解剖SQLSERVER 第十四篇 Vardecimals 存储格式揭秘(译)
http://improve.dk/how-are-vardecimals-stored/
在这篇文章,我将深入研究vardecimals 是怎麽存储在磁盘上的。
作为一般的介绍vardecimals 是怎样的,什么时候应该使用,怎样使用,参考这篇文章
vardecimal 存储格式启用了吗?
首先,我们需要看一下vardecimals 是否已经开启了,因为他会完全改变decimals 的存储方式。Vardecimal 不是独立的一种数据类型,所有使用decimals 的列都会使用vardecimals方式来存储并使用相同的system type(106)。注意在SQLSERVER里面,numeric 跟decimal是完全一样的。无论我在哪里我提到decimal, 你都可以使用numeric来替代并且会得到相同的结果
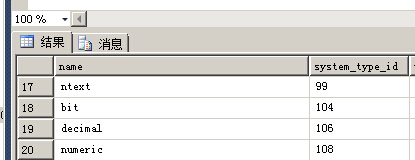
你可以执行下面语句来查看给定的表的vardecimal 是否开启
SELECT OBJECTPROPERTY(OBJECT_ID('MyTable'), 'TableHasVarDecimalStorageFormat')
如果你没有权限运行上面语句,或者不想使用OBJECTPROPERTY函数,你可以查询sys.system_internals_partition_columns DMV 获取同样的信息。
USE test GO SELECT COUNT(*) FROM sys.system_internals_partition_columns PC INNER JOIN sys.partitions P ON P.partition_id = pc.partition_id INNER JOIN sys.tables T ON T.object_id = P.object_id WHERE T.name = 'test_vardecimal' AND P.index_id <= 1 AND PC.system_type_id = 106 AND PC.leaf_offset < 0
固定长度变为可变长度
正常的decimal列在记录里面使用固定长度来存储。这意味着存储的是真正的数据。他不需要保存存储的字节数的长度信息这个长度信息用来计算并存储在元数据里。
一旦你打开vardecimals, 所有的decimals 不再使用固定长度来存储,进而用可变长度代替。
将decimal 作为可变长度字段来存储有一些特别含义
1、我们再也不能使用静态的方法来计算一个给定的值的所需字节数
2、会有两个字节的开销用来存储偏移值在可变长度偏移数组里
3、如果先前行记录没有可变长度列,那么开销实际上是4个字节因为我们也需要存储可变长度列的列数量
4、decimal 的实际值变成了可变数量的字节 这需要我们去解读
vardecimal 值由哪些部分组成
一旦我们开始解析行记录然后在可变长度部分检索vardecimal 的值,我们需要解析里面的数据。
正常的decimals 基本能存储一个巨大无比的整数(范围是根据元数据定义的decimal的位置)
vardecimals 的存储使用科学计数法。使用科学计数法,我们需要存储三个不同的值
1、符号(正数/负数)
2、指数
3、(对数的) 尾数
使用这三个组成部分,我们可以使用下面的公式计算出实际值
(sign) * mantissa * 10<sup>exponent</sup>
例子
假设我们有一个vardecimal(5,2)列,我们存储的值是123.45。在科学记数法里,将表示为1.2345 * 102。
在这种情况下我们有正数符号(1),一个尾数1.2345和一个指数2。SQL Server知道尾数总是有一个固定小数点在第一个数字后面,正因为如此,这会简单的存储整数值12345作为尾数,
当指数是2,SQLSERVER知道我们的范围由指数2来定义,数值向右移动指数的长度,存储0作为实际的指数
一旦我们读取这个数,我使用下面的公式计算尾数(注意我们在这里不关心如果尾数是正的还是负的--我们会稍后将他保存到account里)
mantissa / 10<sup>floor(log10(mantissa))</sup>
将我们的值带入进去,我们得到
12345 / 10<sup>floor(log10(12345))</sup>
通过简化我们得到
12345 / 10<sup>4</sup>
使用科学计数法得到最终的尾数
1.2345
到目前为止一切顺利,我们现在得到尾数的值。在这里我们需要做两件事
1、加上符号位
2、根据指数值将decimal的小数点移动到右边正确的位置。当SQLSERVER知道范围是2,他将2替代4,并减去指数指定的范围--允许我们忽略范围并且只需要直接计算数字
因此我们获得了我们最终需要计算的最后数字
(sign) * mantissa * 10<sup>exponent</sup> => (1) * 1.2345 * 10<sup>2</sup> => 1.2345 * 10<sup>2</sup> = 123.45
读取符号位和指数
第一个字节包含符号和指数。在先前的例子里面,这些值占用4个字节(包含额外的2个字节的偏移数组)
0xC21EDC20
如果我们观察第一个字节,并且将他转换为binary,我们获得下面信息
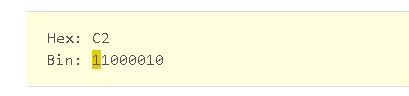

最重要的那个位是最左边的那个位,或者从右开始数第7位(位置编号从0开始)那个位是符号位。如果设置为1表示正数,如果为0表示负数,我们看到是1表示正数
位0 - 6是一个7位的包含指数的值。一个常规的无符号7位值可以包含的范围是0~127。当decimal 数据类型需要表示一个范围 –1038+1到 1038-1,我们就需要存储负数。
我们可以使用7位的其中一位作为符号位,在其余的6位里存储值,允许的范围是–64 到 63。然而SQLSERVER会用尽7位去存储本身的数值,
不过存储的是一个偏移值64。因此,指数0会被存储为64 (64-64=0)。指数-1 会存储63 (63-64=-1),指数1会存储65 (65-64=1)如此类推。
在我们的例子里,读取位0-6 将会得到下面的值

66减去64这个偏移值就得出 指数2
66-64=2(指数)
尾数的chunk存储
余下的字节包含尾数值。我们把他转换为二进制
Hex: 1E DC 20 Bin: 00011110 11011100 00100000
尾数存储在10位的chunks里,每一个chunk显式尾数的3个数字(记住,尾数是一个很大的整数,直到后来我们开始把他作为一个十进制的指针数值 10的n次幂)
把这些字节切割放进去chunks里面 会得到如下的组别
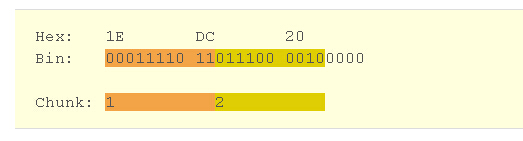
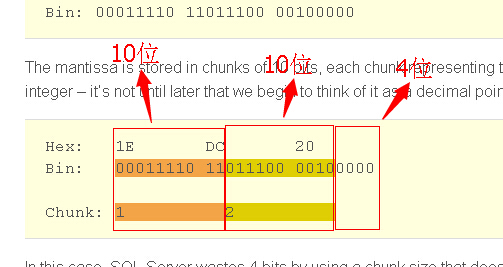
在这种情况下,一个字节8位 SQLSERVER在这里会浪费4位使用这种chunk大小的话。问题来了,为什么要选择一个chunk大小为10位?那10位 需要显示所有可能的三位整数(0-999)。
如果我们使用一个chunk的大小来表示一个数字会怎样?
在这种情况下,一个字节8位 SQLSERVER在这里会浪费4位使用这种chunk大小的话。问题来了,为什么要选择一个chunk大小为10位?那10位 需要显示所有可能的三位整数(0-999)。如果我们使用一个chunk的大小来表示一个数字会怎样?
