引自:https://zhuanlan.zhihu.com/p/81495191
背景
图像在较低的光照下拍摄往往存在亮度低、对比度差等问题,从而影响一些high-level任务,因此低光照图像增强的研究具有很强的现实意义。现有的方法主要分为两类,基于直方图均衡的方法和基于Retinex理论的方法。基于HE的方法主要是扩大图像的动态范围从而增强整幅图像的对比度,是一个全局的过程,没有考虑亮度的变换,可能会导致过度增强。基于Retinex的方法的关键是估计illumination map,是手工调整的,依赖于参数选择,此外这种方法不考虑去除噪声,甚至会放大噪声。现有的基于深度学习的方法没有显式地包含去噪过程甚至依赖于传统的去噪方法,取得的效果不是很好。 论文介绍
MSR-net Low-light Image Enhancement Using Deep Convolutional Network (arxiv17
这是第一篇将CNN与Retinex理论结合起来的论文,提出了一个多尺度Retinex卷积网络,端到端的实现低光照图像增强,属于有监督学习,即输入为一张暗的图像,输出为亮图。 本文的最大创新点在于其认为多尺度的Retinex理论等价于一个不同高斯卷积核组成的反馈卷积神经网络,可以写成如下形式:
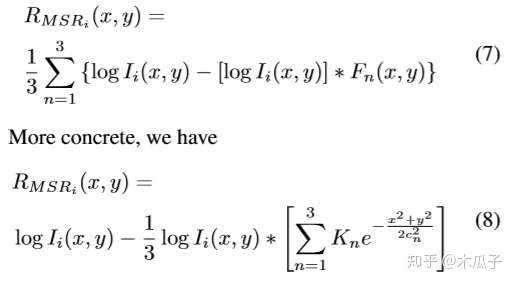
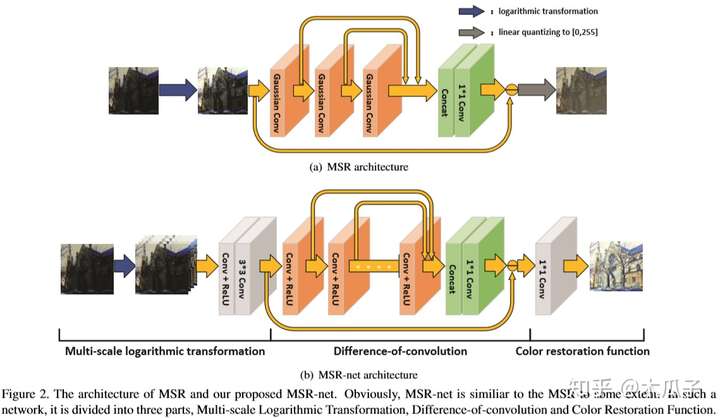
网络结构由三部分组成,分别为多尺度的对数变换,差分卷积和色彩复原函数,如下:
目标函数为:
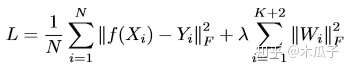
所用的数据集为真是世界的低光照图像,MEF dataset, NPE dataset和VV dataset。评价指标包括SSIM/NIQE/ Discrete Entropy/ Angular error。对比的方法有Fast efficient algorithm for enhancement of low lighting video/A weighted variational model for simultaneous reflectance and illumination estimation/ Low-light image enhancement via illumination map estimation/A multi-scale retinex for bridging the gap between color images and the human observation of scenes. 部分结果如下:

总的来说,这篇论文将Retinex理论运用到CNN中,想法上比较创新,但网络结构中高斯差分卷积跟普通的卷积有什么区别没有说明,以及两个特征做差,感觉挺奇怪的,对比的方法中有两篇也比较老,文中还提到因为感受野的问题,对大的平滑区域会存在halo效应。
