1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
a.开启
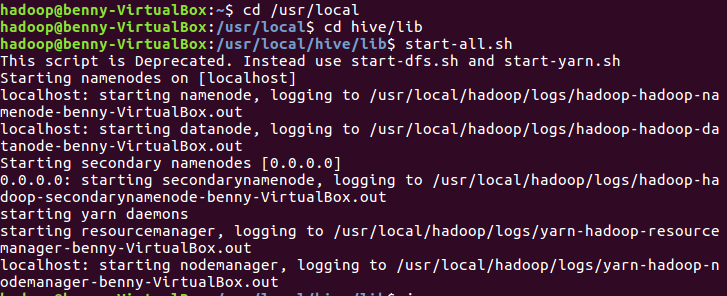
cd /usr/local cd hive/lib start-all.sh
b.查看
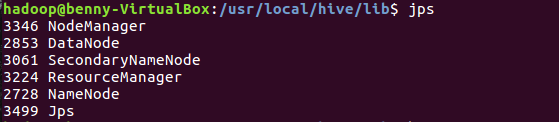
jps
c.将网络爬虫大作业的结果存入txt,并且保存到hdfs里面。
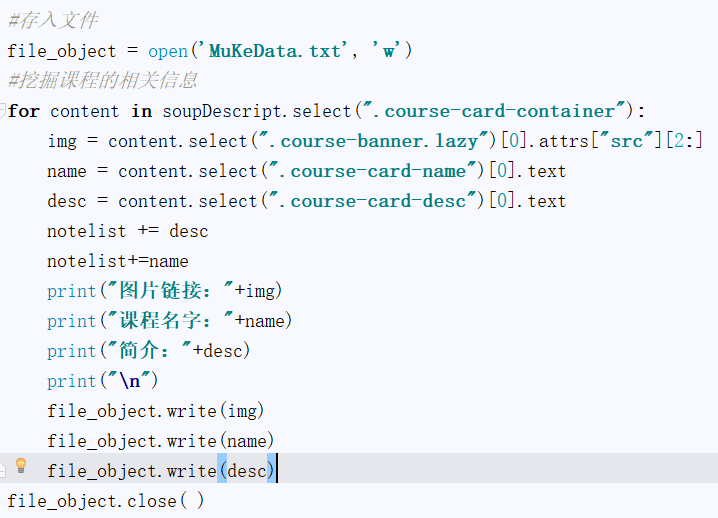
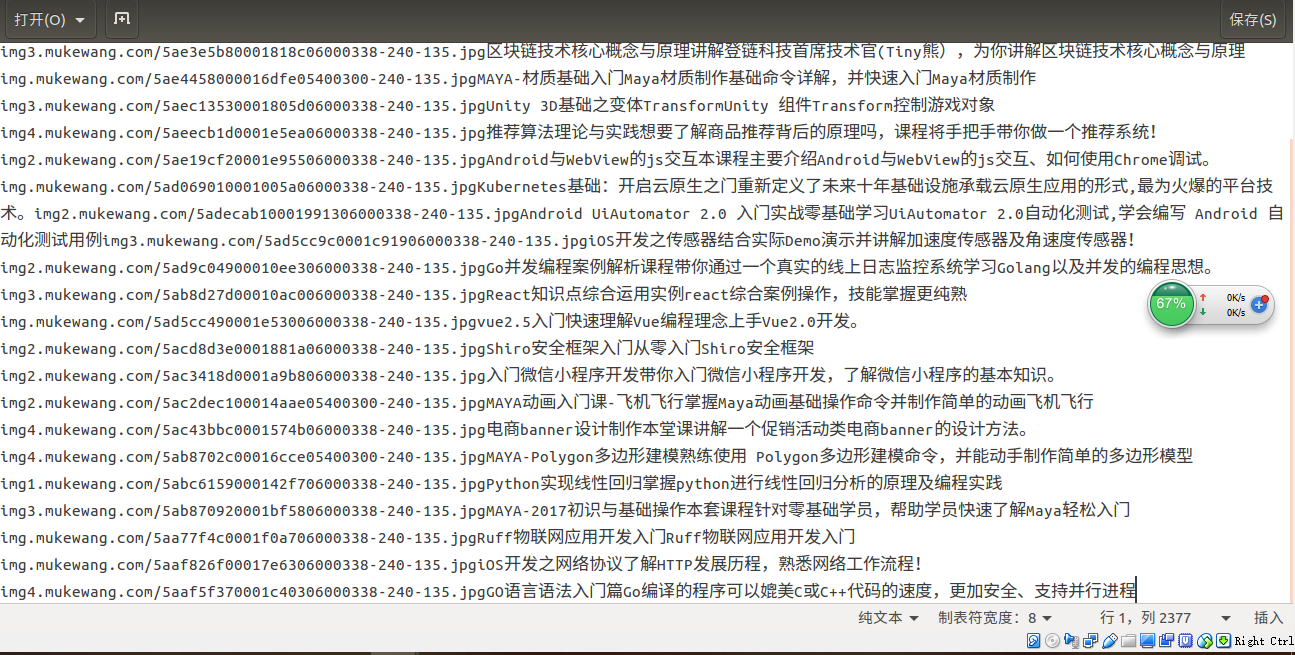
这是爬虫爬出来的数据

#新建路径/webinpt,蒋其存入/user/hadoop里面 hdfs dfs -mkdir /webinput hdfs dfs -ls /user/hadoop

将爬虫大作业得到的数据写入创建的MuKeData.txt中,将其存入 /user/hadoop/webinput中,并且查看
gedit MuKeData.txt hdfs dfs -put ./MuKeData.txt /user/hadoop/webinput hdfs dfs -ls /user/hadoop/webinput
查看数据是否正确

d.开启hiv
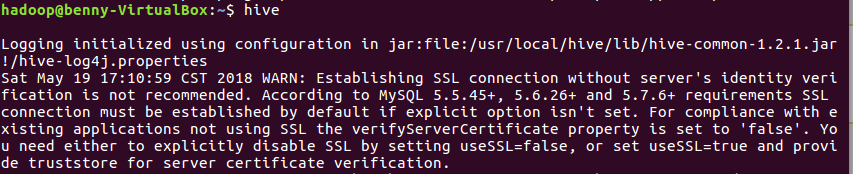
f.载入数据

load data inpath '/user/hadoop/MuKeData.txt' overwrite into table docs;
