模块
模块的分类 :
内置模块 : 安装python解释器时跟着装的
第三方模块/扩展模块 :没在安装python解释器的时候装的功能
自定义模块 : 自己写的模块文件
什么是 模块 :
有的功能开发者自己无法完成,这样的话需要借助 已经实现的函数或类 来完成这些功能;
你实现不了的功能都由 别人替你实现了;
别人写好的一组功能 : 包括 文件夹 / py文件 / c语言 编译好的编译文件
这样可以 分类管理方法 节省内存 提供更多的功能
模块名:
模块文件名 和变量的名的命名规则 一样 一般情况下 小写字母开头
如何使用模块 ?
import 模块名 # 导入模块
模块名 . 方法名() # 调用模块中的方法名
模块名 . 变量名 # 得到 模块中的变量 的值
import 模块名 这一步做了什么:?
1. 首先 找到这个模块
2. 创建一个属于 这个模块的 一个内存空间
将里边的 变量或方法存到空间中 若 模块中有两个 同名的变量 则会将第一个变量覆盖
3. 执行 这个模块中的内容
4. 将这个模块 所在的命名空间 建立一个 和 模块名 之间的 引用关系
在模块中 调用方法是 首先找的 也是 模块中的变量
模块的重命名: 改的 是 主要文件中 引用模块时 引用的名字
导入多个模块: 用 , 隔开
import 模块1 , 模块2
但是在 PEP8规范中 , 不允许 一行导入 多个模块
所有的模块 都应 尽量放在这个文件夹开头 以便 使用文件 及使用功能 的人 清楚 用了什么模块
模块的导入顺序:
内置模块 = = == 第三方模块 = = ==== 自定义模块
自己可以创建一个my_module.py文件, 里边添加 代码 将其当成模块导入执行
主要文件 my_moudle模块文件
import my_module #执行===>额 print('额')
my_module.login()#调用模块中的login()===>登录,alex def login():
print('登录',name)
name='' alex ''
模块重命名:
import module as n
那么 调用模块中函数或者方法
n . login() 或 print(' n.name ')

from 模块名 import 方法名或变量名
有时候 会有红色的线 不是 python解释器 发现的错误 而是 pycharm根据它的一些判断 得出的结论