Mbllen Low-light image video Enhancement Using CNNs(BWVC18) 现有的方法往往依赖于对像素统计或视觉机制的某些假设,使其不能应用于真实场景,此外,黑暗区域往往存在很多伪影和噪声,为了解决上述问题,本文提出了一个多分支的低光照图像增强网络,包含特征提取模块(FEM):用于提取不同尺度的特征、增强模块(EM):分别增强多尺度的特征、融合模块(FM):将多分支的输出融合,网络结构如下:
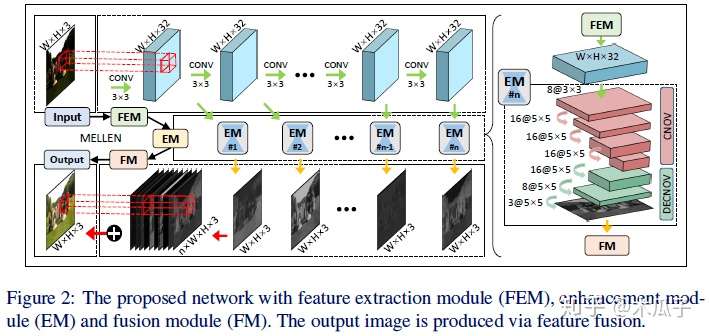
如图中第一行所示,FEM包含10个卷积层,每个卷积层使用3x3的卷积核和ReLU, 输入为一张低光照的彩色图像,每层的输出既为下一层输入,又是EM子网络的输入。EM为一个多级子网络,其输入为FEM每层的输出,其输出为和原低光照相同尺寸的彩色图像,其网络结构如图右侧所示,是对称的卷积和反卷积结构,每个子网络同时训练但参数独立。FM模块concat所有EM中的输出结果,然后使用一个1x1的卷积来融合得到一张增强后的彩色图像。 网络的loss包括结构信息、上下文信息和图像区域差异。结构损失用于提高图像的视觉效果,使用SSIM和MS-SSIM,其中对于单个像素p,其SSIM为:
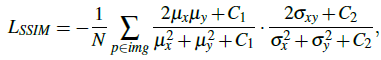
上下文损失使用VGG19来比较高层语义信息的相似性,定义如下:
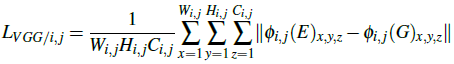
区域损失用于平衡图像中低光照和其他区域的增强程度,首先用一种简单的策略来分离图像中的低光照区域,这里选择40%最黑的像素作为低光照区域的近似,其定义如下:
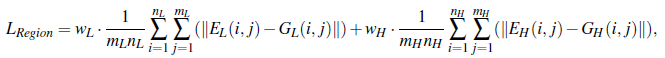
本文所用的低光照图像是基于PASCAL VOC合成的,低光照图像一般具有两个特征:亮度低、存在噪声。因此为了产生低光照图像,使用随机的gamma变换,其过程表示为:
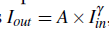
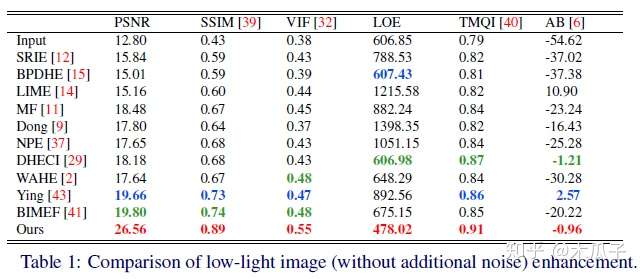
再加上峰值为200的泊松噪声,从VOC数据集中选择16925张图像来合成训练集,56张图像用于验证,144张测试图。 评价指标为PSNR, SSIM, Average Brightness(AB), Visual Information Fidelity(VIF) , Lightness order error(LOE), TMQI。 部分实验结果如下:

本文提出的方法还可以迁移到低光照视频的增强,这篇论文中提出的多分支增强网络比较新颖,但数据集使用的自己合成的低光照图像,会导致模型的泛化性能比较差。 Attention-guided Low-light Image Enhancement(arxiv19.8) 这是arxiv上比较新的一篇论文,是对上一篇论文的改进。针对传统的低光照图像增强在复原亮度和对比度的时候忽略了噪声的影响,这篇论文提出了一个attention指导的多分支网络,使用ue-attention map和noise map进行指导,可以同时进行增强和去噪。此外,本文的另一个贡献是提出了一个低光照图像仿真技术,构建了一个大规模且成对的低光照图像数据集用于研究。 数据集介绍:现有的公开的低光照图像数据集只有LOL和SID,考虑到这两个数据集的数量都比较小,本文提出了低光照图像仿真技术用于构造数据集,先挑选图像,在进行合成。挑选图像包含三步:暗度估计、模糊估计和色彩估计。为了保证数据多样性,选出97030张图来构建数据集,随机选择965张作为测试。本文中使用22656张图作为训练集。合成图像主要考虑低光照图像的两个特征:低亮度和噪声,其数学表达分别为 :
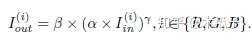
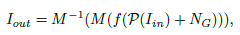
此外,作者发现直接使用原数据集中高质量的图像作为GT来训练得到的结果往往对比度比较低,因此文中又对图像进行对比度放大来得到第二步增强时的GT,具体细节看原文。 本文提出的网络结构包含四个子网络: Attention-Net, Noise-Net, Enhancement-Net和Reinforce-Net,如图所示:
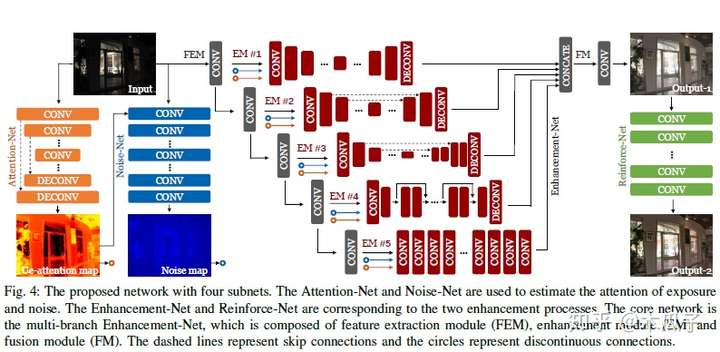
Attention-Net:采用U-Net结构,指导Enhancement-Net正确增强低曝光区域,避免对正常曝光区域过度增强,输出为ue-attention map表明区域的低曝光水平,原图的照度越高则map的值越小,范围为[0,1],定义如下:
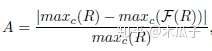
Noise-Net:噪声分布与曝光度分布息息相关,因此使用ue-attention map来获得noise map,网络使用膨胀卷积扩大感受野,指导噪声估计。 Enhancement-Net:出发点是将增强问题分解为多个子问题(如去除噪声、保留纹理、色彩矫正等)通过多分支融合来产生最终输出,其核心包括特征提取模块(FEM)、增强模块(EM)和融合模块(FM)。其中EM模块包含五种不同的结构,EM-1是具有较大卷积核的卷积和反卷积,EM-2和EM-3是U-Net结构,差别是skip connection的方式和feature map的大小,EM-4是Res-Net去除了BN减少了block的数量来减少参数,EM-5由膨胀卷积组成,其输出与输入大小相同。 Reinforce-Net:为了克服低对比度的缺点,提高图像细节。 Loss函数由这四个子网络的加权和得到,考虑结构信息、感知信息和图像的区域差异。Attention-Net的loss为正确的attention map与预测的L2误差;
