ISSCC-2020-GANPU论文解读
@论文笔记
GANPU: A 135TFLOPS/W Multi-DNN Training Processor for GANs with Speculative Dual-Sparsity Exploitation
一、背景和动机
1.背景
这篇论文是韩国KAIST大学Semiconductor System Lab的最新成果,KAIST大学在片上训练(On-chip-training)领域还是非常强的,已经在ISSCC发表过多篇相关论文。这篇论文是针对GAN生成对抗网络做的片上训练系统。
首先对GAN的背景以及应用做了些介绍,Gan广泛应用于图片的风格迁移,AI换脸,图片修复等场景,无非是应用广泛,值得一做。
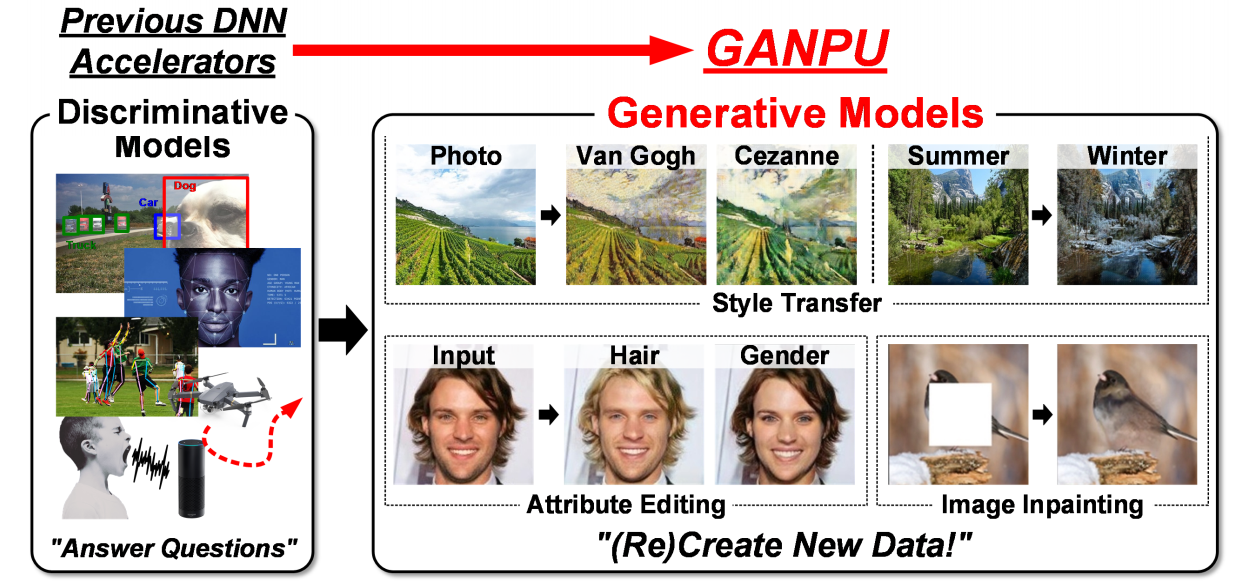
生成对抗网络主要分为两个部分,一个生成器和一个判别器。生成器的任务是根据输入图片来生成一张“赝品”图片,而判别器则接受生成的赝品图片以及真实的标签图片,评估两者的差异并输出生成器生成的是赝品还是真货,如果生成器生成的图片没能成功“骗过”判别器,则会根据判别器的输出来更新或者优化生成器。
总而言之,GAN的两个网络相互配合,可以实现生成器生成的图片尽量像标签图片或者说目标图片靠拢。

2.动机
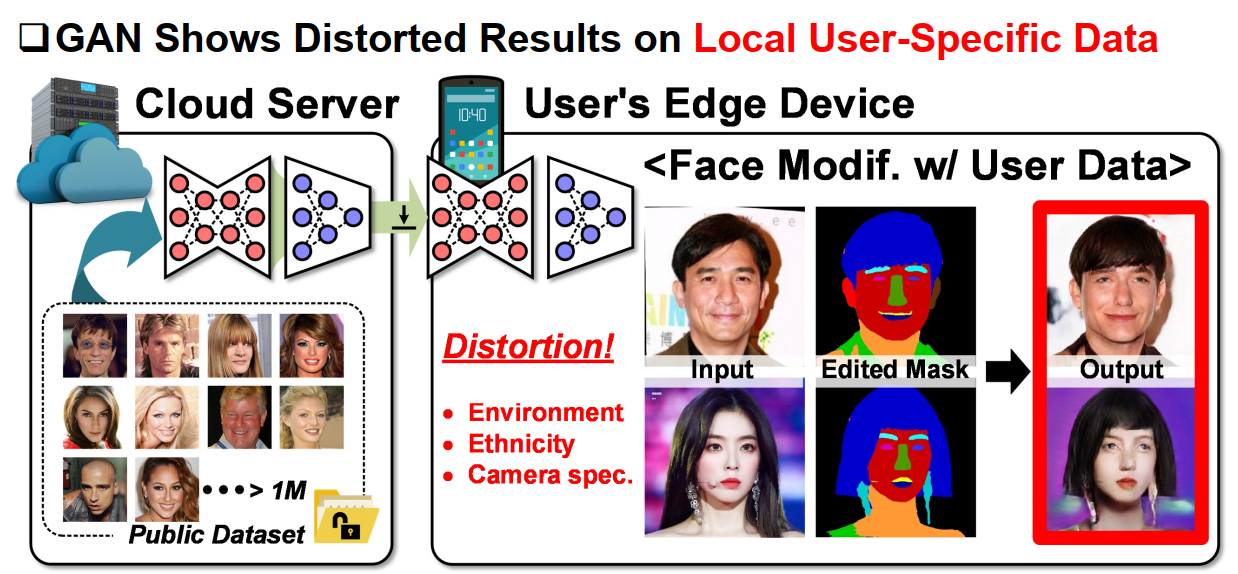
a. 本地VS云端
之后,论文提出了主要矛盾,在边际设备上,从云端下载下来的模型在本地针对不同用户的的使用场景表现出来明显的失真。因此需要做片上的训练。