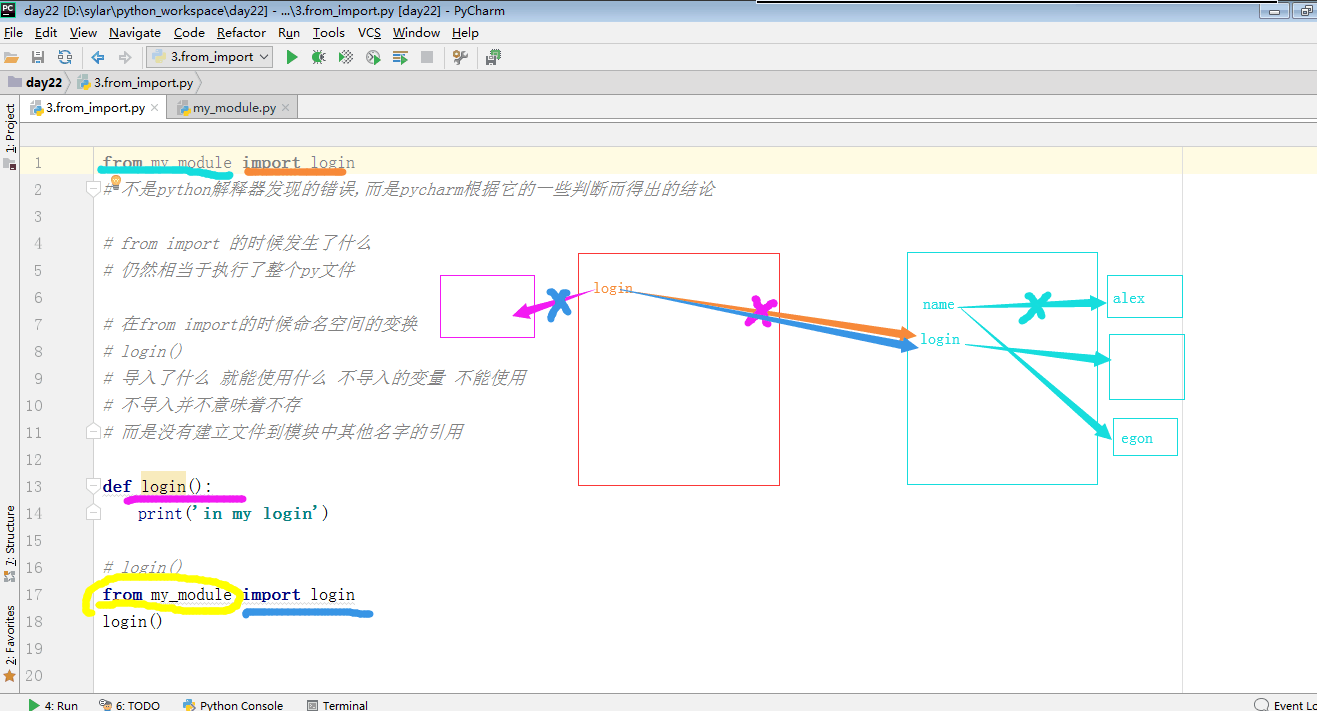
from my_module import login
from ... import ... 的时候发生了什么?
仍然相当于 执行了整个 .py 文件
在 from import 的时候 命名空间的变换 :
1. 直接 login() 就可以调用方法
2. 导入了什么 , 就能使用什么 ,
不导入的变量 , 不能用 , 但是不导入 并不意味着 不存
而是 没有 建立文件 到 模块中其他的名字引用
3. 当 模块中导入的 方法 或者 变量 和本文件重名时
那么 这个名字代表 最后一次 对他赋值的那个方法或变量
4. 在本文件中对 全局变量的修改是 完全不会 影响到 模块中的变量引用的
重命名:
from my_module import login as m
那么 以后引用就会变成 m() 模块中的名字是不变的 变得是引用的时候用到名字
导入多个:
from my_module import login , name
login()===> 模块中的login
print(name) ===> 指向模块中的 name
name =' 太亮 ' ====> 指向 新的 name
login() ===> 指向 模块中的 login
导入多个模块之后重命名
from my_module import login as l , name as n
变得也是引用中的 名字 , 不是模块中的名字
from 模块名 import *
from my_module import *
login()
name 两个都可以 引用
__all__可以控制导入的内容 _ _all__中必须是 [ ' 变量名' ]
若模块中 有个 __all__[ ' login ' ]
这样的话name 就不能用了
若想用就重新导入一次
from my_module import name
login的指向 :
若在自己空间添加一个 login函数 则会开一个 空间
里边装的是login会指向自己定义函数的空间,
原来的指针会断 当再次导入 一次模块的时候 那个指针就会断开 指向模块的 login空间
from my_module import login my_module
def login(): def login():