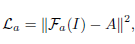
noise-Net的loss为期望的noise map与预测的L1误差,这里有个疑问就是期望的noise map是怎么得到的没有提及;
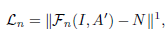
Enhancement-Net的loss包含四部分,亮度损失(使得增强后的图像拥有充足的亮度)、结构损失(保留图像结构,避免模糊)、感知损失(利用高层语义信息提高视觉质量)和区域损失(用于平衡不同区域的增强程度)的加权和。
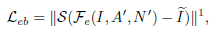
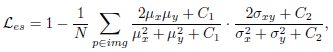
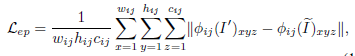
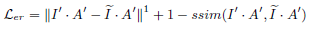
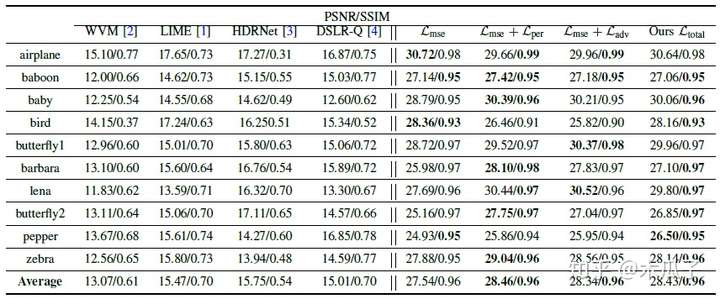
Reinforce-Net的loss与Enhancement-Net相似,包括亮度、结构和感知损失这三部分的加权和。 评价指标:PSNR, SSIM ,AB , VIF , LOE , TMQI 和LPIPS,还有问卷调查。部分实验结果如下:

本文提出的方法在合成数据和真实低光照图像上都得到了比较好的视觉效果,用该方法作为语义分割和目标识别的预处理能明显提升效果。但也存在一些问题,对于一些原本就没有纹理轮廓的难以恢复其细节;由于图像压缩也会导致结果存在棋盘效应;有严重噪声的图像或不可见图像,比如红外图像等很难产生满意的结果。文章最大的创新是两个attention map的指导,但没有给出真实noise map的计算方式。 Kindling the Darkness:A Practical Low-light Image Enhancer(arxiv19.5) 本文的主要贡献主要有三点:1.基于Retinex将图像分解为亮度和反射部分,将原空间解耦到两个更小的子空间,方便训练;2.亮度部分用于灵活地调整光照/亮度;反射部分用于处理噪声、颜色畸变等退化现象;3. 网络没有使用GT,只是使用一对不同光照程度的图像,在不同曝光条件下的数据集LOL达到了state-of-art的结果。其网络结构如下:
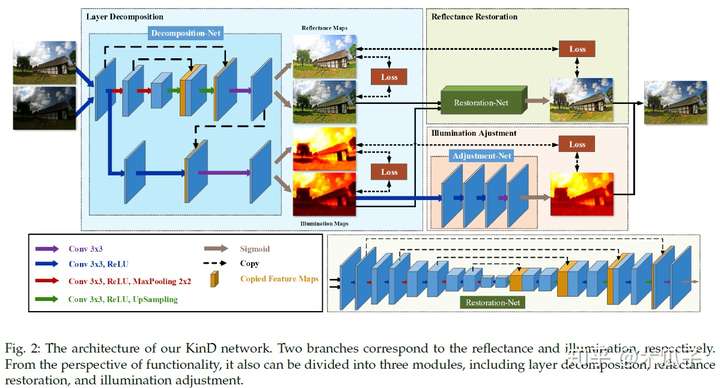
Loss的设计感觉跟Retinex有部分相似,但总体不太一样,具体看原文,贴出部分实验结果:
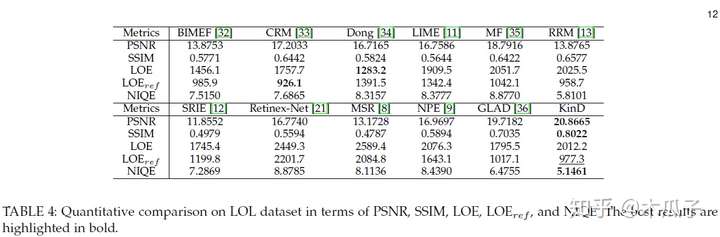

