Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
引言
本次作业分为四部分,是在《爬虫大作业》与《Hadoop环境搭建》的基础上进行的,在《爬虫大作业》中,我主要在已经搭建好了Hadoop、MySQL、MapReduce、HBASE、hive的Linux虚拟机中对中国传媒大学南广学院的新闻信息进行的数据爬取,最终得到的数据存在一个名为cucn.csv中。本次作业的任务主要有以下四点:
1.对csv文件进行预处理生成,utf-8编码的文件
2.将爬虫大作业产生的csv文件上传到HDFS,再一次对csv文件进行处理,生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
4. 用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
对csv文件进行预处理生成,utf-8编码的文件
由于我们爬取下来的数据并不是全部都是我们所要的,或者是有一些数据需要进行加工才可以用到,这时候数据的预处理就必不可少了。
首先我们需要除去数据中的无意义空格与换行:


然后需要将文件保存为utf-8的编码,避免出现乱码:
将爬虫大作业产生的csv文件上传到HDFS,再一次对csv文件进行处理,生成无标题文本文件
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

其次,我们把cucn.csv文件放到下载这个文件夹中,并使用命令把cucn.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
把cucn.csv文件拷到刚刚所创建的文件夹中
如下图所示:

对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
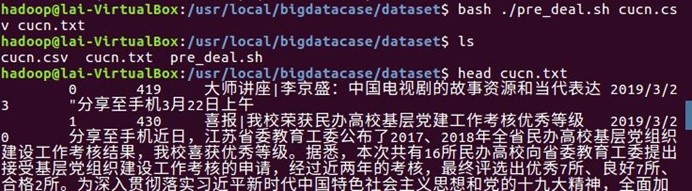
② head -5 cucn.csv #查看前五行记录
并且对数据进行预处理字段并且转化为无标题文本文件
如下图所示:


接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

将爬虫大作业产生的csv文件上传到HDFS,再一次对csv文件进行处理,生成无标题文本文件
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/lagoupy.csv | head -5 #查看hdfs中lagoupy.csv的前五行
如下图所示:



把hdfs中的文本文件最终导入到数据仓库Hive中
① service mysql start #启动mysql数据库
并且检测端口3306是否有给占用
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:



其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database dblab; -- 创建数据库dblab
② use dblab;
③ create external table cucn(aa string,number int,click int,title string,riqi string,text string) row format delimited fields terminated by ' ' stored as textfile location '/bigdatacase/dataset/'; -- 创建表cucn并把hdfs中/bigdatacase/dataset/目录下的数据加载到表中
④ select * from cucn limit 10; -- 查看cucn中前10行的数据
如下图所示:


用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
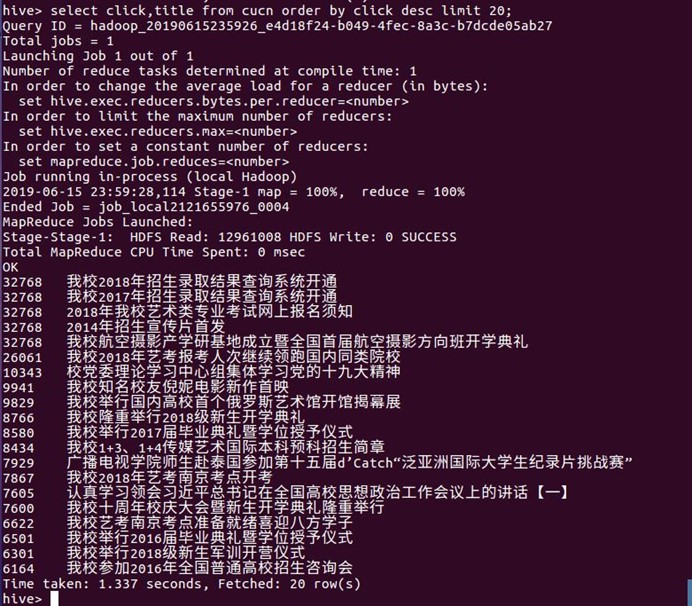
1.点击量排序:可以看到点击数前二十条有六条超过了三万点击量的其中排名一二的是这个学校的招生通知,可以说明学生平常较少看校园新闻网,除了一些他们感兴趣的宣传片,剩下的就是一些招生通知与报名通知
select click,title from cucn order by click desc limit 20;
2.时间排序:可以看出学校的新闻网大概平均每个月有三到四篇的发文量,并且在放假时期发文数量急剧下降
select riqi,title from cucn order by riqi desc limit 20;

3.点击数大于8000的:可以看出学校新闻网里面点击数超过八千的有一半是通知类信息,另一半是学校举行活动时的一些记录与报道,这个可以反映出学生更加关注学校新闻网的通知类信息与他们感兴趣的部分学校大型活动
select click,title from cucn where click > 8000;

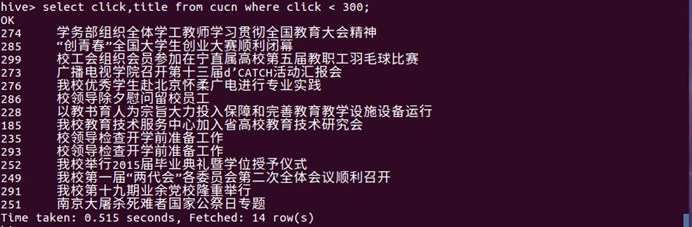
4.点击数小于200的:从这里的信息可以分析出,学校新闻网中点击量较少的都是一些校方开会的通知,开会的消息,还有一些精神的宣传
select click,title from cucn where click < 300;
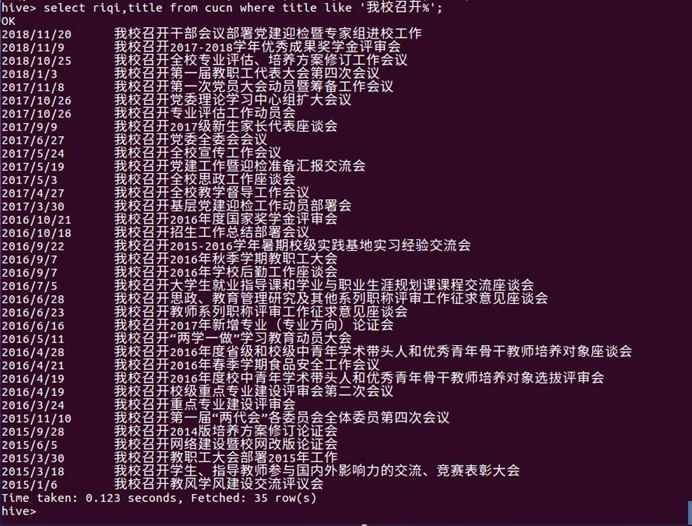
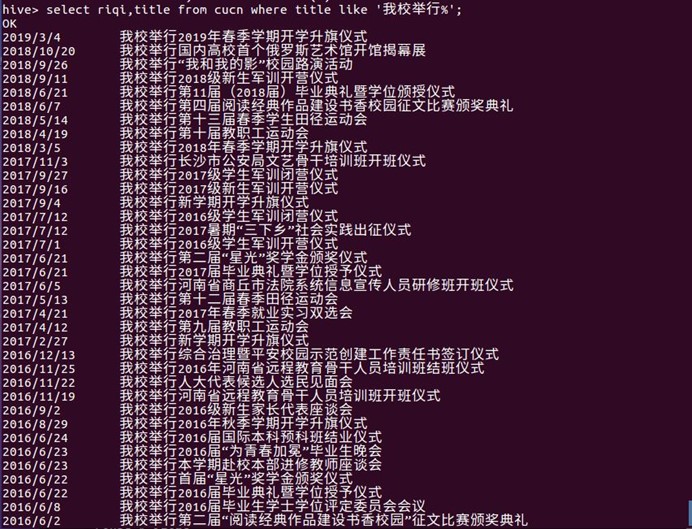
5.标题与我校密切相关的:由此可以看出,与我校这个词密切相关的标题在学校新闻网上面出现的频率较大,并且都是我校举行、召开,承办、还有与一些其他机构或学校合作的活动
select riqi,title from cucn where title like '我校召开%';
select riqi,title from cucn where title like '我校举行%';
select riqi,title from cucn where title like '我校承办%';
select riqi,title from cucn where title like '我校与%';
select riqi,title from cucn where title like '我校入围%';



6.最大点击数的网页:对于学校的人数来说,这里三万多的点击量在学校新闻网来说不算多,说明了学校学生平常都可能比少关注学校的新闻网
select max(click) from cucn;

7.最小点击数的网页:从185这个数字可以看出,这个新闻大家可能是大家不感兴趣、不关心或者说是内容实在太糟糕的新闻
select min(click) from cucn;

8.所有网页点击数的总和:从这条数据可以分析出,学校新闻网的点击量总量不是很大,所以大多数学生平常是比较少关注学校新闻网的信息的,我认为有可能是信息不够吸引人,或者说是学校新闻网本身的宣传力度不够
select sum(click) from cucn;

