第3章 分类
写在前面
参考书
《机器学习实战——基于Scikit-Learn和TensorFlow》
工具
python3.5.1,Jupyter Notebook, Pycharm
问题解决
-
MNIST数据报错:[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
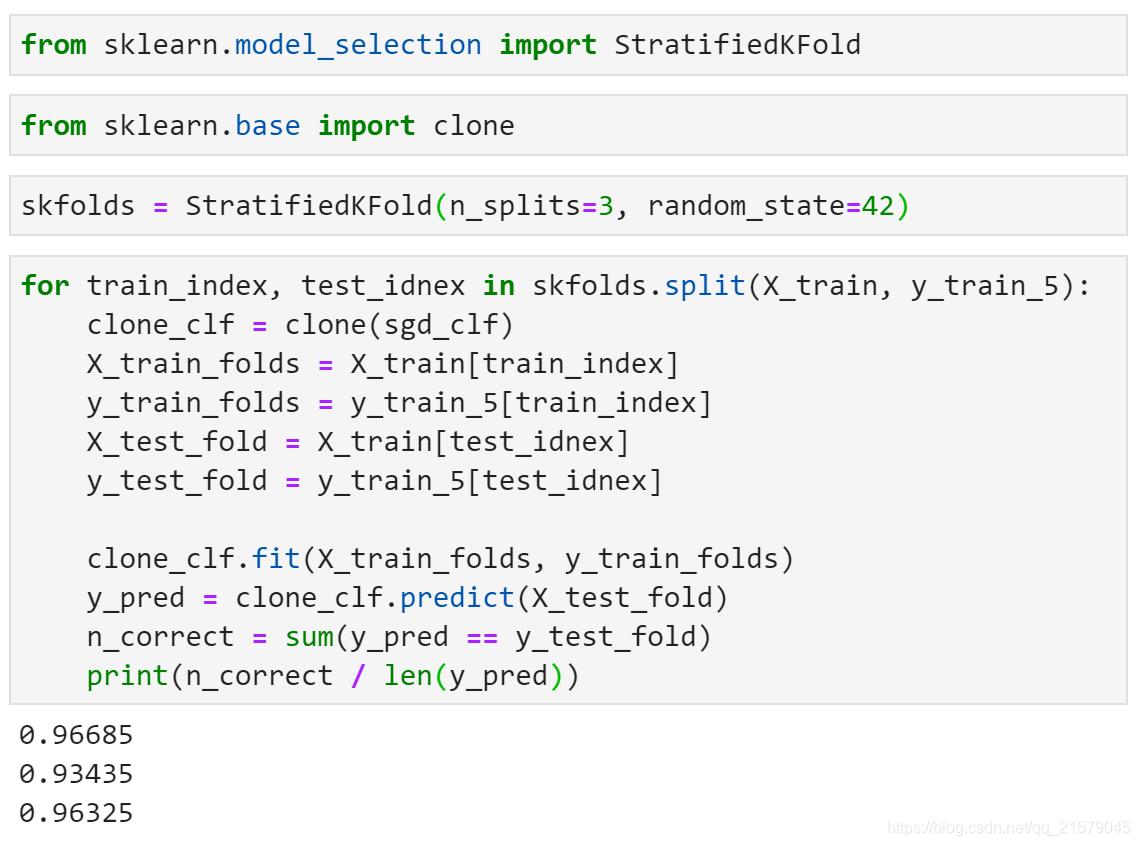
StratifiedKFold
- 相比于cross_val_score()这一类交叉验证函数,该函数可以让你能控制的更多一些,你可以自行实施交叉验证。
cross_val_predict
- 返回的不是评估分数,而是每个折叠的预测值
- 得到的是一维数组,你想啊,多折之后每个样本都会且仅会成为一次验证集,所以,得到的是跟原样本数量一致的预测的label
confusion_matrix
- 混淆矩阵
- 混淆矩阵中的行表示实际类别,列表示预测类别。
decision_function()
-
该方法返回每个实例的分数,然后就可以根据这些分数,使用任意阈值进行预测。
-
使用cross_val_predict()函数获取训练集中所有实例的分数
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") -
有了这些分数,可以使用precision_recall_curve()函数来计算所有可能的阈值的精度和召回率
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="Precision") plt.plot(thresholds, recalls[:-1], "g-", label="Recall") plt.xlabel("threshold") plt.legend(loc = "upper left") plt.ylim([0, 1]) plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
roc_curve()
-
受试者工作特征曲线
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') plt.axis([0, 1, 0, 1]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plot_roc_curve(fpr, tpr) plt.show()
roc_auc_score()
- 有一种比较分类器的方法是测量曲线下面积(AUC)
- 完美的分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。
- from sklearn.metrics import roc_auc_score
ROC和PR曲线的选择
- 由于ROC曲线与精度/召回率(PR曲线)非常相似,因此你可能会问如何决定使用哪种曲线。
- 有一个经验法则是,当正类非常少见或者你更关注假正类而不是假负类时,你应该选择PR曲线;反之则是ROC曲线。PR曲线越接近右上角越好。
多类别分类器
-
sklearn可以检测到你尝试使用二元分类算法进行多类别分类任务,它会自动运行OvR(SVM分类器除外,它会使用OvO)。
-
如果想要强制sklearn使用一对一或者一对多策略,可以使用OneVsOneClassifier或OneVsRestClassifier类。
from sklearn.multiclass import OneVsOneClassifier ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42)) ovo_clf.fit(X_train, y_train) ovo_clf.predict([some_digit]) len(ovo_clf.estimators_)
错误分析
- cross_val_predict() + confusion_matrix()
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友