一、ES横向扩容方案
横向扩容方案一:
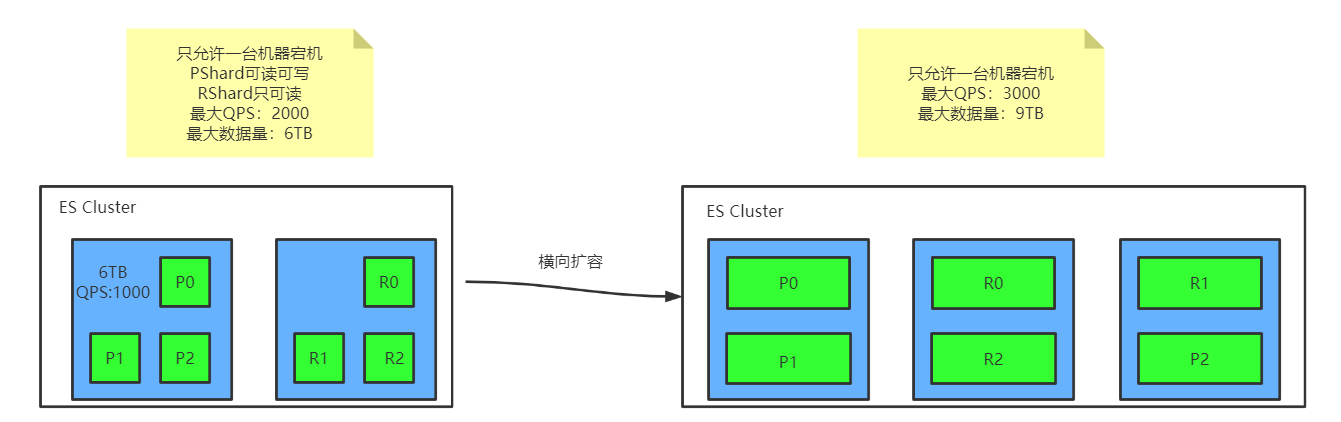
横向扩容方案二:
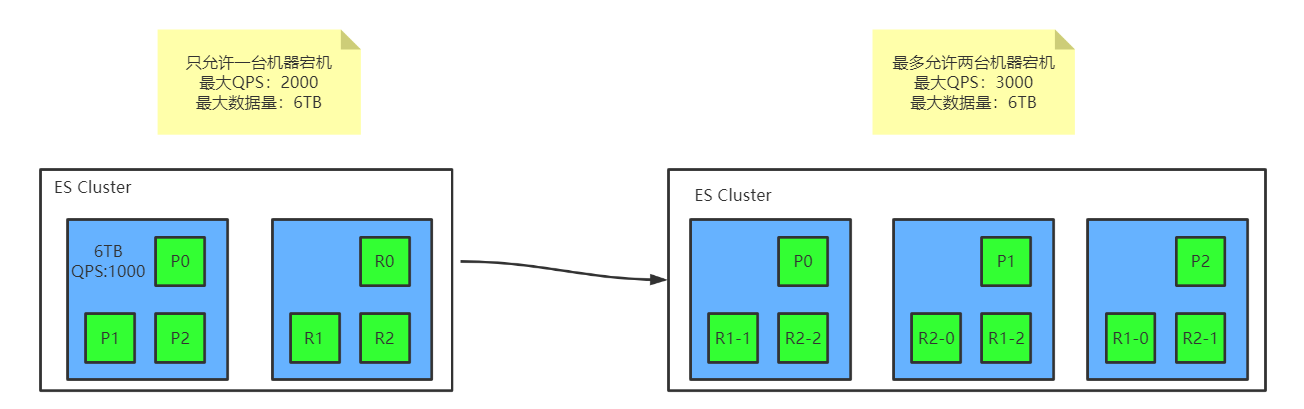
二、ES容错机制
1、容错:各种情况下都能保证工作正常运行
在局部出错异常的情况下,保证服务正常运行并且有自行恢复能力
2、ES的角色
① Master:主节点,每个集群都有且只有一个
尽量避免Master节点 node.data = true
②voting:投票节点
Node.voting_only = true
仅投票节点,即使配置了data.master = true,也不会参选, 但是仍然可以作为数据节点
③coordinating:协调节点
每一个节点都隐式的是一个协调节点
如果同时设置了data.master = false和data.data=false,那么此节点将成为仅协调节点
④Master-eligible node(候选节点):一般情况下在集群中候选节点的数量和投票节点相同
⑤ Data node(数据节点):进行数据交互工作
3、容错图解
第一步:Master选举
①脑裂:可能会产生多个Master节点
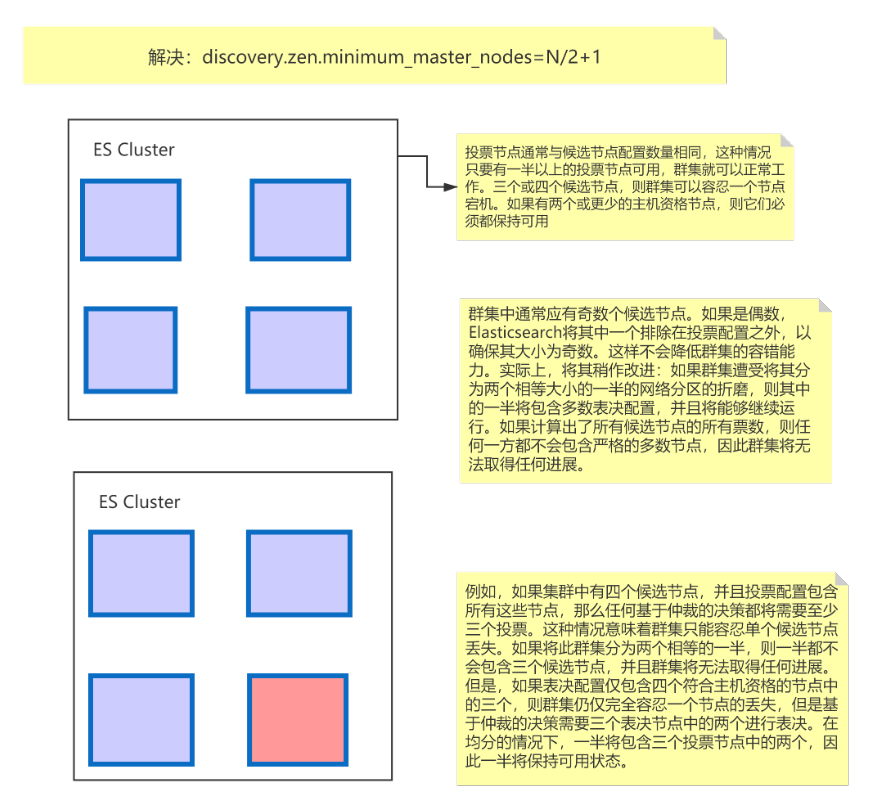
② 解决:discovery.zen.minimum_master_nodes=N/2+1