g.创建查表
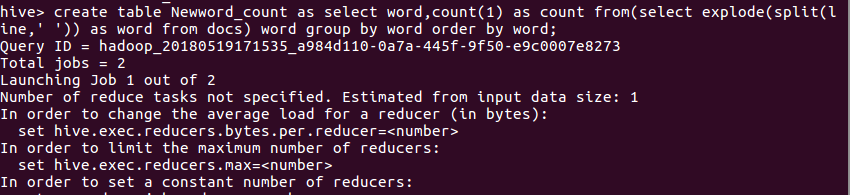
create table Newword_count as select word,count(1) as count from(select explode(split(line,' ')) as word from docs ) word group by word order by word;
h.查看表是否创建成果
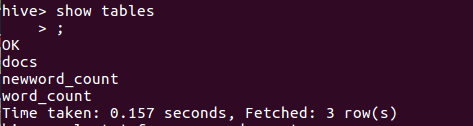
i.查看结果
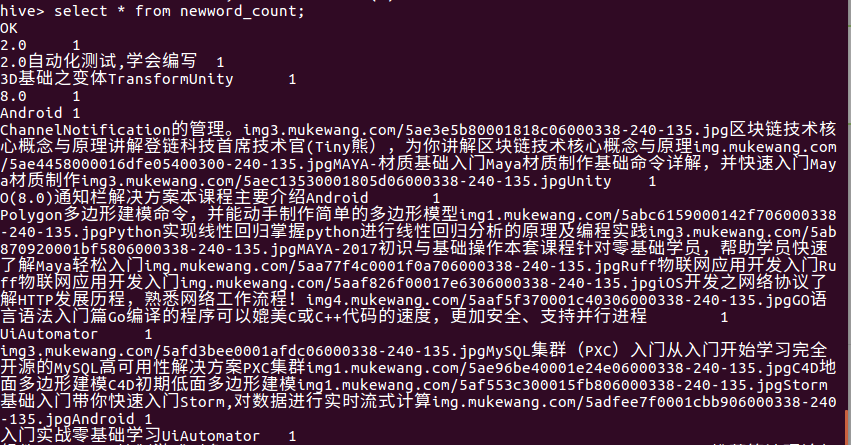
我总结最后的结果问题出现在分析数据源的SQL语句上,不能够分析字母和汉字,所以导致这种情况,如果用英文就可以完美的解决。所以总体上来说,是成功的。
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
首先,我是分析慕课网的课程页面,也就是我前面的文章,爬虫大作业分析的数据。下面开始进行HIVE分析。
1.数据导入。因为我是用自己的数据进行分析,当然不免就要进行csv导出,其中用到了pandas,具体代码加入到爬虫数据中即可。
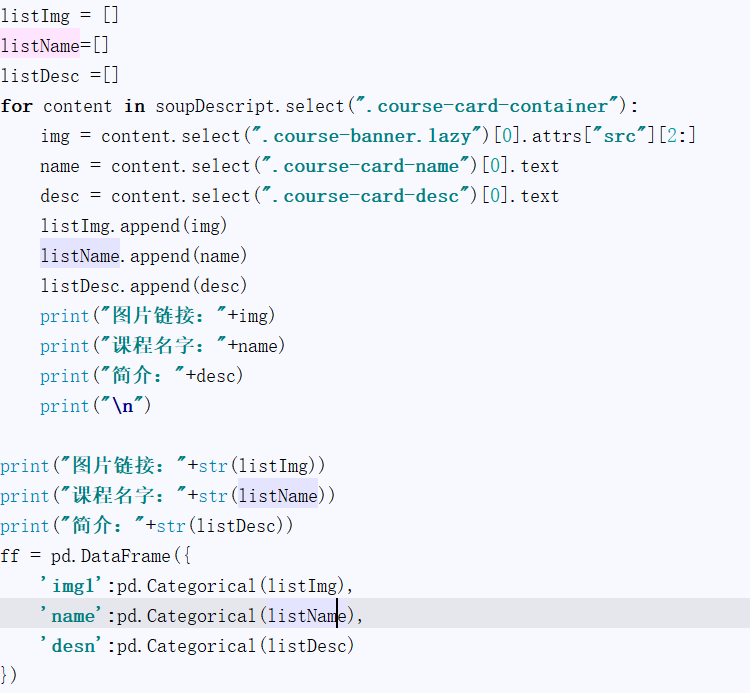
csv导出:


#导入pandas包
import pandas as pd
#这个根据各自的需求决定,用列表存储数据
listImg = []
listName=[]
listDesc =[]
#导出csv
ff.to_csv('MuKeData.csv')
这是我自己的excel数据
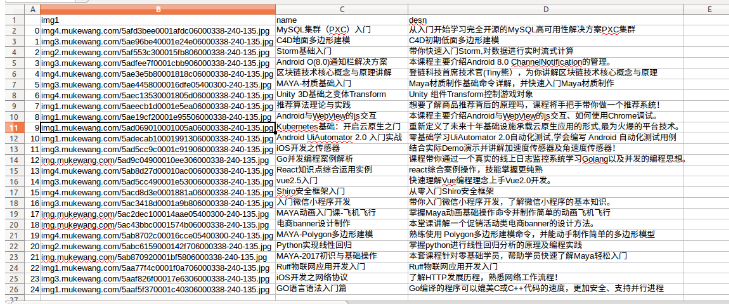
如果遇到导出之后打开是错误乱码,则用txt进行转码即可。得到的数据,我是通过QQ邮箱进行传递,即电脑传入qq邮箱,linux登陆QQ邮箱下载。
进入linux系统,为bigdatacase授权,才可以进行粘贴数据和后面的操作。
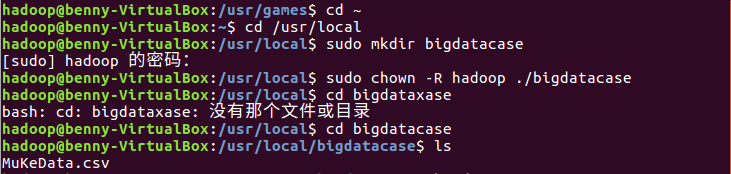
将自己的csv导入到bigdatacase里面,下载后直接移动和粘贴即可。

当然,要的测试一下自己是否导入成功,看看自己的路径下面是否有自己的csv文件。我的路径是 /usr/local/bigdatacase ,
跳转就不用说了吧?cd /usr/local/bigdatacase

如果上述的都没问题的话,那么下面就开始第二步,查表和建表。
2.数据集的简单处理和预处理(预处理可以节省时间,而且可以作为“接口”一直调用)
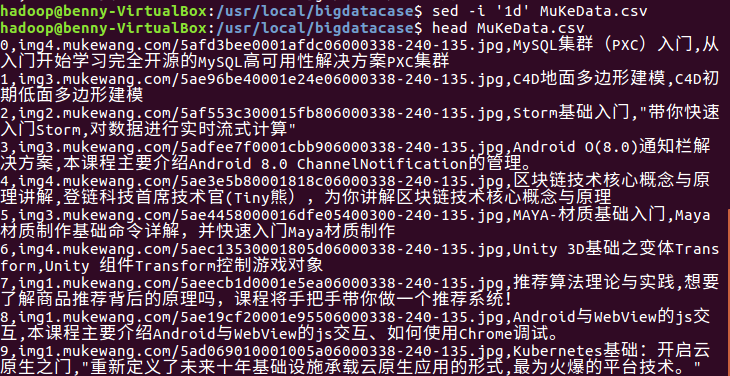
删除文件的第一条数据,也就是字段名称
#在shell里面,sed主要是用于一些简单的文本替换 #就地修改文件:-i 删除:d 注意,是1d 不是id sed -i ‘1d’ MuKeData.csv #如果电脑比较差,数据比较多,可以在head后面加一个限制 比如 -5 head MuKeData.csv
预处理,创建一个脚本文件pre_deal.sh
#创建脚本 vim pre_deal.sh #执行脚本,目标是csv 存储到user_table bash ./pre_deal.sh MuKeData.csv user_table.txt

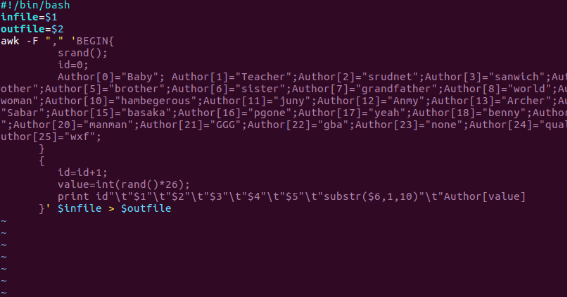
当然,上面的vim pre_deal.sh后面是这里。
#!/bin/bash
infile=$1
outfile=$2
awk -F "," 'BEGIN{
srand();
id=0;
Author[0]="Baby"; Author[1]="Teacher";Author[2]="srudnet";Author[3]="sanwich";Author[4]="mother";Author[5]="brother";Author[6]="sister";Author[7]="grandfather";Author[8]="world";Author[9]="woman";Author[10]="hambegerous";Author[11]="juny";Author[12]="Anmy";Author[13]="Archer";Author[14]="Sabar";Author[15]="basaka";Author[16]="pgone";Author[17]="yeah";Author[18]="benny";Author[19]="gai";Author[20]="manman";Author[21]="GGG";Author[22]="gba";Author[23]="none";Author[24]="qualicaton";Author[25]="wxf";
}
{
id=id+1;
value=int(rand()*26);
print id" "$1" "$2" "$3" "$4" "$5" "substr($6,1,10)" "Author[value]
}' $infile > $outfile
具体的学习可以去http://www.runoob.com/linux/linux-comm-awk.html ,awk处理文本文件的语言。
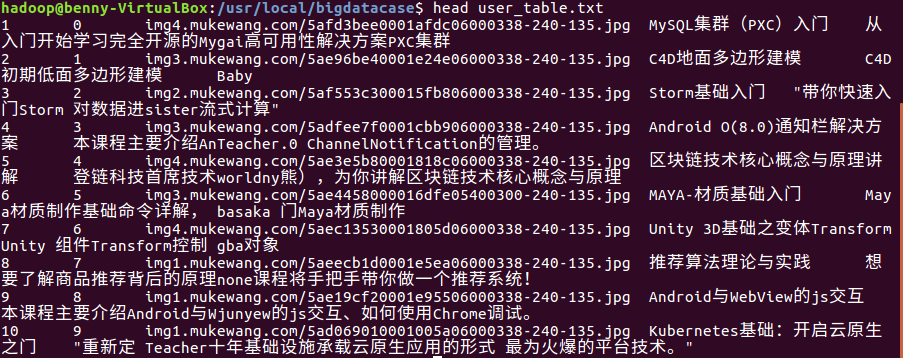
最后查询数据,同时对以前的数据进行对比。
head user_table.txt
里面的数据
本身的数据
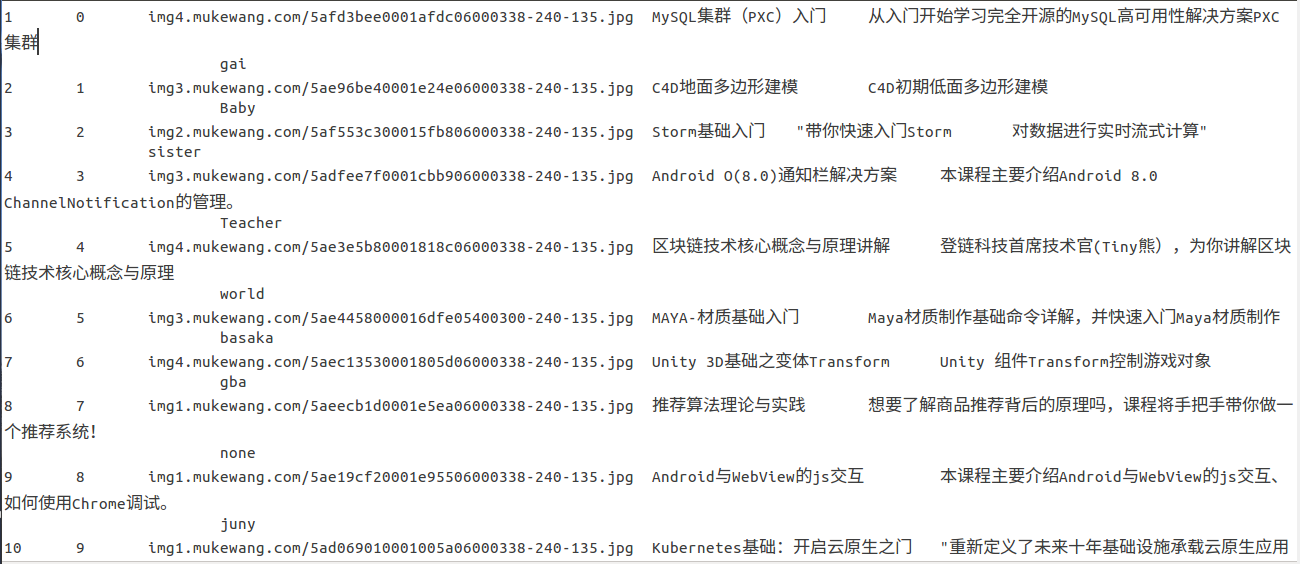
数据如果问题,立马要停止去吧前面的做好。因为我的数据因为预处理排版问题出现了问题,所以对于后面的数据分析造成了一些影响。
如果没有出现问题,就进行后面的步骤:导入到HDFS
3.导入到HDFS
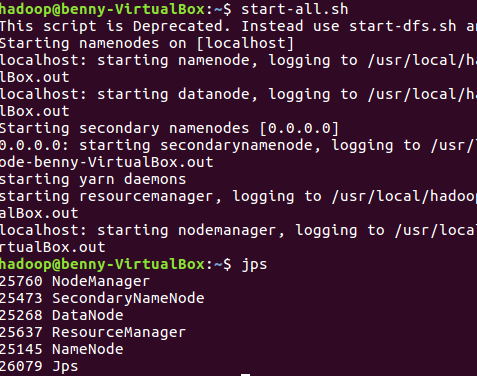
开启HDFS
start-all.sh jps
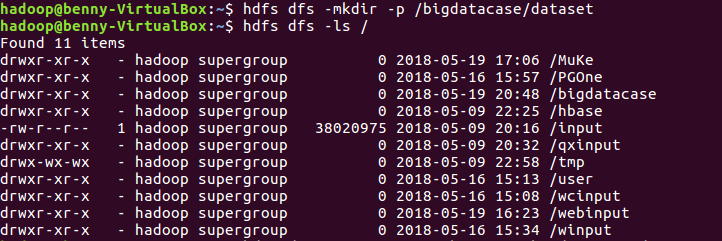
#在HDFS上建立bigdatabasecase/dataset hdfs dfs -nkdir -p /bigdatacase/dataset hdfs dfs -ls /
将user_table.txt存入到hdfs中的路径中:
hdfs dfs -put /usr/local/bigdatacase/user_table.txt /bogdatacase/dataset

最后,进行验证。
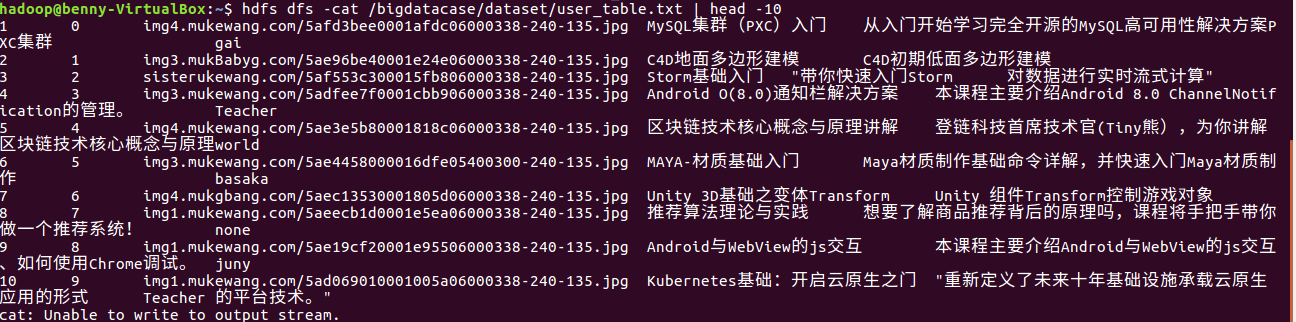
#验证hdfs,在相应的路径中查询是否有数据 hdfs dfs -cat /bigdatacase/dataset/user_table.txt | head -10
如果上述没有问题,将进行导入到数据仓库HIVE中
4.导入到HIVE数据仓库中
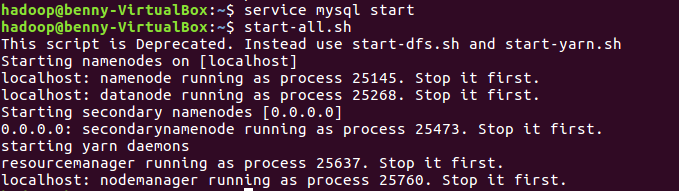
启动MySQL数据库、Hadoop
service mysql start start-all.sh
启动hive
创建数据库dblab
create database bdlab;

创建外部表bdlab.bigdata_user,并且把‘/bigdatacase/dataset’目录下的数据加载到数据仓库Hive中。(注意,里面的列类,都是根据自己的实际需求进行更改,而且如果熟悉数据语言,进行相应的修改)
create external table bdlab.bigdata_user(id INT,user_id INT,img STRING,name String ,desn String,author string)comment 'user analyse' Row format delimited fields terminated by ' ' stored as textfile location '/bigdatacase/dataset';