刚才那样的情况,我们需要展示数值0-9.那总共需要4个位(0b1001 = 9)。然而,使用4个位的时候我们实际可以展示的最大范围是0-15(0b1111 = 15) --意味着我们浪费了6个值的空间(15-9=6)这些值永远不需要的。从百分比来讲,我们浪费了6/16=37.5%
让我们试着画出不同的chunk大小对应浪费的百分比的图:
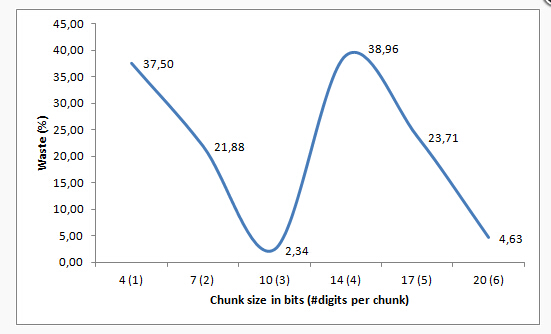
我们看到chunk大小选择4和选择7 相比起选择chunk大小为10 有较大的浪费。
在chunk大小为20时,对于0浪费相当接近,但是他还是有2倍浪费率相比起10来说
现在,浪费不是最重要的。对于压缩来说,最理想的情况是对于绝对必要的数字我们不想使用多余的数字。在chunk大小为10的情况下,可以显示3个数字,我们浪费了2个数字空间范围是0-9。
然而,我们只关注范围100-999。如果我们的chunk大小选择20个位,每个chunk显示6个数字,我们浪费了了一些字节 值从0-99999,当我们只关注值1000000-999999。
基本上,这是一个折衷方案,浪费就越少 而且也越好。我们继续看图表,粒度越来越少。很明显 选择10个位作为chunk的大小是最好的选择 --这个选择的浪费是最小的 并且有合适的粒度大小 3个数字
在我们继续之前还有一些细节。想象一下我们需要存储的尾数值为4.12,有效的整数值是412
Dec: 412 Bin: 01100111 00 Hex: 67 0
在这种情况下,我们会浪费8位在第二个字节,因为我们只需要一个块,但我们需要两个字节来表示这10位。在这种情况下,鉴于过去两位不设置,SQL Server会截断最后一个字节。因此,如果你正在读一块,你的磁盘上,你可以假设其余部分不设置。
在这种情况下,我在第二个字节浪费8个位,因为我们只需要一个chunk,不过我们需要两个字节来显示这个位。在这种情况下,多余的两个位不会进行设置,SQLSERVER会简单的截断最后一个字节。因此,如果你读取一个chunk并且位数已经超出了磁盘的范围,你可以假设剩余的位并没有设置

解析一个vardecimal值
最后,我们准备去解析一个vardecimal 值(使用C#实现)!我们将使用先前的例子,存储123.45值使用decimal(5,2)列。在磁盘上,我们读取下面的字节数组根据调用的顺序
Hex: C2 1E DC 20 Bin: 11000010 00011110 11011100 00100000
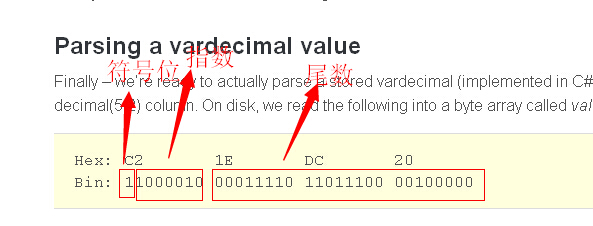
读取符号位
读取符号位相对来说比较简单。我们将只需要在第一个字节上读取:

通过位运算符我们将右移7位,剩下的位是最重要的位。这意味着我们将得到值1 表示正数的符号位,如果是0表示负数

decimal sign = (value[0] >> 7) == 1 ? 1 : -1;
读取指数
下面(技术上来讲这7个位是紧跟着符号位的)的7位包含了指数值

将十六进制值0b1000010 转换为进制值得到的结果是66.我们知道指数总是有偏移值64,我们需要将存储的值减去64从而得到实际值:
Exponent = 0b1000010 – 0n64 <=> Exponent = 66 – 64 = 2
读取尾数
接下来就是尾数值。前面提到,我们需要读取一个10个位的chunk,并且需要注意那些被截断的部分
首先,我们需要知道有多少有用的位。这样做很简单,我们只需简单的将尾数的字节数(除了第一个字节之外的所有字节)乘以8
int totalBits = (value.Length - 1) * 8;
一旦我们知道有多少位是可用的(在这个例子里 2个chunk 24位=3个字节* 8位),我们可以计算chunks的数目
int mantissaChunks = (int)Math.Ceiling(totalBits / 10d);
因为每个块占用10位,我们只需要的比特总数除以10。如果有填充最后,匹配一个字节边界,它将是0的,不会改变最终的结果。因此为2字节尾数我们将有8位备用,将非标准都是0。
对于一个3字节尾数我们将有4位,再次添加0尾数总额。
因为每个chunk占用10个位,我们只需要除以将位的总数除以10。如果在结尾有占位,为了匹配位的边界,SQLSERVER会填充0但是这个不会影响上面公式得出的结果。
因此,对于一个2个字节的尾数我们会有8bit(这里作者是不是错了?应该是6bit吧) 是剩余的,这些剩余位都会被无意义的0填充。对于一个3字节 的尾数我们会有4bit 剩余,
再一次在总的尾数值上填充0
这里我们准备读取chunk的值。在读取之前,我们需要分配两个变量
decimal mantissa = 0; int bitPointer = 8;
可变长的尾数值是由尾数值进行累加的,每次我们读取一个新10-bit chunk值就累加一次。bitPointer 是一个指针指向当前读取到的位。
我们不准备读取第一个字节,我们会从第8位开始读取(从0开始数,因此第8位 =第二个字节的第一位)
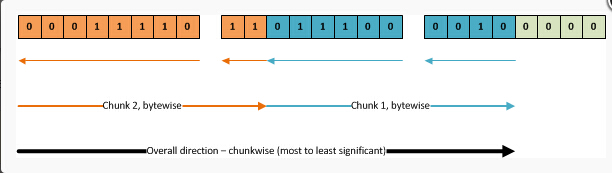
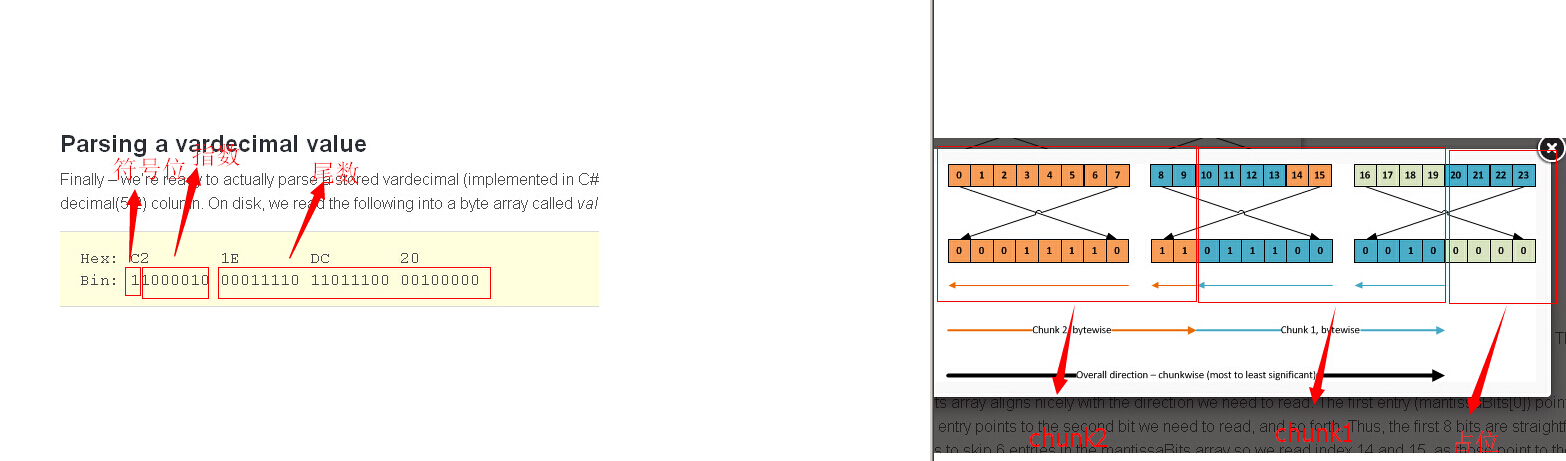
看一下这些位 他们可以简单的看成是一条long stream --我们只需要从左到右进行读取,对吧?不完全是,你可否记得,最右边的位是最重要的,
因此最右边的位应该是我们最先要读取的。然而,我们需要一次读取一个字节。同样,整体的方向是按chunk为单位的话是从左到右读取。
一旦我们达到chunk的位置,我们每次就需要一个字节一个字节地读取。bits1-8 在第一个字节里读取,bits9-10 在第二个字节里读取,
下面图片中橙色的箭头(最大的那个箭头指示字节读取顺序(chunkwise)从左向右,而每个独立的字节内部的读取顺序是小箭头那个 从右向左)
为了方便访问所有的bits,和避免做太多的人工的位移操作,我实例化一个BitArray 类 ,这个类包含了所有的数据位:
var mantissaBits = new BitArray(value);
使用这个类,你必须知道bit 数组如何跟字节进行映射。形象的描述,他会像下面那样,mantissaBits 数组指针在图片的上面:
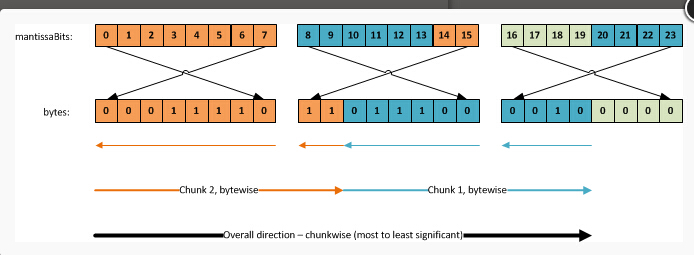
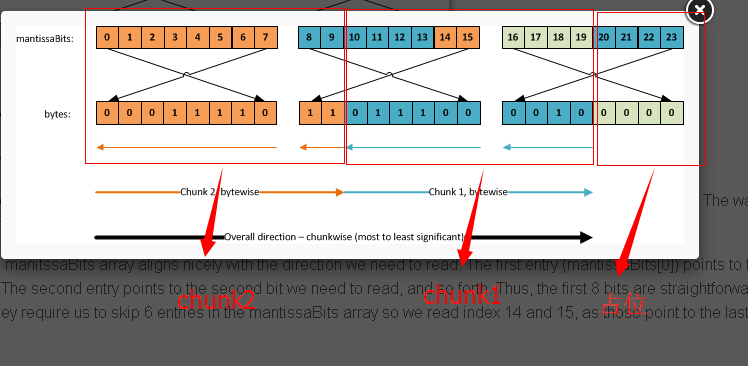
我知道这看起来很复杂,不过所有这些复杂的事情只不过是需要知道指针的指向。我们的代码里面是字节数组。
我们访问每一个独立的bits的方式是通过mantissaBits 数组,这个数组只是一个很大的指向独立的bits的数组指针。
看一下第一个8 bits,manitssaBits 数组按照我们的读取方向很好地排列。第一个条目(mantissaBits[0])指向
第一个字节的最右一位。第二个条目指向第二个字节,以此类推。因此,第一个8 bits是直接读取的。然而,后面的两个,在manitssaBits 数组里面他们需要
我们跳过6个条目以至于我们读取条目14和15,他们指向下一个字节的最后两个bits(因为是从右向左读取的)。
读取第二个chunk,我们必须回去读取bit 条目8-13 然后跳到条目20-23,忽略条目16-19 因为他们只是不相关的占位padding。
这是相当棘手的。幸运的是我们可以自由选择从重要的位到不重要的位进行读取,或者相反
让我们看一下代码实现
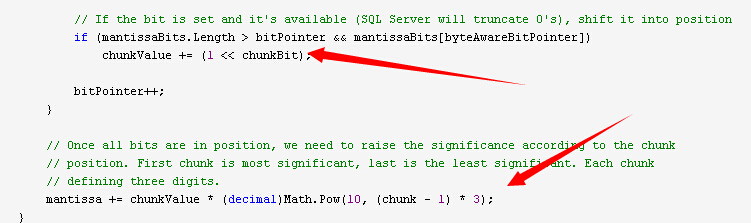
for (int chunk = mantissaChunks; chunk > 0; chunk--) { // The cumulative value for this 10-bit chunk decimal chunkValue = 0; // For each bit in the chunk, shift it into position, provided it's set for (int chunkBit = 9; chunkBit >= 0; chunkBit--) { // Since we're looping bytes left-to-right, but read bits right-to-left, we need // to transform the bit pointer into a relative index within the current byte. int byteAwareBitPointer = bitPointer + 7 - bitPointer % 8 - (7 - (7 - bitPointer % 8)); // If the bit is set and it's available (SQL Server will truncate 0's), shift it into position if (mantissaBits.Length > bitPointer && mantissaBits[byteAwareBitPointer]) chunkValue += (1 << chunkBit); bitPointer++; } // Once all bits are in position, we need to raise the significance according to the chunk // position. First chunk is most significant, last is the least significant. Each chunk // defining three digits. mantissa += chunkValue * (decimal)Math.Pow(10, (chunk - 1) * 3); }
外层循环遍历chunks,从最重要的到不重要的chunk。这里我们先遍历chunk2再遍历 chunk1
chunkValue 这个变量保存我们当前正在读取的chunk的所有值。我们会进行移位操作把位的值赋值给chunkValue (chunkValue += (1 << chunkBit);)
直到已经解析完所有的10个bits
内层循环从最重要的bit到不重要的bit(就是说,在chunkbit里从条目9到条目0)。最右边的位开始倒序读取,我们避免跳过内部的单个字节。
我们在mantissaBits数组中总是从右到左读取bits,下面顶层的箭头就像这样:
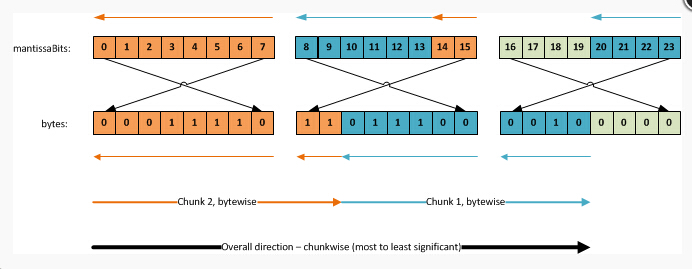
虽然我们倒序读取每个字节里面的bit,其他的东西都是以自然方式读取,这让解析更加容易
byteAwareBitPointer 变量在我们的 mantissaBits数组里面是一个指针指示我们当前读取到的值。
这种计算确保我们读取每一个字节的时候都是从mantissaBits数组里最高位读取到最低位。下面是读取到的第一个chunk里面按mantissaBit 指针顺序的条目值
7, 6, 5, 4, 3, 2, 1, 0, 15, 14
和第二个被读取到的chunk 按mantissaBit 指针顺序的条目值
13, 12, 11, 10, 9, 8, 23, 22, 21, 20
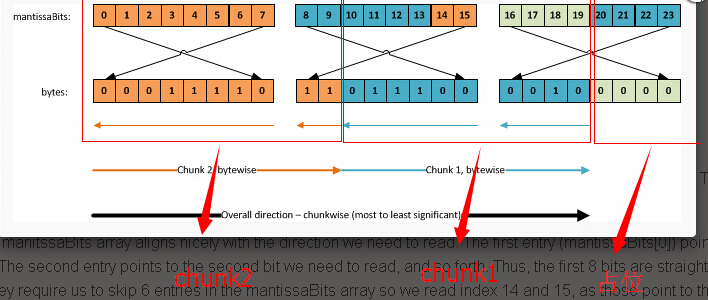
一旦我们读取到特定的bit,我们进行移位把值保存到chunkValue 变量里--但只有这个位是可用的才会保存到chunkValue 变量(也就是说0不会保存并被截断)
一旦所有的bits都已经进行了移位,我们把chunk的值赋值给mantissa 。在我们的例子里,存储的值是12345,我们实际上
存储的值是123450(因为每一个chunk存储三个数字,这总是3的倍数)。第一个读取到的chunk(chunk2)包含值123 对应值是123000。
第二个读取到的chunk(chunk1)包含的值是450。乘以10(chunk–1)<3
确保我们获取到正确的数量级(1000 for chunk 2 and x1 for chunk 1*)。对于每次的chunk循环,我们会添加最后的chunk值到尾数(mantissa )里最后进行相加
mantissa = mantissa / 10<sup>floor(log10(mantissa))</sup>
实现代码如下:
mantissa = mantissa / (decimal)Math.Pow(10, Math.Floor(Math.Log10((double)mantissa)));
尾数的结果值是1.2345
尾数的解析性能
这个实现的性能谈不上快,在你打击我之前有些说话我需要说。首先,我们可以容易地将整组bits一次性进行移位而不是每次移位。
确保每个chunk不需要两次或以上的移位操作,在这个实现里面使用了10次移位操作(因为每个chunk是10个bits)。
然而,我的目的是这个代码实现是为了代码的清晰和可读性。我的目的不是为了对OrcaMDF进行速度的优化
将这些东西全部结合起来
一旦我们有了符号位,指数,尾数,我们可以简单的计算最后的值就像这样:
return sign * mantissa * (decimal)Math.Pow(10, exponent);
在我们的例子里,结果将是这样:
1 * 1.2345 * 10<sup>2</sup> = 1.2345 * 100 = 123.45
结论
Vardecimal 是SQL2005 SP2唯一的压缩功能。到了SQL2008我们才有 行压缩和页压缩功能(这两个特性是vardecimal存储格式的超集)。