print( ' in my logion ' ) print( ' 我 ' )
login() ====> in my login # 执行的是 自己文件中的 函数
def login():
print( ' in my login ' )
from my_module import login
login() ====> 我 # 执行的是模块中的 函数
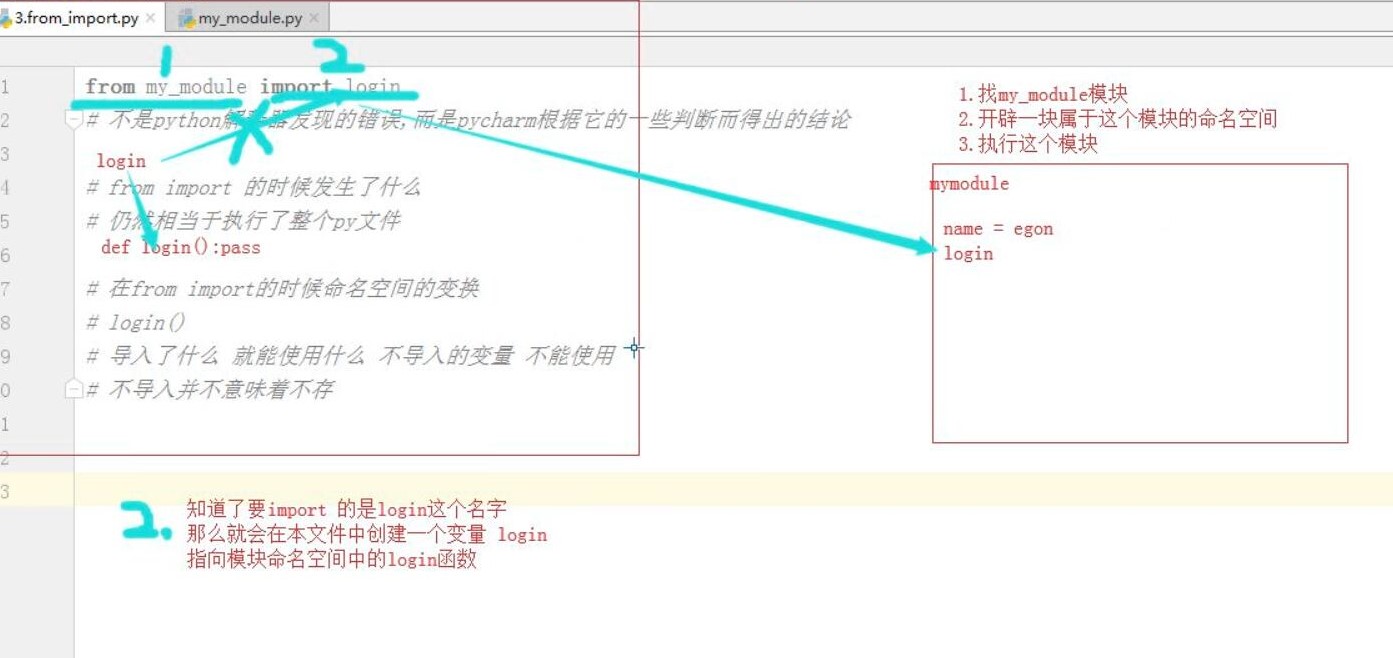
1. from my_module import login 执行这句话时 干了什么?
1. 先找到 my_module 模块
2. 开辟一块属于这个模块的命名空间
3. 执行这个模块
2. 知道了 要import 的是login这个名字 那么就会
在本文件中创建一个变量 login
这个login 指向 模块命名空间中的 login函数
若一个模块中有两个 name 开辟空间的时候 执行到name 的时候先指向的是第一个名字 ,
当再执行到name= -***的时候 那个指针会断开原来的 指向另外一个名字
模块的其他相关知识
1. 把模块当成脚本运行: 从本模块中反射本模块的变量
运行 py文件的两种方式:
1. import my_module
if __name__=" __main__" 在编写py文件的时候
所有不在函数中和类中 封装的内容 都应该写在 if __name__=" __main__" : 下边
所有不需要调用的内容
你希望某段代码 在被当做模块导入的时候 ,不要执行 ,就把他放到if name判断下边
import sys
import my_moudle
sys: 文件的内存地址
my_moudle : my_moudle 的地址
"__main__" : 当前直接执行 的文件所在的地址 : 存储了所有导入的文件的名字和这个文件的内存地址
当再使用反射自己模块中的内容的时候
import sys
getattr( sys.moudle[__name__] , ' 变量名' )( )
sys.moudle[__name__] 这句话写在哪个文件里 ,就代表是那个文件的命名空间
模块搜索路径
正常情况下 应该 import sys print( sys.path )
但是 全部在 sys.path 在pycharm 中的路径是不可靠的
模块没有导入之前 在哪?
