3.1.1 为什么编译器要把词法分析和语法分析分开

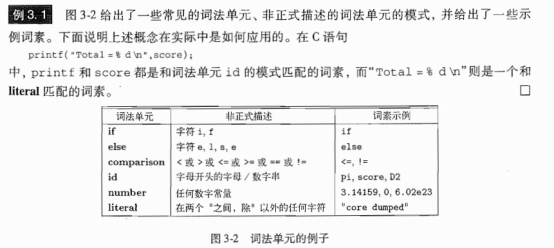
3.1.2 词法单元、模式和词素(重要)

例:

3.1.3 词法单元的属性(重要)

词法单元的属性是用来记录相对应的词素的一些相关属性信息。
例:
int x = 10 + 20;
这里的 10 和 20 都是number的词法单元。但是他们具有不同的词素, 一个是10一个是20。在代码生成的阶段需要使用到具体的数值,所以词法单元的属性需要保存他们具体的值。
3.2.1 缓冲区对

3.2.2 哨兵标记
在每个缓冲区块的最末尾添加一个 不同于其他字符的特殊字符串用来标记是否到达了缓冲区末尾。
添加这个标记的目的是方便我们识别缓冲区结尾。如果没有这个标记,我们在处理每一个字符的时候都需要去判断一下是否到达了缓冲区某位。如果有一个标记我们就可以把这个标记也当做一个特殊的字符去处理。

综合 3.2.1 和 3.2.2算法举个例子
下面的例子是一个C语言的函数,我们要对下面的程序进行词法分析。
... 代表其他语句
main()
{
...
...
var_1 = var_2 + 10;
...
...
}
我们默认有两个缓冲区A, B
缓冲区A的内容
|
m |
a |
i |
n |
( |
) |
{ |
. |
. |
. |
v |
a |
r |
_ |
1 |
= |
v |
a |
eof |
var_1 = var_2 + 10;其中有两个标识符 一个是 var_1, 一个是 var_2。
分析 var_1的时候lexemeBegin指向v, forward指针不断的前移。
当forward 指向一个字符会去判断这个字符是否符合这个词法单元的模式,如果不符合那么从lexemeBegin到foreward之间的词素就可以提取出来当做一个词素。
var_1我们当成标识符去处理的时候,遇到=字符的时候,我们就会提取出var_1因为’=’不符合标识符的模式。

分析 var_2的时候lexemeBegin指向v, forward指针不断前移。
但是A缓冲区的内容只读取到了var_2的va部分就到达了缓冲区的结束了。这时我们就要用缓冲区B来加载剩余的文件内容, 并且把forward指针指向缓冲区B的开头。然后继续之前的动作,forward指针一直前移直到遇到不匹配这个模式的字符位置。当遇到缓冲区B的eof的时候。我们就继续加载文件剩余的内容到缓冲区A中。除非词素的长度大于缓冲区的内容才有可能出问题。

3.4.1 状态流转图(重要)

红线部分表达的意思是:
从A状态到B状态经过标号为S的边,这个标号为S的边可以包含多个符号。
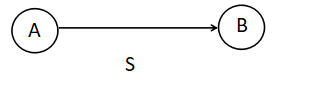
例如: [a-z]+([0-9]+|[A-Z+]) 这个正则表达式 小写字母a-z的输入在状态A,当遇到大写字母A-Z或者数字0-9的时候都经过S的边到达状态B。
3.4.2 区分标识符和关键字

例子:3.10 如何识别多个词法单元 (非常重要)