从那时起, 随着行压缩和页压缩的发布,微软已经把vardecimal 作为废弃功能,并且在将来的版本会删除这个功能。
因为Vardecimal 需要企业版才能使用,而行压缩和页压缩也是需要企业版,我们没有理由去使用Vardecimal 功能,除非你使用的是SQL2005
或者除非你有一个非常特别的数据集除了使用decimals压缩功能没有其他的功能能带来性能提升。
知道vardecimal 的存储格式是如何工作的对于研究压缩的内部是有好处的--压缩内部我将会写一篇文章 并且我将会在2012年春季的SQL Server Connections里进行演示
同时你可以github上在签出我的SqlDecimal.cs 实现。或者你可以看一下OrcaMDF 代码里的完整实现
using System; using System.Collections; namespace OrcaMDF.Core.Engine.SqlTypes { public class SqlDecimal : ISqlType { private readonly byte precision; private readonly byte scale; private readonly bool isVariableLength; public SqlDecimal(byte precision, byte scale) : this(precision, scale, false) { } public SqlDecimal(byte precision, byte scale, bool isVariableLength) { this.precision = precision; this.scale = scale; this.isVariableLength = isVariableLength; } public bool IsVariableLength { get { return isVariableLength; } } public short? FixedLength { get { return Convert.ToInt16(1 + getNumberOfRequiredStorageInts() * 4); } } private byte getNumberOfRequiredStorageInts() { if (precision <= 9) return 1; if (precision <= 19) return 2; if (precision <= 28) return 3; return 4; } public object GetValue(byte[] value) { if(!isVariableLength) { if (value.Length != FixedLength.Value) throw new ArgumentException("Invalid value length: " + value.Length); int[] ints = new int[4]; for (int i = 0; i < getNumberOfRequiredStorageInts(); i++) ints[i] = BitConverter.ToInt32(value, 1 + i * 4); var sqlDecimal = new System.Data.SqlTypes.SqlDecimal(precision, scale, Convert.ToBoolean(value[0]), ints); // This will fail for any SQL Server decimal values exceeding the max value of a C# decimal. // Might want to return raw bytes at some point, though it's ugly. return sqlDecimal.Value; } else { // Zero values are simply stored as a 0-length variable length field if (value.Length == 0) return 0m; // Sign is stored in the first bit of the first byte decimal sign = (value[0] >> 7) == 1 ? 1 : -1; // Exponent is stored in the remaining 7 bytes of the first byte. As it's biased by 64 (ensuring we won't // have to deal with negative numbers) we need to subtract the bias to get the real exponent value. byte exponent = (byte)((value[0] & 127) - 64); // Mantissa is stored in the remaining bytes, in chunks of 10 bits int totalBits = (value.Length - 1) * 8; int mantissaChunks = Math.Max(totalBits / 10, 1); var mantissaBits = new BitArray(value); // Loop each chunk, adding the value to the total mantissa value decimal mantissa = 0; int bitPointer = 8; for (int chunk = mantissaChunks; chunk > 0; chunk--) { // The cumulative value for this 10-bit chunk decimal chunkValue = 0; // For each bit in the chunk, shift it into position, provided it's set for (int chunkBit = 9; chunkBit >= 0; chunkBit--) { // Since we're looping bytes left-to-right, but read bits right-to-left, we need // to transform the bit pointer into a relative index within the current byte. int byteAwareBitPointer = bitPointer + 7 - bitPointer % 8 - (7 - (7 - bitPointer % 8)); // If the bit is set and it's available (SQL Server will truncate 0's), shift it into position if (mantissaBits.Length > bitPointer && mantissaBits[byteAwareBitPointer]) chunkValue += (1 << chunkBit); bitPointer++; } // Once all bits are in position, we need to raise the significance according to the chunk // position. First chunk is most significant, last is the least significant. Each chunk // defining three digits. mantissa += chunkValue * (decimal)Math.Pow(10, (chunk - 1) * 3); } // Mantissa has hardcoded decimal place after first digit mantissa = mantissa / (decimal)Math.Pow(10, Math.Floor(Math.Log10((double)mantissa))); // Apply sign and multiply by the exponent return sign * mantissa * (decimal)Math.Pow(10, exponent); } } } }
可能大家不是很明白尾数的计算方式
尾数部分:00011110 11|011100 0010|0000
字节1:00011110
字节2:11011100
字节3:00100000
chunk分隔线:|
chunk2:00011110 11 转换为十进制 123 然后再乘以10的3次方 123 * 103 =123000
chunk1:011100 0010 转换为十进制 450 然后再乘以10的1次方 450 * 101 =450
chunk2+chunk1=123450

第十四篇完