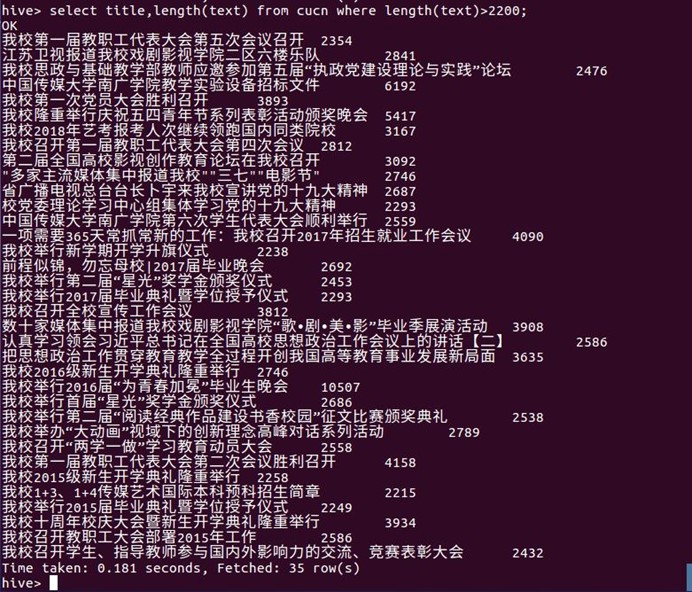
9文章内容的文本字数>3000:可以看出学校网站点击量大于3000的基本上是颁奖仪式之类的仪式类新闻,我认为有可能是学生想看自己是否得奖并且想保存自己或者是认识的同学的得奖照片然后点击学校新闻网查看的
select riqi,title,length(text) from cucn where length(text)>3000;
10.文章内容的文本字数<300:从这里的数据可以分析出,学校新闻网站的点击量偏小的基本是在一些讲座的推广、一些校方协议的签订、还有一些仪式举行的通知,由此可以知道这些东西都是学生较为不感兴趣的
select length(text),title from cucn where length(text)<300;

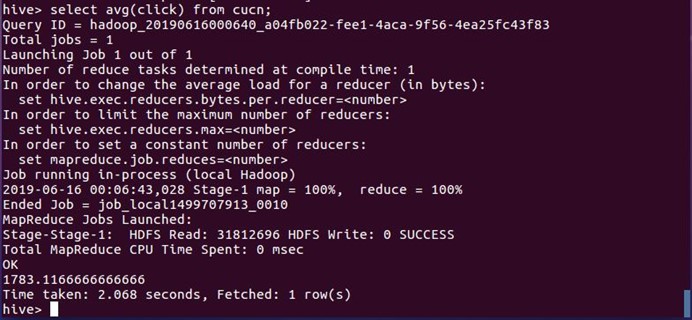
11.平均点击数:这里可以看出学校新闻网每篇新闻的平均的点击量在1700左右,平均点击量的偏低可以更直观的反映学生较少浏览学校新闻网的新闻
select avg(click) from cucn;
12.题目总字数统计:这条数据可以分析出,学校新闻网每篇行文的题目都普遍偏长,初步分析估计是为了在题目之中突出本次活动或者说本次新闻的主要内容导致的偏长。
select sum(length(title)) from cucn;

13.题目字数<12:从这条数据可以分析出,学校新闻网的新闻题目字数小于12的是在太少了,进一步加强了,学校为了在标题中概括说明此次新闻的主要内容的嫌疑
select length(title),title,riqi from cucn where length(title)<12;
14.题目字数>40:从这条数据可以很明显可以看出,题目大于40字的标题竟然还有这么多,所以可以分析出学校新闻网的新闻标题都比较长
select length(title),title,riqi from cucn where length(title)>40;

数据分析总结:从我爬取的数据中分析可以得到,学校中的学生大多数都不怎么喜欢看学校的新闻网,有一些通知类的新闻会出现偏高的情况,所以可以看出学生大多数看新闻网是为了查看某一类的通知信息,而一些活动信息普遍都不怎么受学生们的欢迎,我分析有三点原因,首先是学校新闻网中的新闻内容不够吸引人,然后是学校的宣传不够,还有一个原因是学校的新闻普遍标题过长,新闻标题为了可以概括此次新闻的主要内容不惜将新闻标题写的很长,我认为这也会导致学生不想看新闻,所以我给的解决方案是在标题下面加一个比较显眼的引言,精炼又不让标题过长。