参考书
《TensorFlow:实战Google深度学习框架》(第2版)
一个简单的程序来生成样例数据。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_produce1.py @time: 2019/2/3 21:46 @desc: 一个简单的程序来生成样例数据 """ import tensorflow as tf # 创建TFRecord文件的帮助函数 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 模拟海量数据情况下将数据写入不同的文件。num_shards定义了总共写入多少个文件 # instances_per_shard定义了每个文件中有多少个数据 num_shards = 2 instances_per_shard = 2 for i in range(num_shards): # 将数据分为多个文件时,可以将不同文件以类似0000n-of-0000m的后缀区分。其中m表示了 # 数据总共被存在了多少个文件,n表示当前文件的编号。式样的方式既方便了通过正则表达式 # 获取文件列表,又在文件名中加入了更多的信息。 filename = ('./data.tfrecords-%.5d-of-%0.5d' % (i, num_shards)) writer = tf.python_io.TFRecordWriter(filename) # 将数据封装成Example结构并写入TFRecord文件 for j in range(instances_per_shard): # Example结构仅包含当前样例属于第几个文件以及是当前文件的第几个样本 example = tf.train.Example(features=tf.train.Features(feature={ 'i': _int64_feature(i), 'j': _int64_feature(j) })) writer.write(example.SerializeToString()) writer.close()
运行结果:
![]()
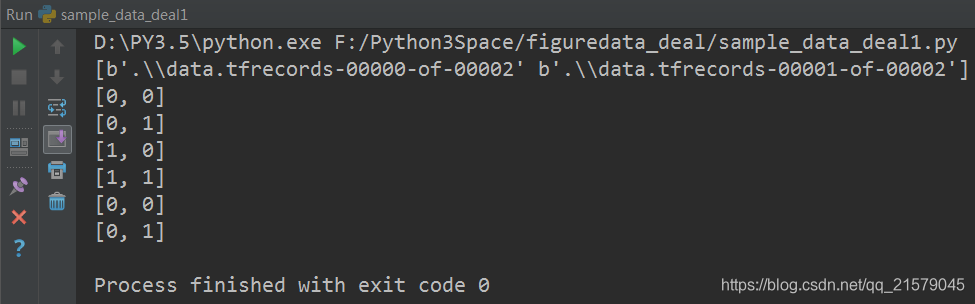
展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_deal1.py @time: 2019/2/3 22:00 @desc: 展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法 """ import tensorflow as tf # 使用tf.train.match_filenames_once函数获取文件列表 files = tf.train.match_filenames_once('./data.tfrecords-*') # 通过tf.train.string_input_producer函数创建输入队列,输入队列中的文件列表为 # tf.train.match_filenames_once函数获取的文件列表。这里将shuffle参数设为False # 来避免随机打乱读文件的顺序。但一般在解决真实问题时,会将shuffle参数设置为True filename_queue = tf.train.string_input_producer(files, shuffle=False) # 如前面所示读取并解析一个样本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) with tf.Session() as sess: # 虽然在本段程序中没有声明任何变量,但使用tf.train.match_filenames_once函数时 # 需要初始化一些变量。 tf.local_variables_initializer().run() print(sess.run(files)) # 声明tf.train.Coordinator类来协同不同线程,并启动线程。 coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 多次执行获取数据的操作 for i in range(6): print(sess.run([features['i'], features['j']])) # 请求处理的线程停止 coord.request_stop() # 等待,直到处理的线程已经停止 coord.join(threads)
运行结果:
![]()