在硬盘上
一个自定义模块 是否能够被导入 就看 sys.path列表中有没有这个模块 所在的绝对路径
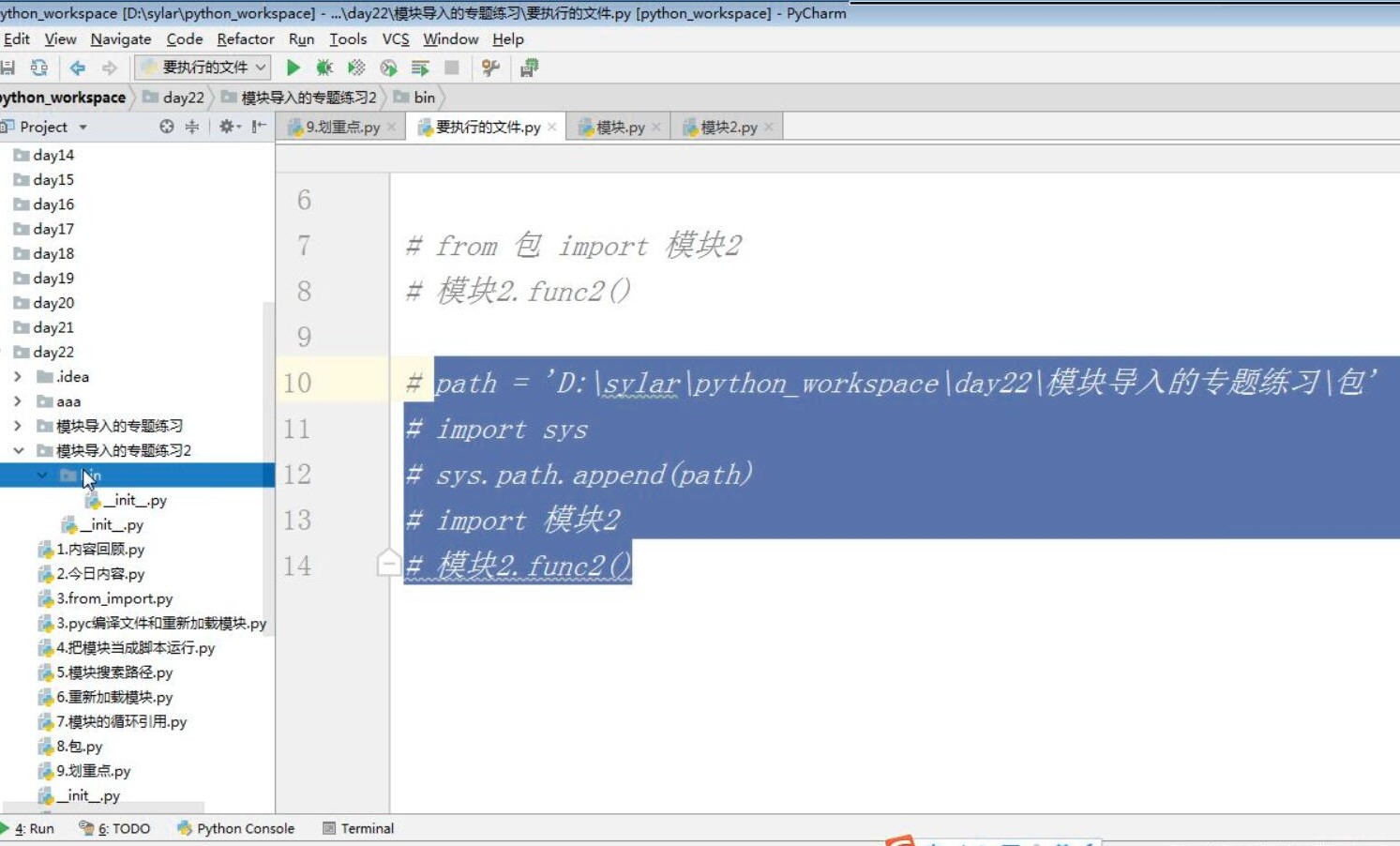
总结:
1. 模块的搜索路径 全部存在 sys.path列表中
2. 如果要导入的模块和当前执行的文件同级 , 直接导入就可以了
3. 如果要导入的模块 和当前执行的文件不同级, 那么
需要把导入的模块的绝对路径
添加到 sys.path列表中 找到导入模块 右键单击 copy path 让 path=粘贴的copy path 将其添加到sys.path列表中看上边截图
4. 导入模块的顺序 是从前到后 找到一个复合条件的模块 就立即停止, 不再向后寻找
一个自定义模块 是否能够被导入 就看 sys.path列表中有没有这个模块 所在的绝对路径
pyc编译文件
import aaa #模块导入的时候
python的执行 : 解释器 - - 编译
1. 当一个文件 作为一个脚本 被导入的时候 , 就会在这个文件 所在
目录下的pycharm下生成一个编译好的文件
2. 为了导入这个文件的时候可以直接读这个编译好的pyc文件 就可以了
3. 这样可以节省 一些导入的时间
重新加载文件
导入行为 不会随着文件的改变而改变
也就是说 在import 一个模块文件之后 , 再修改这个被导入的模块文件 程序是感知不到的
但是 reload 这种方式可以强制 程序 再重新 导入这个模块一次
但是 非常不推荐使用这种方法
e.g
import aaa # 导入模块aaa
import time # 导入时间模块
import importlib
aaa.login() # 调用 aaa中的logi ====> 123 没有改变 模块文件
time. sleep(20) # 让时间停 20 秒再继续向下执行 停的期间 将aaa模块文件 修改为执行打印456
aaa.login() # 改过之后执行 结果不变 ====> 123
importlib . reload ( aaa ) # 重新加载aaa 模块
aaa.login() # 再次执行 ===> 456
在模块导入中 不要产生 循环引用 的问题