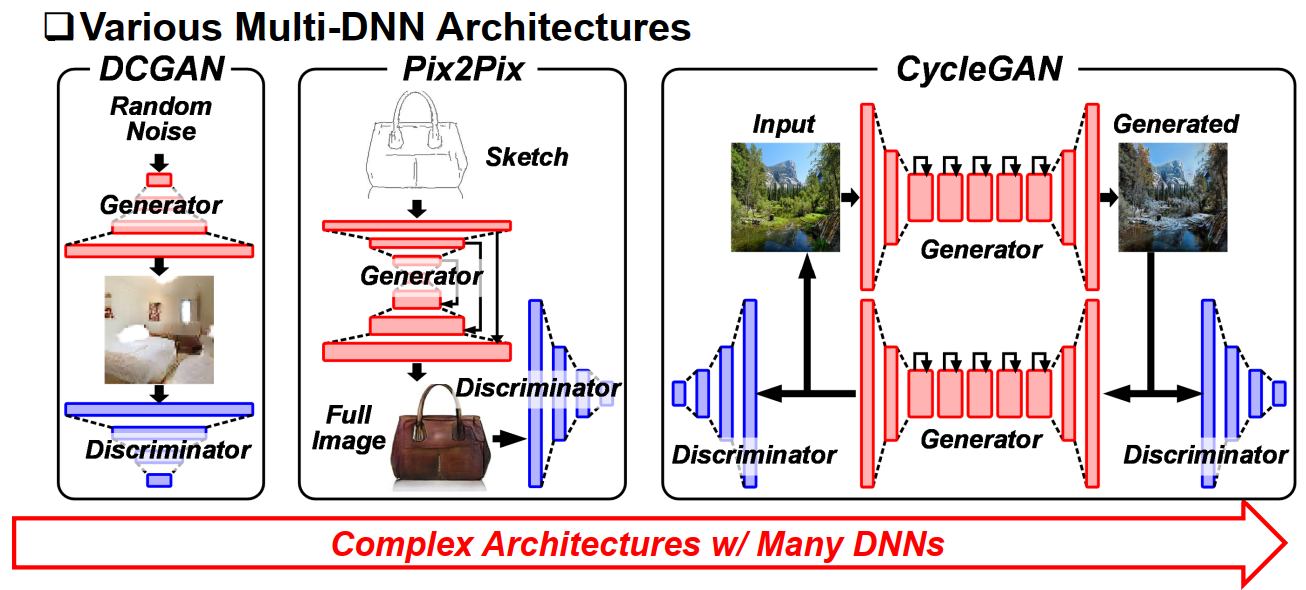
GAN网络的主要分类。
b. 计算和存储瓶颈
不同类别的GAN的资源利用和计算量,存在明显的存储瓶颈和计算瓶颈。

一般判别器可以用传统的图像分类benchmark实现,判别器和生成器的计算量存在较大的差异,一半来说生成器的计算量普遍比判别器大几个量级。
c. 输入与输出稀疏性的不对称
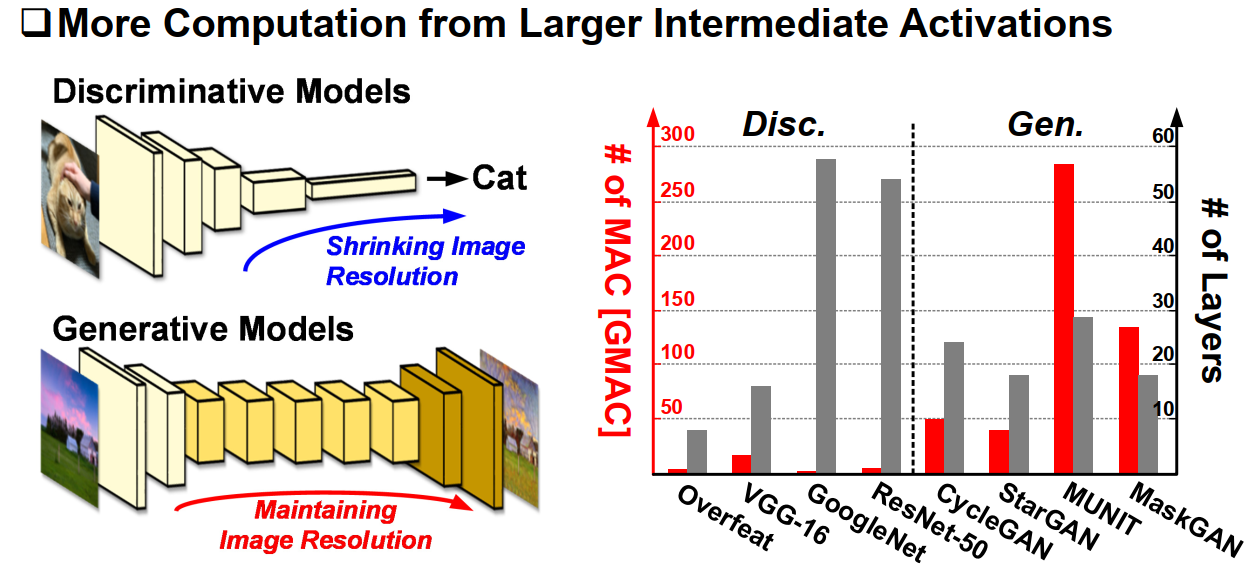
另外,传统的稀疏性方法在反向传播时并不适用。当输入激活值存在0元素时,在卷积时可以直接跳过为0元素的乘累加,这就是所谓的IA (input actication) zero skipping : 输入稀疏性跳过。
而事实上,如果说我们能预先知道输出层的某个元素为0,那么其实可以直接跳过计算该元素的所有运算!在反向传播中,由于反传的公式特殊性,以及一般卷积之前都会经过Relu函数激活,导致在向前推断梯度时可以预先知道输出的哪个位置是0(具体原理下面会分析),因此可以直接跳过设计该位置的所有运算。这就是所谓的 OA (output activation) zero skipping :输出稀疏性跳过。

这边也提到了,反向传播具备的这种OA性质,只能加速反传,对前向的计算实际上没有帮助,因为前向过程无法预先知道输出的稀疏性。
下面这张图比较清楚地解释了为什么反传时OA可以提前确定:
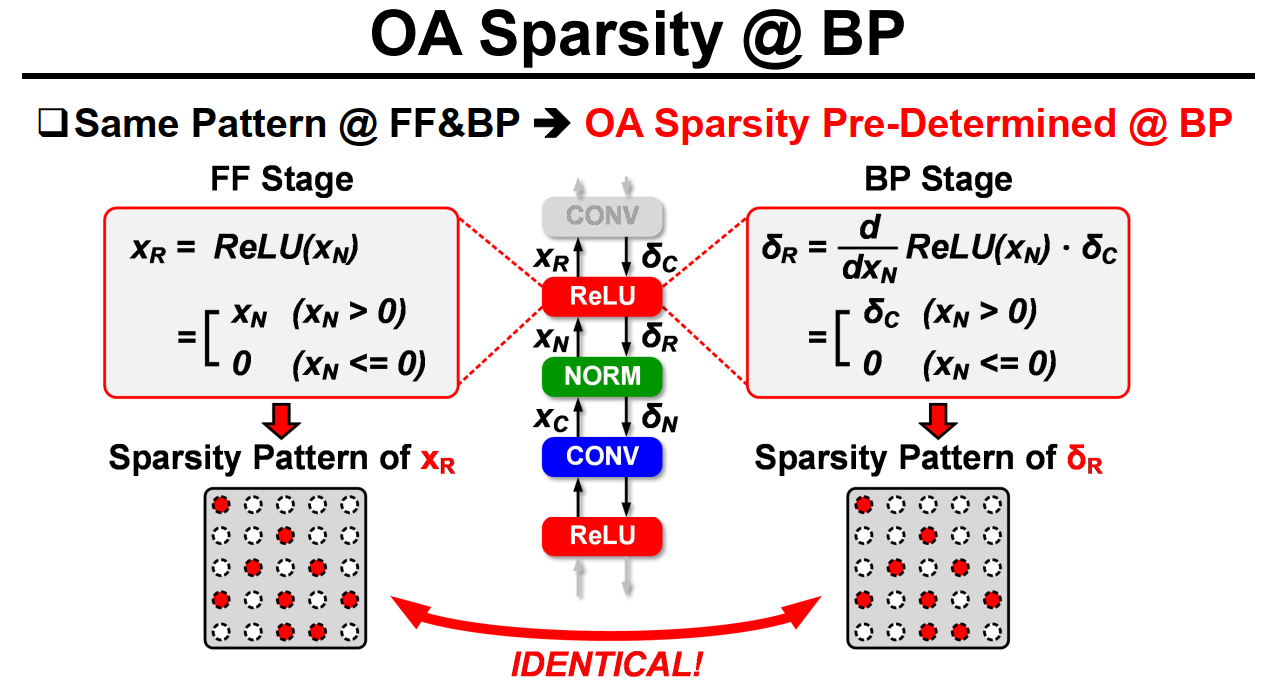
实际上从(delta_c)到(delta_R)的推断时会乘上激活函数导函数在(X_N)处的值,而Relu的导函数在x小于0时值为0,因此只要计算得到(X_N),就能提前知道反传过程这一层的梯度(delta_R)的哪些位置为0了。
通过上面的分析,可见IA和OA似乎在前向inference时是无法兼得的,这也是本文解决的主要问题之一。
二、架构
整体的架构分为三个层次:
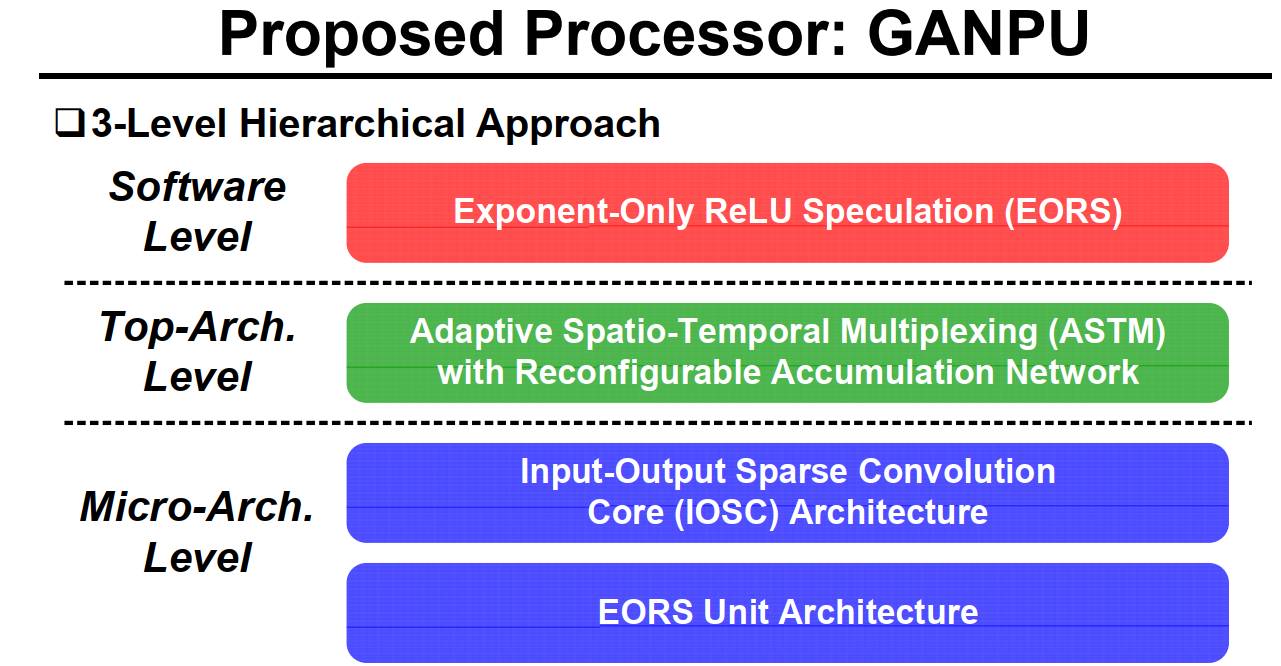
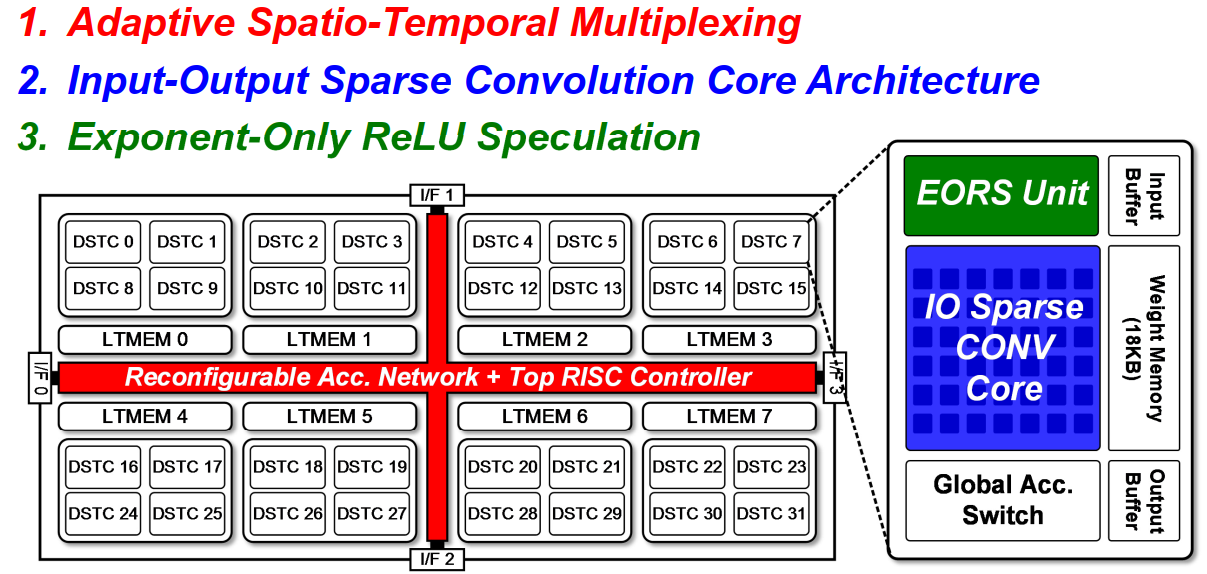
1. GANPU硬件架构
整体拓扑图如下:
-
采用了4*2*4=32个双边稀疏化训练集群(DSTC)
-
二维网格化片上网络,并且具有4个外部接口
-
8位和16位算术单元
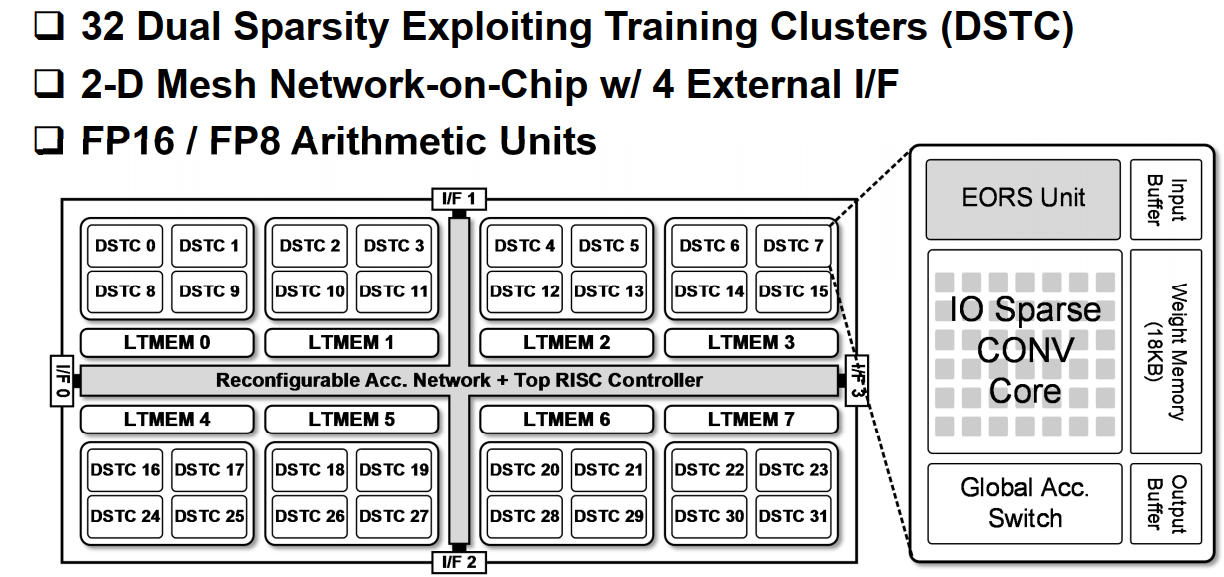
在每个DSTC内部,包含:
- 输入-输出稀疏卷积计算核
- 指数形式Relu推测器
外部控制器包含可重构的累加网络和RISC控制器,以及一种自适应的空间-时间复用方法。
2. 顶层的映射和数据调度机制
a. Adaptive Spatio-Temporal Multiplexing
先介绍自适应时空复用的工作机制:
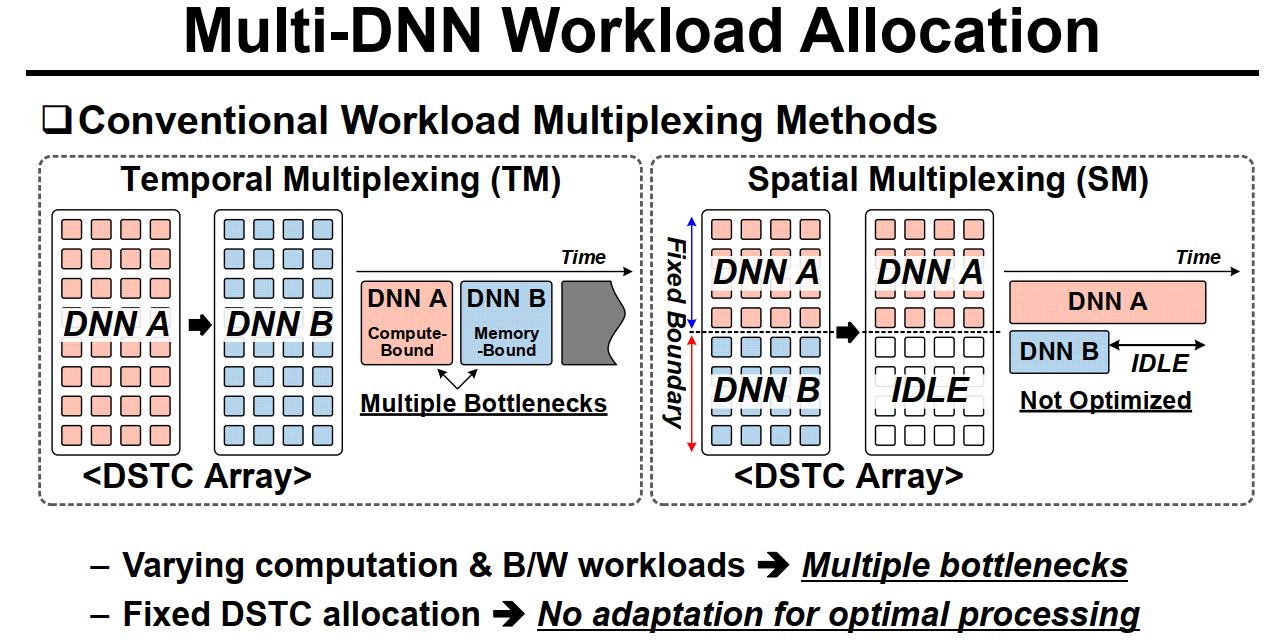
传统的计算网络的方式是分时复用,在第一个时间步内计算A网络,在第二个时间步内计算B网络。但是往往因为网络差异导致两次计算面临不同的瓶颈。