EnlightenGAN Deep Light Enhancement without Paired Supervision(arxiv19)Underexposed Photo Enhancement Using Deep Illumination Estimation(CVPR2019) 看了有段时间忘记了,待续 Low-Light Image Enhancement via a Deep Hybrid Network(TIP2019) 这是TOG2019年的一篇论文,感觉创新点还是比较多的,第一,提出了一种深度混合网络来增强低光照图像,该网络包含两个部分,一部分为内容stream,用于预测输入图像的场景信息,另一部分为边缘stream,用于学习边缘细节。第二,提出了一种空间变体RNN结构,引入两个权重map作为输入特征和RNN的隐含层状态,这个RNN用于获取图像内部结构,如边缘等。第三,由于在增强图像细节时可能会使噪声放大,因为在训练集中加入高斯噪声,可以有效抑制测试图像上的噪声。此外,这个混合网络采用感知损失和判别损失,可以生成视觉效果较好的增强图像。 网络结构如下:
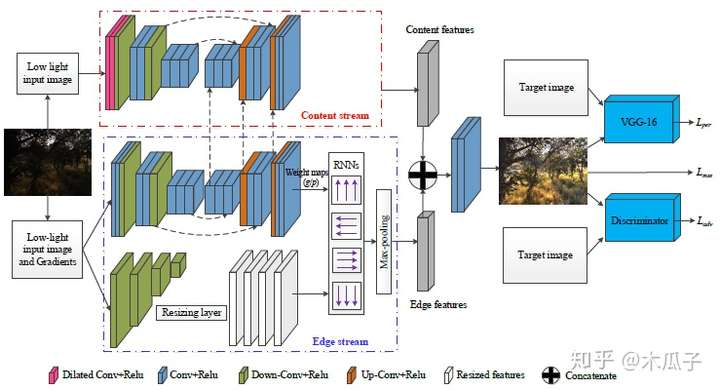
该模型包含两个分支,上面是一个残差的encoder-decoder结构用于估计场景信息,前两个卷积层为膨胀卷积用于扩大感受野,edge stream中反卷积模块的特征在上采样过程中concat起来。Encoder和decoder各有三个卷积模块,每个包含一些卷积层,ReLU和skip links,是一个先下采样再上采样的过程。 Edge stream通过一个空间变体(spatially variant)的RNNs来预测图像的静态边缘(spatially variant),该网络的输入为低光照图像及其梯度,具体结构如下:
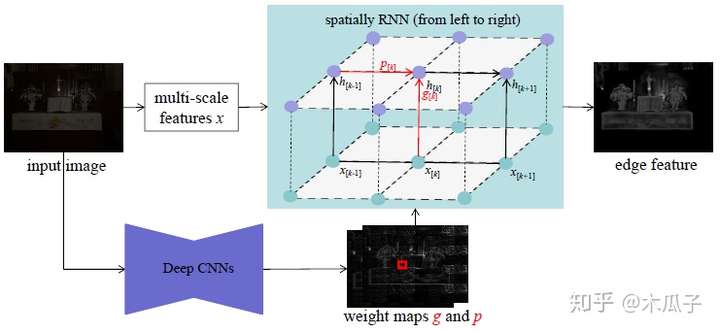
从图中,可以看出深度CNN结构用于获取两个权重map g和p,上半部分对输入图像采用下采样卷积获得多尺度的特征x,大小分别为{1,1/2,1/4,1/8},再将他们resize到与x一样大,然后concatenate起来作为RNN的输入,隐含层的计算公式为:
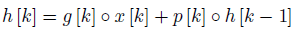
从4个方向分别扫描图像,可以生成四个隐含的activation maps来学习不同的边缘相关特征。然后根据各个方向的最大响应选出最优方向,采用node-wise max pooling对每个位置选择每个四个方向中的最大值作为静态边缘信息。 得到边缘特征和内容特征后,concatenate起来,经过两个额外的卷积层就可以得到增强后的图像,除了计算基本的MSE loss之外,还引入了感知损失VGG16和判别损失,计算公式如下:
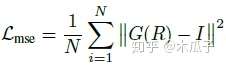
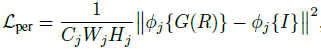
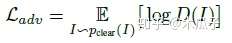
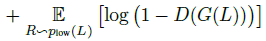
总的损失如下:
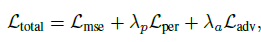
判别网络如下:
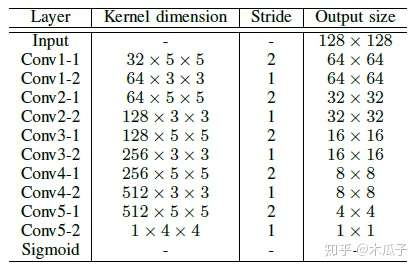
本文中用到的训练集是从MIT-Adobe Five5K,从中挑选了336对低光照图像。测试时对十张图像用伽马变换做了暗处理,并加了1%的高斯噪声,结果如下:
可视化结果如下:

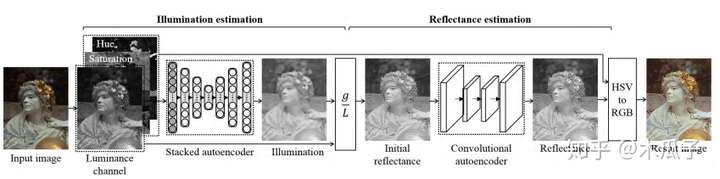
总的来说,这篇论文提出了一个混合模型,内容层用于增强低亮度输入图像的可见性并学习对场景内容的整体估计;边缘网络用改进的空间变体RNN从其输入和梯度中学习边缘信息,将两者结合起来能获得高质量的增强图像。但感觉这个网络比较难训练,而且用CNN获取的权重文中也没有详细说明,实现起来可能会比较困难。 一些不是特别出名但可参考的网络结构 Dual Autoencoder Network for Retinex-Based Low-Light Image Enhancement(IEEE Access17) 提出了基于Retinex的对偶自编码网络用于低光照图像增强并结合卷积自编码网络进行去噪,首先估计空间平滑的照度部分,然后计算反射部分,并用卷积自编码去除噪声。
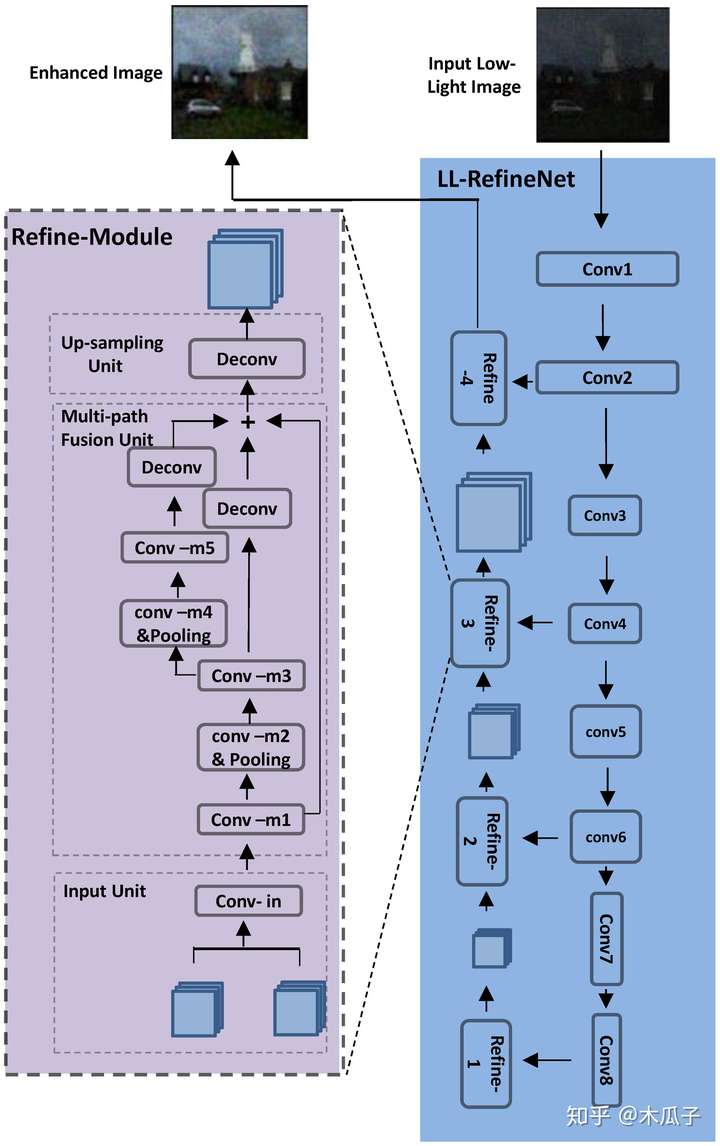
Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways(Symmetry) 本文针对自然低光图像的特点,提出了一个深度的精细网络LL-RefineNet的图像增强算法,在合成的黑暗图像上训练,同时在自然图像和合成图像上进行测试,都取得了较好的结果。该网络利用了下采样路径的所有有用信息,产生了高分辨率的增强结果,利用前几层卷积生成的局部特征,逐步细化从更深层次获得的全局特征。
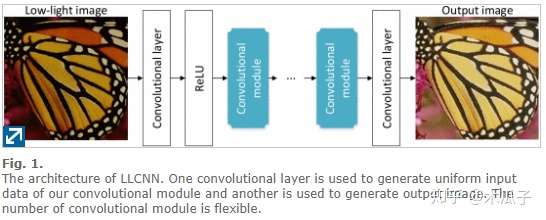
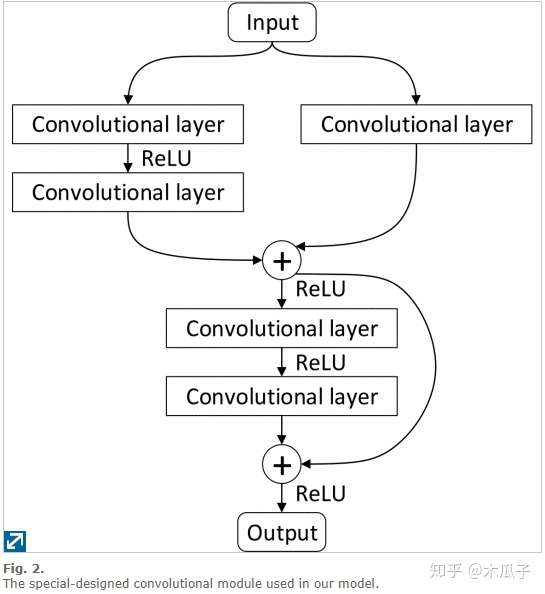
LLCNN: A convolutional neural network for low-light image enhancement(VCIP17) 这篇文章比较简单,一个浅层的CNN网络端到端地学习低光照图像和GT之间的映射关系,训练数据使用的模拟不同的gamma变换得到的,对比的多是一些传统的方法和LLNet。网络结构和VDSR比较相似,如下: