1. 与简单线性回归的区别
多个自变量(x)
2. 多元回归模型
![]()
其中,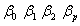 是参数,
是参数,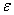 是误差值,
是误差值, 截面
截面
3. 多元回归方程
![]()
4. 估计多元回归方程
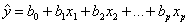
一个样本被用来计算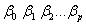 的点估计
的点估计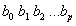
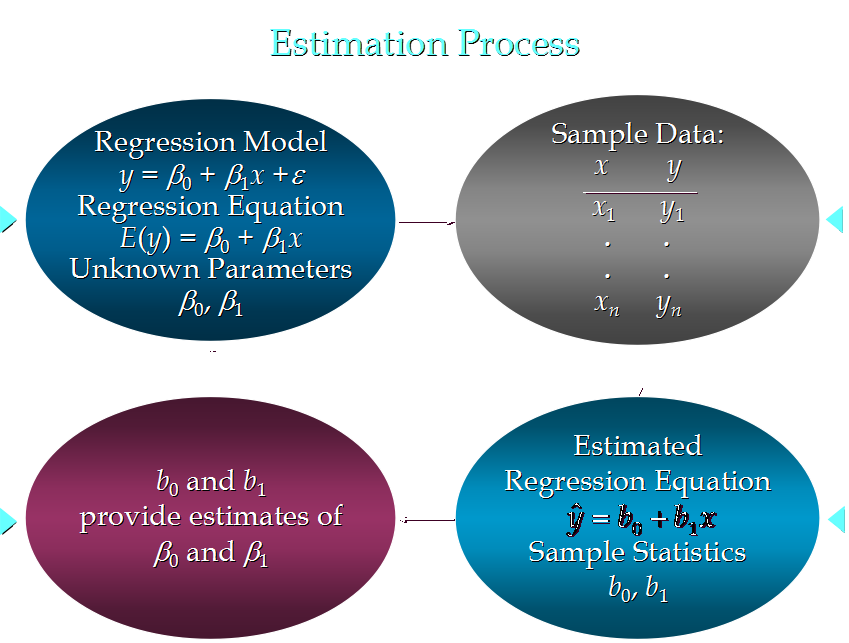
5. 估计流程(与简单线性回归类似)
6. 估计方法
使用sum of squares最小
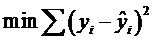
运算与简单线性回归类似,涉及到线性代数和矩阵代数运算
7. 列子
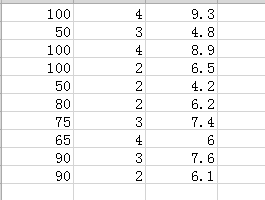
一家快递公司送货:x1 : 运输里程, x2: 运输次数, y: 总运输时间
|
X1 |
X2 |
X3 |
|
|
1 |
100 |
4 |
9.3 |
|
2 |
50 |
3 |
4.8 |
|
3 |
100 |
4 |
8.9 |
|
4 |
100 |
2 |
6.5 |
|
5 |
50 |
2 |
4.2 |
|
6 |
80 |
2 |
6.2 |
|
7 |
75 |
3 |
7.4 |
|
8 |
65 |
4 |
6.0 |
|
9 |
90 |
3 |
7.6 |
|
10 |
90 |
2 |
6.1 |
模型:Time=b0 + b1*Miles + b2*Deliveries
求出的模型:Time= -0.869+ 0.0611*Miles + 0.923*Deliveries
参数含义:b0: 截面,当所有的x为0时的期待值
b1:平均每多运送一英里,运输时间延长0.0611小时
b2: 平均每多一次运输,运输的时间延长0.923小时
预测:如果一个运输任务跑102英里,运输6次,预计多少小时?
Time= -0.869+ 0.0611*102+ 0.923*6
=10.9小时
代码实现:
数据源:
# -*- coding:utf-8 -*-
from numpy import genfromtxt
from sklearn import linear_model
dataPath = r"Delivery.csv"
deliveryData = genfromtxt(dataPath,delimiter=',')
print ("data")
print (deliveryData)
x = deliveryData[: , : -1]
y = deliveryData[: , -1]
print("x")
print(x)
print("y")
print(y)
lr = linear_model.LinearRegression()
lr.fit(x ,y)
print("coefficients:")
print(lr.coef_) #b1 b2
print("intercept:")
print(lr.intercept_) #b0
xpredict = [102, 6]
ypredict = lr.predict(xpredict)
print("predict:")
print(ypredict)
结果
data
[[ 100. 4. 9.3]
[ 50. 3. 4.8]
[ 100. 4. 8.9]
[ 100. 2. 6.5]
[ 50. 2. 4.2]
[ 80. 2. 6.2]
[ 75. 3. 7.4]
[ 65. 4. 6. ]
[ 90. 3. 7.6]
[ 90. 2. 6.1]]
x
[[ 100. 4.]
[ 50. 3.]
[ 100. 4.]
[ 100. 2.]
[ 50. 2.]
[ 80. 2.]
[ 75. 3.]
[ 65. 4.]
[ 90. 3.]
[ 90. 2.]]
y
[ 9.3 4.8 8.9 6.5 4.2 6.2 7.4 6. 7.6 6.1]
coefficients:
[ 0.0611346 0.92342537]
intercept:
-0.868701466782
predict:
[ 10.90757981]
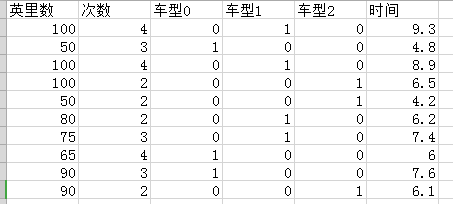
8. 如果自变量中有分类型变量(categorical data),如何处理?
|
英里数 |
次数 |
车型 |
时间 |
|
|
1 |
100 |
4 |
1 |
9.3 |
|
2 |
50 |
3 |
0 |
4.8 |
|
3 |
100 |
4 |
1 |
8.9 |
|
4 |
100 |
2 |
2 |
6.5 |
|
5 |
50 |
2 |
2 |
4.2 |
|
6 |
80 |
2 |
1 |
6.2 |
|
7 |
75 |
3 |
1 |
7.4 |
|
8 |
65 |
4 |
0 |
6.0 |
|
9 |
90 |
3 |
0 |
7.6 |
|
10 |
90 |
2 |
6.1 |
6.1 |
代码实现:
数据源:
# -*- coding:utf-8 -*-
from numpy import genfromtxt
from sklearn import linear_model
datapath = r"Delivery_Dummy.csv"
data = genfromtxt(datapath, delimiter=",")
print("data:")
print(data)
x = data[1:,:-1]
y = data[1:,-1]
print("x:" )
print(x)
print("y:" )
print(y)
mlr = linear_model.LinearRegression()
mlr.fit(x,y)
print(mlr)
print("coef:")
print(mlr.coef_)
print("intercept:")
print(mlr.intercept_)
xpredict = [90,2,0,0,1]
ypredict = mlr.predict(xpredict)
print("predict:")
print(ypredict)
结果:
data:
[[ nan nan nan nan nan nan]
[ 100. 4. 0. 1. 0. 9.3]
[ 50. 3. 1. 0. 0. 4.8]
[ 100. 4. 0. 1. 0. 8.9]
[ 100. 2. 0. 0. 1. 6.5]
[ 50. 2. 0. 0. 1. 4.2]
[ 80. 2. 0. 1. 0. 6.2]
[ 75. 3. 0. 1. 0. 7.4]
[ 65. 4. 1. 0. 0. 6. ]
[ 90. 3. 1. 0. 0. 7.6]
[ 90. 2. 0. 0. 1. 6.1]]
x:
[[ 100. 4. 0. 1. 0.]
[ 50. 3. 1. 0. 0.]
[ 100. 4. 0. 1. 0.]
[ 100. 2. 0. 0. 1.]
[ 50. 2. 0. 0. 1.]
[ 80. 2. 0. 1. 0.]
[ 75. 3. 0. 1. 0.]
[ 65. 4. 1. 0. 0.]
[ 90. 3. 1. 0. 0.]
[ 90. 2. 0. 0. 1.]]
y:
[ 9.3 4.8 8.9 6.5 4.2 6.2 7.4 6. 7.6 6.1]
coef:
[ 0.05520428 0.6952821 -0.16572633 0.58179313 -0.4160668 ]
intercept:
0.209160181582
predict:
[ 6.1520428]
9. 关于误差的分布
误差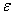 是一个随机变量,均值为0
是一个随机变量,均值为0
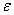 的方差对于所有的自变量来说相等
的方差对于所有的自变量来说相等
所有的 值是独立的
值是独立的
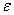 满足正态分布,并且通过
满足正态分布,并且通过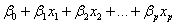 反应y的期望
反应y的期望