最后,查看前面创的表(检查是否有问题):
select * from bdlab.bigdata_user limit 10;
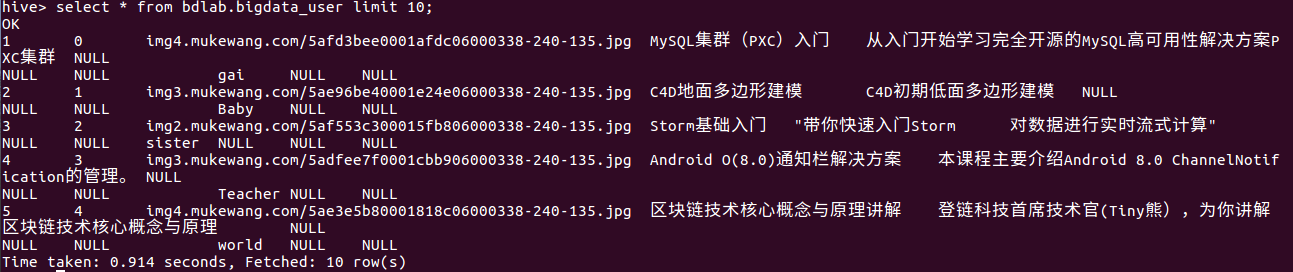
显示其中一个列的数据
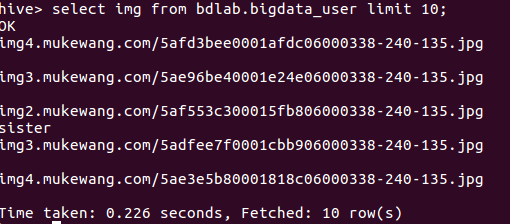
因为自己在前面的预处理环境,数据表出现了问题,一开始没有重视,现在就会出现这种问题,也就会影响到后面的数据分析。
如果没有什么问题,就到最后的数据分析。
5.数据分析
因为自己所爬到的数据对于数据分析不是很好,所以我弄了以下适合自己的数据方式进行分析:
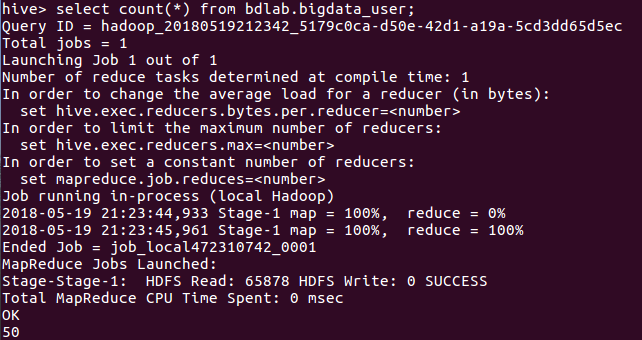
查询数据有多少条数:
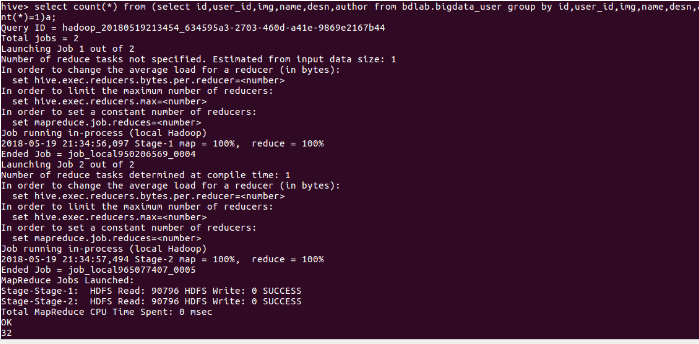
select count(*) from bdlab.bigdata_user
不重复的id有多少条:
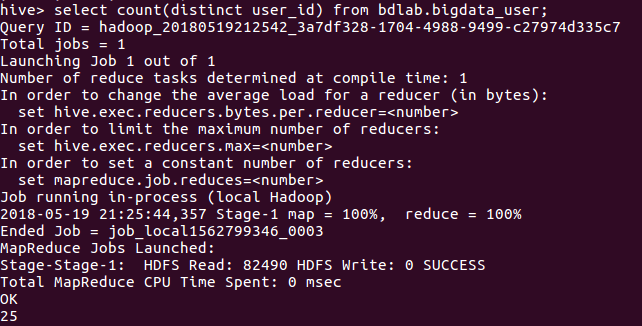
select count(distinct user_id) from bdlab.bigdata_user;
查询name、desn和img是否相同,来进行检验:
select count(*) from (select id,user_id,img,name,desn,author from bdlab.bigdata_user group by id,user_id,img,name,desn,author having count(*)=1)a;