而另一种是分空间复用,将整个计算阵列分成两部分,分别计算呢A和B网络,哪个没算完,下个时间步继续把那个算完。这种复用方式一般会固定阵列的分法,也就是Fixed boundary的方式,因此缺少了自动适配的方式。(好的适配方式可以让A和B几乎同时算完而没有IDLE)
因此论文提出了一种两者结合的方式ASTM:
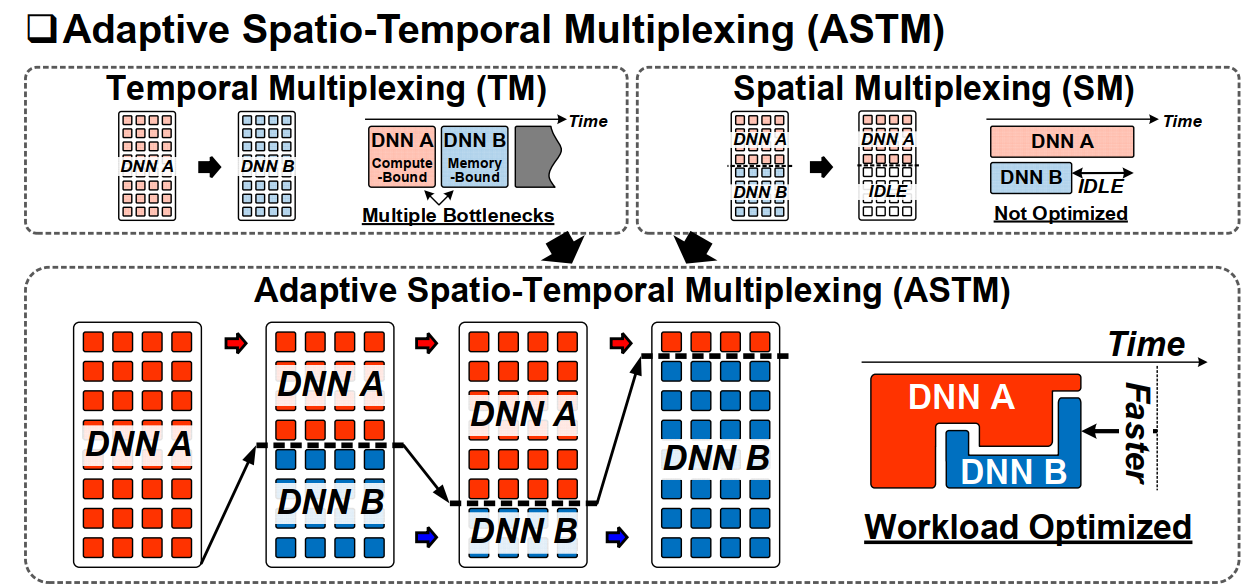
就是说可以自动根据带宽和计算将计算阵列分配给不同的网络部分,完成分时分空间的混合复用,从而可以最大程度地优化工作负载并缩短计算延迟,达到的效果如上图右下角所示。
b. Reconfigurable Accumulation Network
跟上面的ASTM机制配合的是下面的这种可重构的累加网络。因为ASTM会分时地将计算阵列划分为不同的部分,这些部分映射两个不同网络的不同计算,其计算的部分和需要特定的方式累加起来才是正确的结果。这个累加网络就是负责干这个事。

可见为了匹配ASTM的这种灵活性,每个DSTC单元都跟一个Global Acc. Switch链接。每个switch都有东南西北四个方向的I/F。每个DSTC都可以通过它链接的Switch模块将自己的部分和传到临近的任意一个节点并在节点中完成累加、BN以及激活操作,再分发给下一个节点。
以上两个是top层做的优化,涉及一种数据调度和计算映射优化的片上网络。
2. DSTC单元内部的工作方式
a. IOSC
在每个DSTC内部包含了6*7个PE单元,阵列左侧的输入buf存放以行为单位,逐通道方式存放的输入图,上方的mem存放7组filter,每组6个通道(个人理解)。每行PE计算一个输入通道,每列PE计算一个输出通道,每个PE计算完乘累加后将部分和往下输入到下一行pe与下一行的部分和累加,最后输入Local Accumulator。Local Acc应该是用于累加不同组Weight Mem计算得到的输出值(每次计算6个输入通道,在local acc中完成所有通道和的累加)。
每行PE公用一个Row Buffer,用于Row stationary的数据流,每计算完一次卷积Row Buffer内的数据相对之前的数据在input map上往右滑动一个stride。
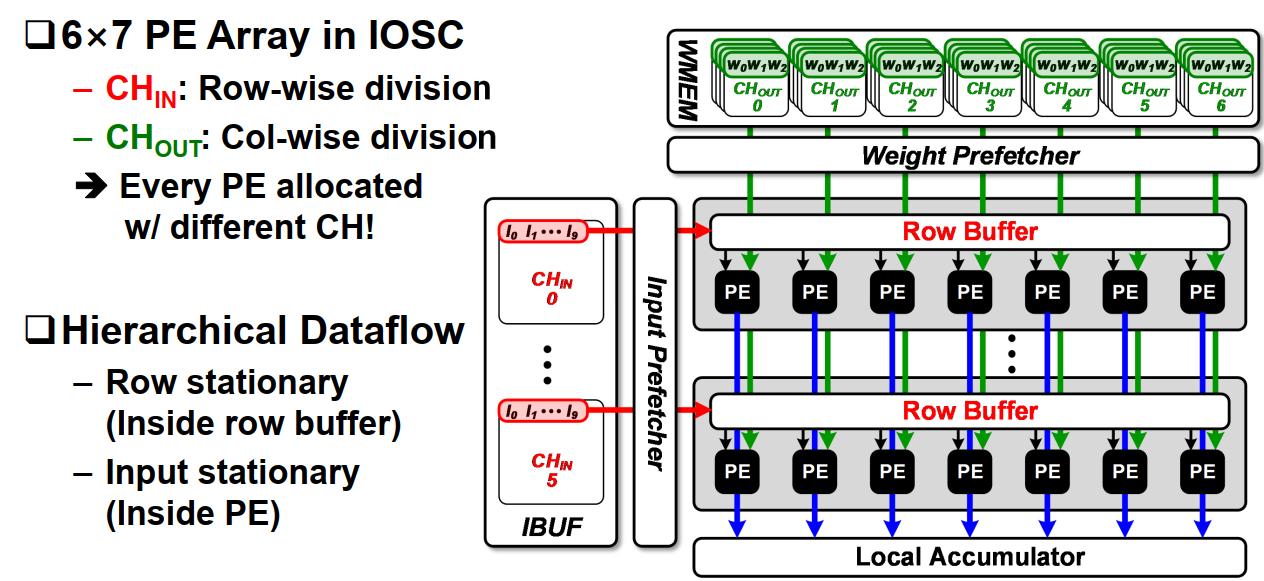
每个PE内部采用的是Input stationary的形式,我理解的方式是:例如weight是3*3的大小,第一次放到pe里的是第一行的weight,与第一行的input map做卷积,做完这行之后,Row buffer导入下一行input map。而这时pe内部的weight不动,先计算第一行weight和第二行ifmap的卷积,得到第二行output map的部分结果。之后才导入第二行weight,保持ifmap不动,计算第二行ifmap和第二行weight的卷积,得到第一行的output map部分结果。
下面介绍了PE内部的IO skip逻辑:
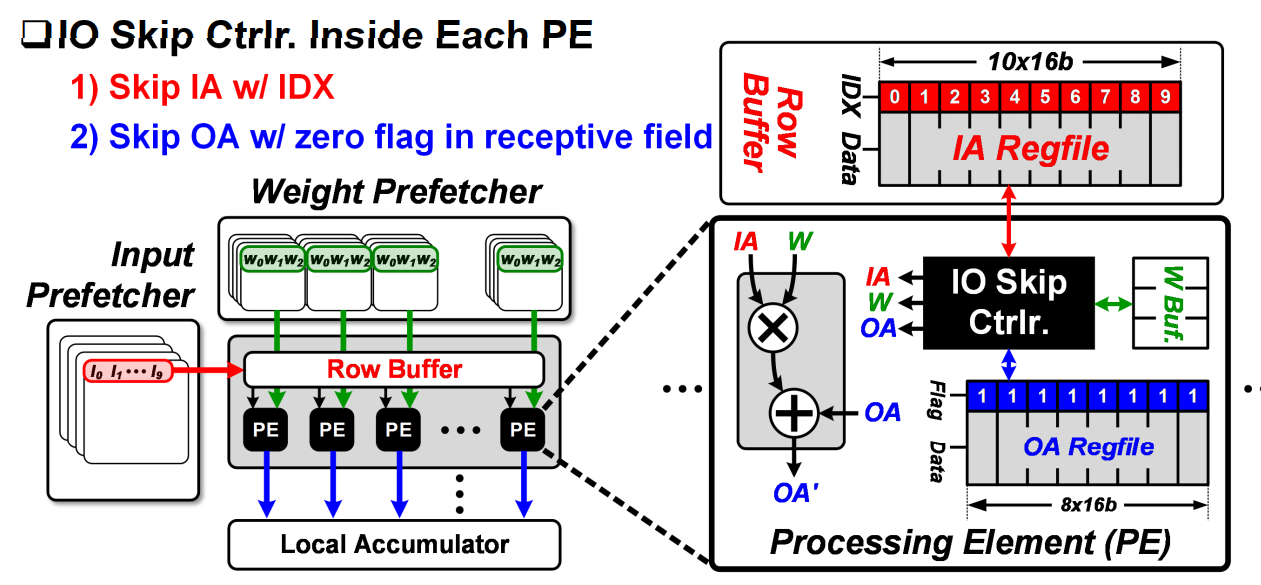
负责输入的Row buffer的每个数据都有两部分,Data和IDX。IDX实际是输入数据的RLC编码。此外,pe内部还有一个8*16b的存储ofmap的OA regfile,跟Row buffer类似,OA regfile的每一个数据都包含了一个Flag,表示这个data是否为0。
pe中的IO skip ctrlr负责利用输入输出的稀疏性。具体工作原理如下:

对于IA的稀疏性计算跟传统RLC编码的稀疏跳过算法类似,根据IDX计算行卷积,结果存入OA buffer中。图中的(O_0 = I_2*W_2,O_1 = I_2 * W_1).而当卷积计算(O_3)时,因为预先通过flag知道这位为0,因此可以直接跳过这步卷积。
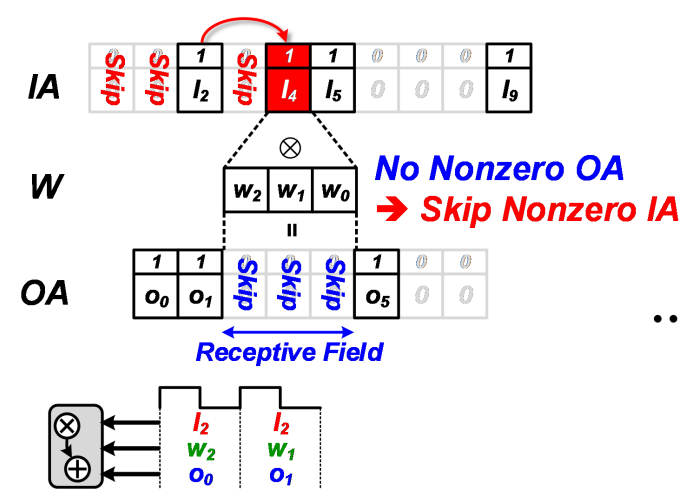
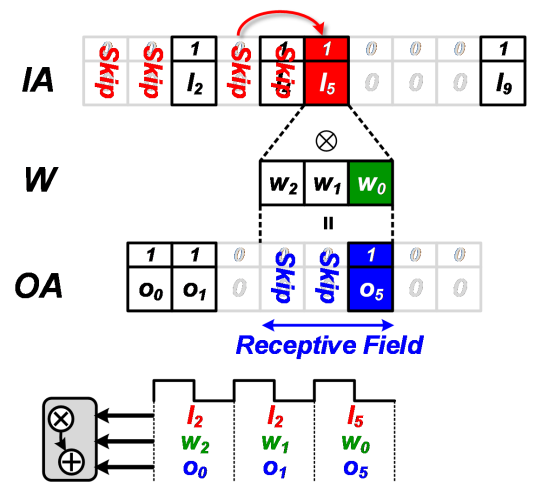
后面的计算类似。因此,对于这组实际长度为10的输入,跟长度为3的卷积核卷积,理论应该计算8次卷积操作,而利用了IA和OA的稀疏性后只需要计算三次卷积。
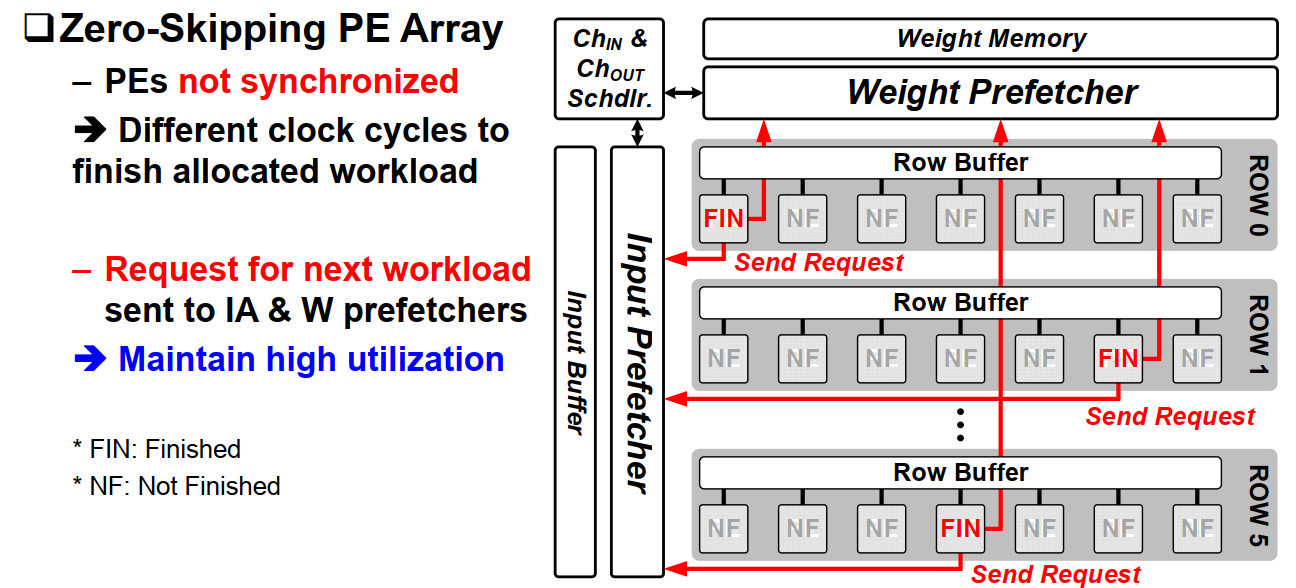
b. IOSC Scheduling
由于考虑了IA和OA的稀疏性,PE之间的计算时间将变得不均衡,这也是稀疏卷积普遍面临的问题。对于某些PE,可能提前其他PE就计算完成了本次计算,这时PE将会向Input Prefetcher 以及 Weight Prefetcher发出预取请求。这两个预取模块将会从memory中将数据提前取出供给结束早的pe,提高了pe的利用率。
c. IOSC performance
IOSC相对于只利用IA或者OA其中一种的方法有较大的提升。极大提升了吞吐率。
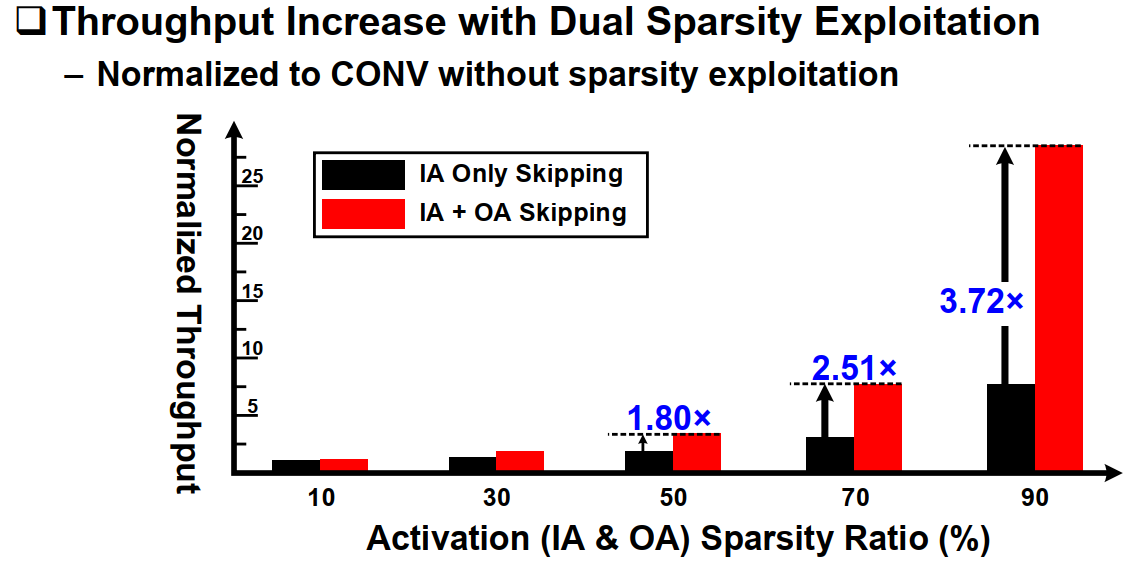
3. Exponent-Only ReLU Speculation
a. 如何判断前向过程OA的稀疏性
上面提到了可以利用OA的稀疏性来优化卷积计算,但前提是得先获得一个当前输出是否为0的信息。在反向过程这个是可以得到的,但在前向过程如何获取呢?下面论文提出了一种基于指数计算的预判机制。

其基本原理是将输入IA以及权重W化为2的指数形式,这在浮点数表示的数据中非常容易,一般浮点数由一个符号位,若干个指数位,剩下的位数表示的是小数部分。具体的浮点数构成见上图。我们只需要提取出每个浮点数的蓝色和绿色部分。
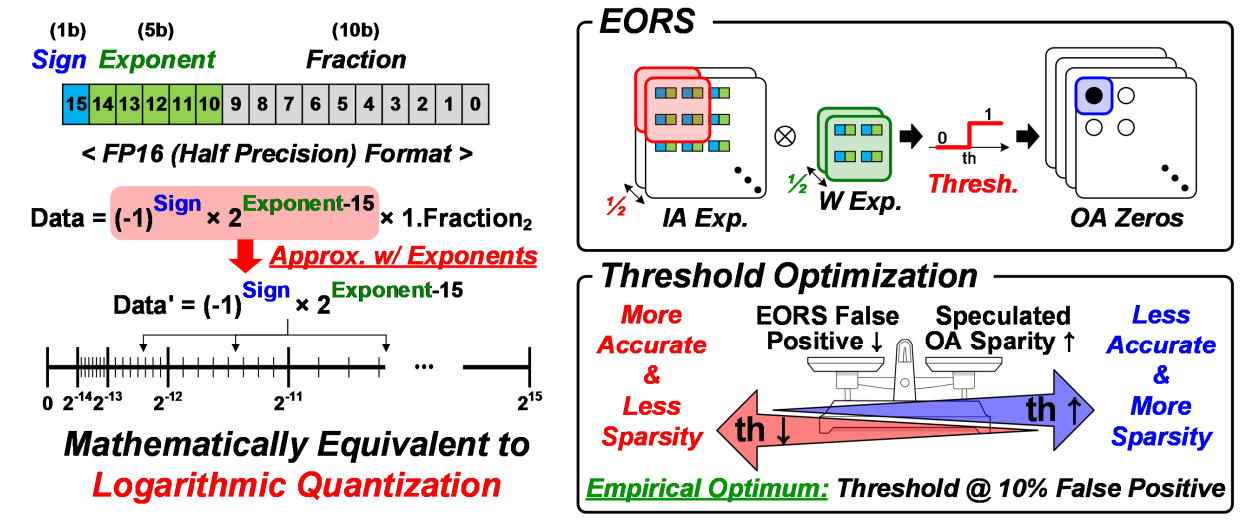
之后,取一半通道的IA和一半通道的Weight做卷积,得到的结果如果不大于一个阈值则认为这次卷积的结果是0。实际上这种方法的思想是如果一半的卷积结果足够负,那么不管剩下的卷积结果是什么,都认为不能左右最终通过relu后的输出结果。
对于这个阈值实际上需要进行一定的权衡,越高的阈值会导致约高的误判,从而导致OA预判错误率提升,虽然OA稀疏性会提高,但不利于网络的准确率。较低的阈值则效果相反。论文经过实验取得的经验阈值是在10%的误判率下取得的。