如果循环导入了 就会发生明明写在这个模块中的方法 却找不到
包
什么是包?
集合了一组py文件 提供了一组复杂功能的
为什么要有包?
当提供的供能比较复杂, 一个py文件写不下的时候就要用包了
包中都有什么?
至少有一个 __init__.py文件
在包中直接导入模块:
import 包.包.模块
调用 包.包.模块. 变量 或 包.包.模块.方法()
from 包.包 import 模块
调用: 模块.变量 或 模块.方法()
从包中导入模块, 要注意 这个包所在的目录是否在 sys.path中
from aaa.bbb.ccc import get 正确
from bbb.ccc import get 显示 Not Found Error ...
若显示 Not Found Error ...则目录不对
导入包相当于什么?
相当于导入了这个包下边的__init__.py 文件
如果直接导入一个包, 那么相当于执行了这个包中的 __init__.py文件
并不会 帮你把这个包下边的其他包以及 py文件 自动导入到内存
如果你希望直接导入包后 , 所有这个包下边的其他内容
包及文件 都能直接通过包来引用, 那么你需要自己 自己处理 __init__.py文件了
e.g
import glance
设计一下 init文件来完成 一些模块的正常导入:
若果你希望 导入包后 能够正常 使用 那么需要 自己去完成 init文件的开发
包中模块的绝对路径 导入
根据绝对路径 来导入, 也就是说 包.包.模块 但是这样的话文件的相对位置就不能改变了
因此 若果要使用绝对路径 你那么 要求当前执行绝对导入的这个文件, 和包的相对位置是不能变得
若变了, 则都错了
绝对路径就可以在那都可以执行, 无论是 模块文件自己执行还是 当成模块导入执行都可以
包中模块的相对路径导入
根据当前我所在模块的导入 即根据当前位置所在模块
from . import glance 当前目录下的 glance
from .. import glance 上一层目录下的 glance
使用了相对导入的模块 只能被当成 模块执行 不能被当作脚本执行
也就是说 , 在模块文件中右键 Run执行是不管用的 只能当作模块去用