作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:duymgzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)

保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
!pip install PyMySQL !pip install sqlalchemy import pymysql from sqlalchemy import create_engine coninfo='mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8' engine=create_engine(coninfo,encoding='utf-8') newsdf.to_sql(name='news',con=engine,if_exists='append',index=False,index_label='id') newsdf.to_sql(name='news',con=engine,if_exists='append',index=False) conn=pymysql.connect(host='localhost',port=3306,user='root',passwd='',db='gzccnews',charset='utf8')
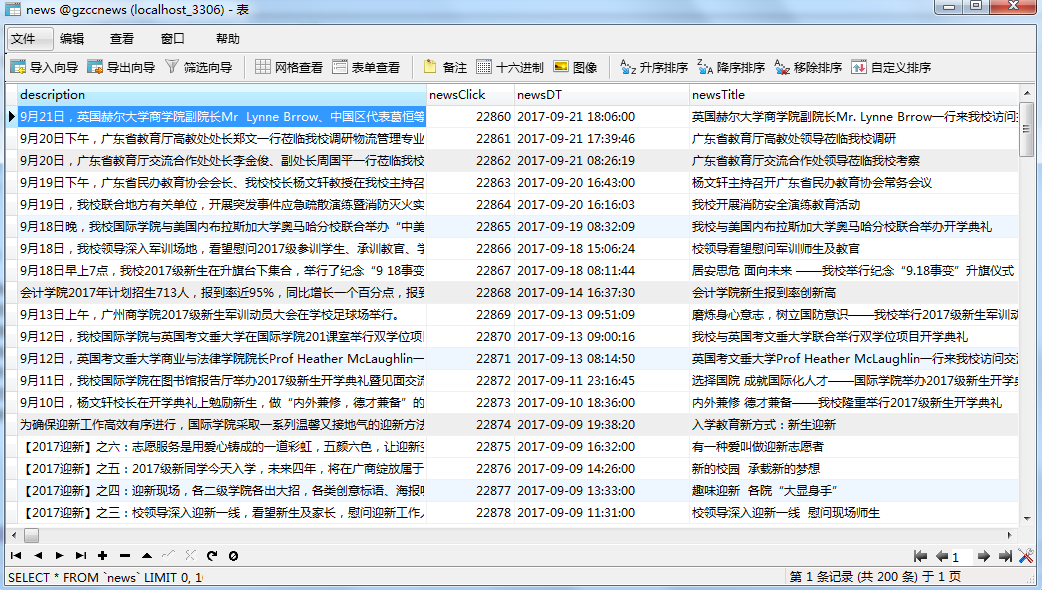
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
三.爬虫
数据爬取
现在猫眼电影网页似乎已经全部服务端渲染了,没有发现相应的评论接口,参考了之前其他文章中对于猫眼数据的爬取方法,找到了评论接口!
https://api.bilibili.com/x/v2/reply?type=1&oid=37942085&sort=0&_=1557108277117&pn=

接下来爬取评论:

最终我们获取到了大约796条数据


数据分析
数据分析我们使用了百度的pyecharts、excel以及使用wordcloud生成词云
评论分布城市
由图中可以看出主要分布在各大一线、新一线城市,对于杭州为何会排在第17的位置,我觉得可能是大家都用淘票票的缘故吧!
接下来是评分占比情况

由图中可以看出,评分在4以上的占比达到了94%,而平均评分也达到4.68分!!!
再来看一下各城市评分情况:

词云代码


词云出现较多的是好看、特效、剧情、震撼等,可以看出大家对此电影对特效和剧情还是十分认同的
四、总结:
经过对哔哩哔哩电影上《海王》这部电影的部分评论的爬取、分析、数据可视化之后,从中总结出对电影的感想:
《海王》这部电影从剧情上来看,编排得非常完美和符合逻辑,如果说电影里的海王,他了解陆地也了解海洋的话,那么温才他了解美国也了解中国;从特技上来看呢,也堪比《阿凡达》、《魔戒》。这些都是我们没有幻想到的世界,都是我们无法预测的神秘。只有您无法预测剧情和无法预知特效,才算是震撼,才能算是好电影。所以任何人要想在自己的生涯中获得成功,首先要突破的障碍不是技能,不是知识,不是地位,而是自己