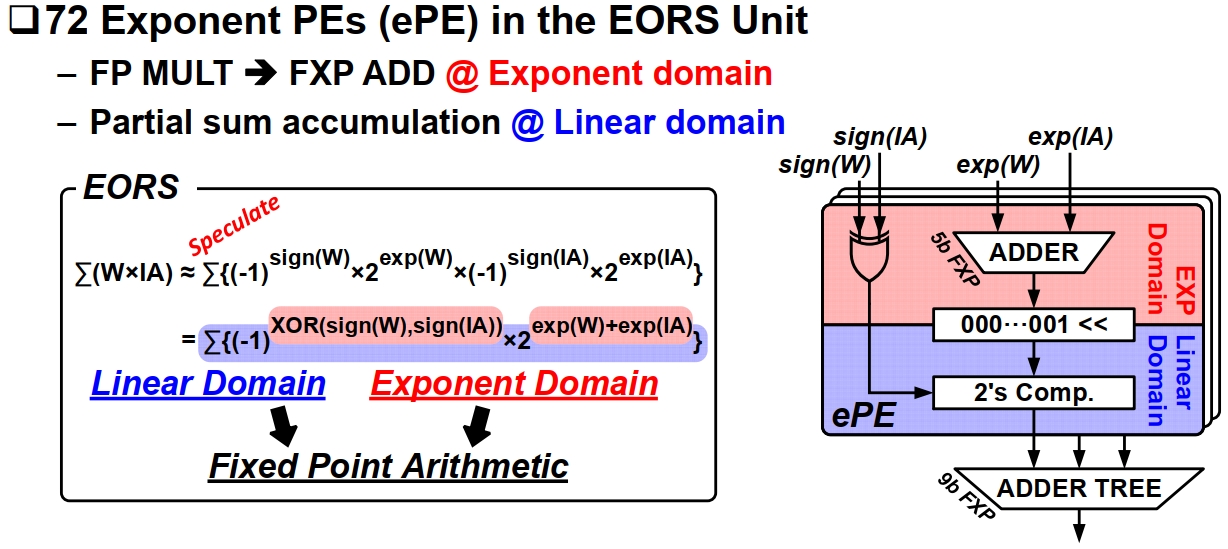
b. EOR unit architecture
EOR单元主要由72个指数计算PE构成。每个PE内部计算2的幂次的乘加,实际上乘法也转换为了加法。因此这部分的代价不会很大。
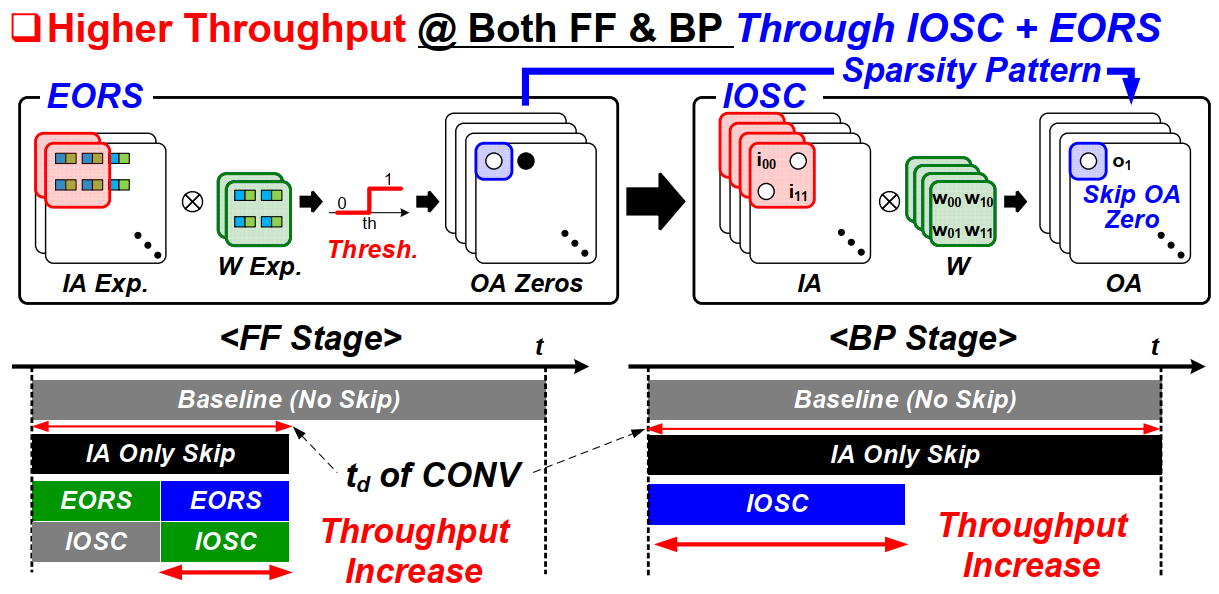
c. Dual Sparsity Exploitation with EORS
EOR+IOSC两种方式结合后,前向计算也能进行OA稀疏性运算。在前向时,EOR先进行运算,紧接着进行IOSC卷积运算,同时下一步卷积的EOR可以跟当前IOSC进行pipline并行计算。
此外,论文也给出了所提出的EOR+IOSC算法对Inference的准确率的影响,结论是在41.24%的平均OA稀疏性下,对网络推理几乎没有影响。

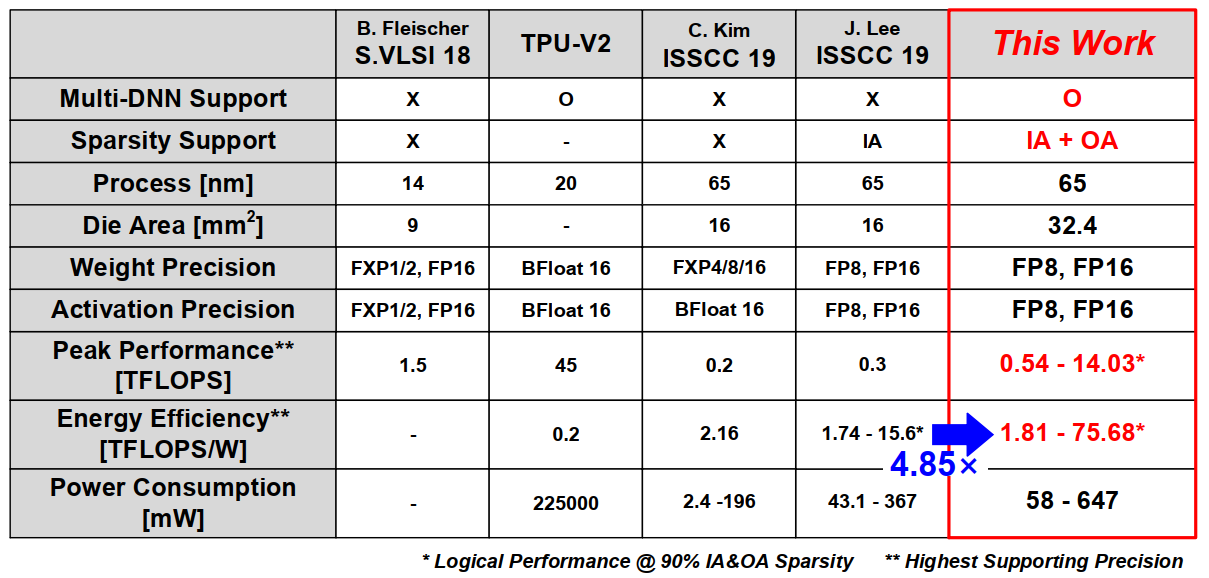
最后是一些整体的性能结果以及对比表格:
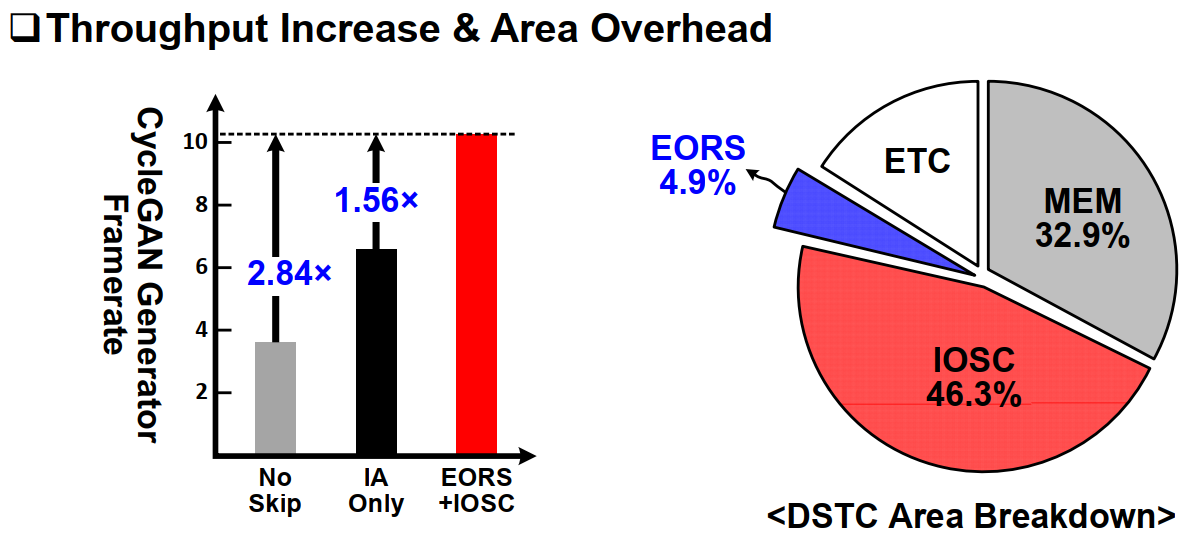
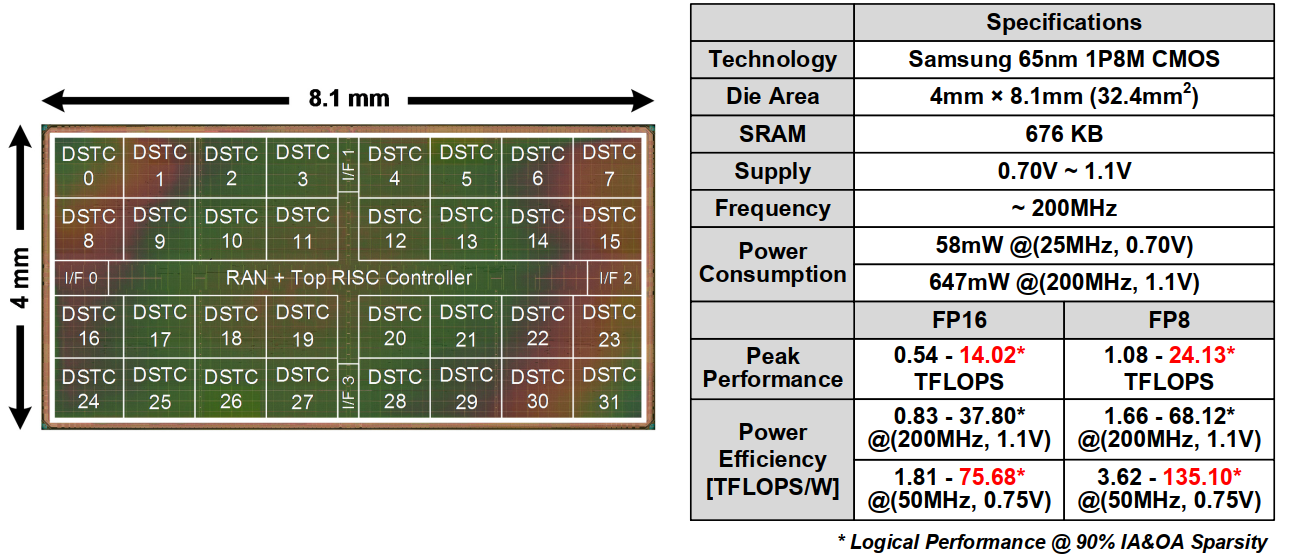
三、Measurement Results
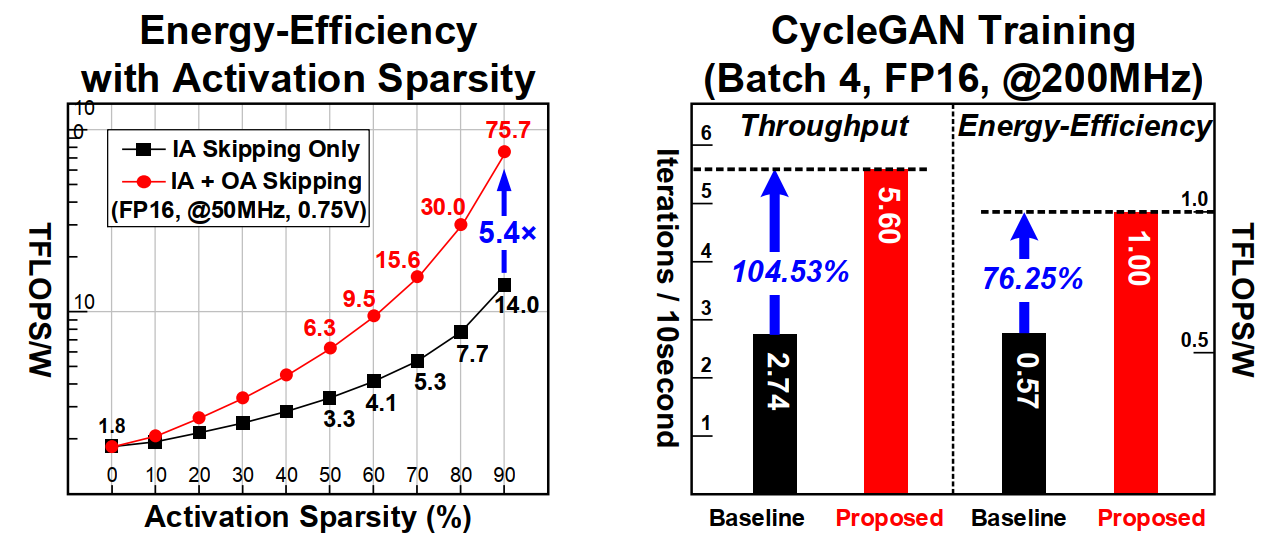
从表格上看,对比19年ISSCC论文(也是他们组的貌似)在能效上有将近5倍的提升。