是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址。
struct和class的区别
1.默认的继承访问权。class默认的是private,strcut默认的是public。
2.默认访问权限:struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的
3.“class”这个关键字还用于定义模板参数,就像“typename”。但关键字“struct”不用于定义模板参数
extern的作用
extern 作用1:声明外部变量
extern的原理很简单,就是告诉编译器:“你现在编译的文件中,有一个标识符虽然没有在本文件中定义,但是它是在别的文件中定义的全局变量,你要放行!”
extern 作用2:在C++文件中调用C方式编译的函数
extern "C" 的作用是让 C++ 编译器将 extern "C" 声明的代码当作 C 语言代码处理,可以避免 C++ 因符号修饰导致代码不能和C语言库中的符号进行链接的问题。