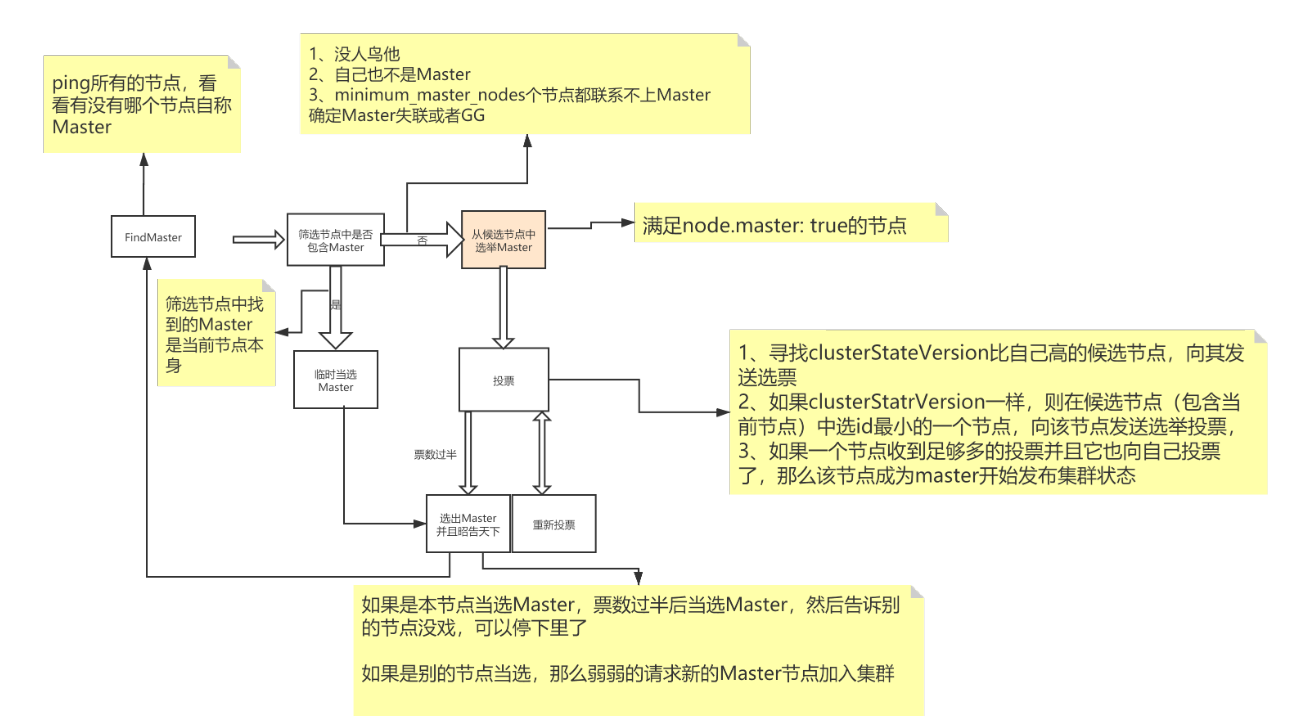
第二步:Replica容错
新的(或者原有)Master节点会将丢失的Primary对应的某个副本提升为Primary
第三步:重启故障机
第四步:数据恢复
Master会将宕机期间丢失的数据同步到重启机器对应的分片上去
如上图横向扩容方案二所示,假设P0所在机器宕机,则其他机器中P0对应的副本分片(假设为R2-0)升级为主分片承担写操作(副本分片只能读,主分片既能读又能写)
在R2-0副本分片升级为主分片,故障机重启成功的这段时间内,会有新增的数据写到R2-0中,当宕机机器重启成功后,R2-0会把新增的数据拷贝到P0中
4、脑裂
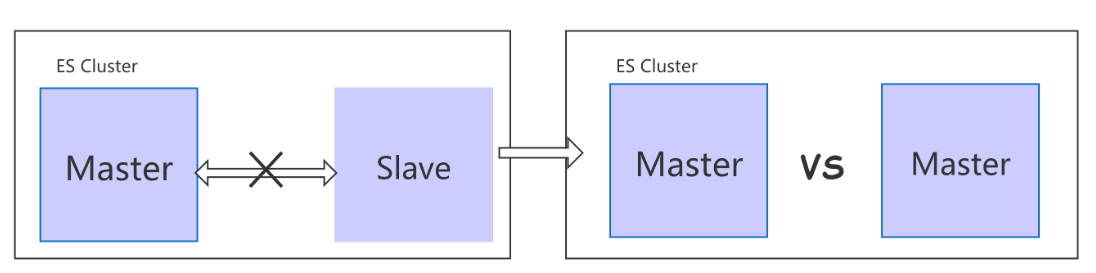
如上图所示,假设集群中有两台机器,这两台机器位于不同机房,这时网络断开,es中一个节点发现没有了Master节点,会发起投票,将自己选为Master节点。一段时间后网络重连成功,就出现了两台Master节点,这就是脑裂。
5、解决脑裂
如果候选节点(node.master = true)的节点有偶数个,那么es会将其中一个节点排除在投票节点之外
三、ES配置文件
①设置主节点:node.master:true(在主节点宕机后有竞选主节点的资格)
②进行数据存储:node.data:true
一共会出现4种组合:
1、①②都为true:既有主节点的竞选资格又有数据存储功能
2、①为false②为true:只存储数据
3、①为true②为false:只担当主节点
4、①②都为false:协调节点,做负载均衡(转发),请求过来后转发到下一节点
注意:一般来说master节点不用做数据存储节点
在学习时尽量使用默认配置,如果修改默认配置,es会认为你从开发模式切换到生产模式
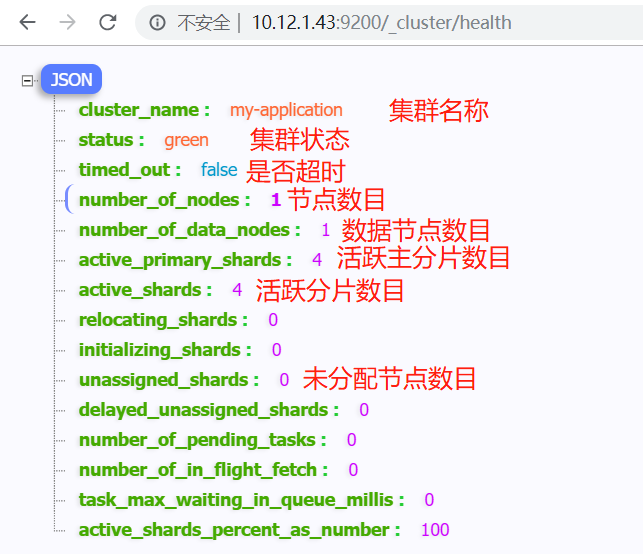
四、集群健康值检查
1、Green:所有PShard和RShard都处于活跃状态
2、Yellow:当前集群中至少有一个RShard不可用
3、Red:至少有一个PShard不可用
五、安装
1、es安装
2、node 安装
3、kibana安装
六、CRUD
1、创建索引:PUT /索引?Pretty
2、查询索引:GET _cat/索引?v
3、删除索引:DELETE /索引/Pretty
4、插入数据:
PUT /索引/_doc/id
{
Json数据
}
5、更新数据
① 全量替换:按照插入时的数据格式编辑并执行,在需要修改的位置修改数据
② 指定字段更新
POST /索引/_doc/1/_update
{
"doc":{
"price":2999
}
}
6、删除数据: DELETE /index/type/id
7、查询数据:GET /索引/_search
8、条件查询:GET /索引/_search?q=price:2999&sort=price:asc