原文地址:https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408
前言
很多人不明白为什么要在神经网络、逻辑回归中要在样本X的最前面加一个1,使得 X=[x1,x2,…,xn] 变成 X=[1,x1,x2,…,xn] 。因此可能会犯各种错误,比如漏了这个1,或者错误的将这个1加到W·X的结果上,导致模型出各种bug甚至无法收敛。究其原因,还是没有理解这个偏置项的作用啦。
在文章《逻辑回归》和《从逻辑回归到神经网络》中,小夕为了集中论点,往往忽略掉模型的偏置项b,但是并不代表在实际工程和严谨理论中也可以忽略掉啊,恰恰相反,这个灰常重要的。
在文章《从逻辑回归到神经网络》中,小夕为大家讲解了,一个传统的神经网络就可以看成多个逻辑回归模型的输出作为另一个逻辑回归模型的输入的“组合模型”。因此,讨论神经网络中的偏置项b的作用,就近似等价于讨论逻辑回归模型中的偏置项b的作用。
所以,我们为了减小思维量,不妨从逻辑回归模型的偏置项说起,实际上就是复习一下中学数学啦。
基础回顾
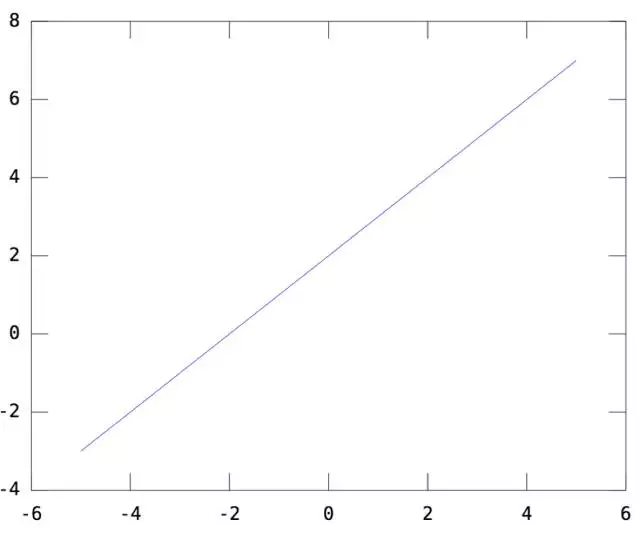
我们知道,逻辑回归模型本质上就是用 y=WX+b 这个函数画决策面,其中W就是模型参数,也就是函数的斜率(回顾一下初中数学的 y=ax+b ),而b,就是函数的截距。一维情况下,令W=[1], b=2。则y=WX+b如下(一条截距为2,斜率为1的直线):
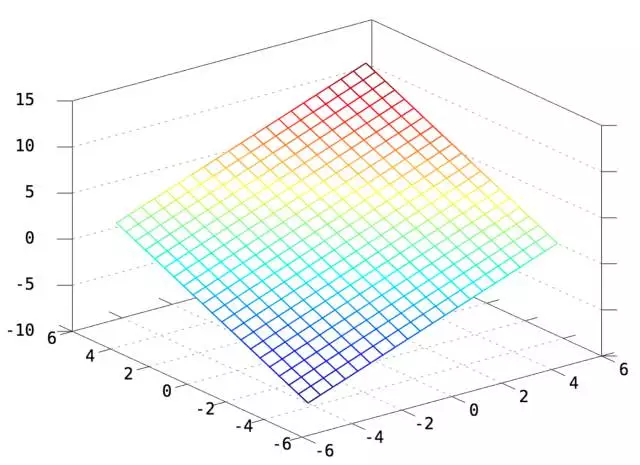
二维情况下,令W=[1 1],b=2,则y=WX+b如下(一个截距为2,斜率为[1 1]的平面)
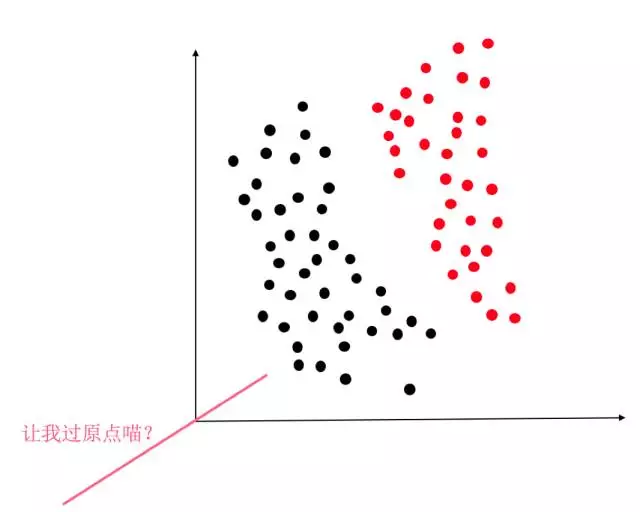
显然,y=WX+b这个函数,就是2维/3维/更高维空间的直线/平面/超平面。因此逻辑回归当然是线性分类器啦。因此如果没有这个偏置项b,那么我们就只能在空间里画过原点的直线/平面/超平面。这时对于绝大部分情况,比如下图,要求决策面过原点的话简直是灾难。
因此,对于逻辑回归来说,必须要加上这个偏置项b,才能保证我们的分类器可以在空间的任何位置画决策面(虽然必须画的直直的,不能弯,嘤…)。
神经网络的偏置项
同样的道理,对于多个逻辑回归组成的神经网络,更要加上偏置项b了。但是想一想,如果隐层有3个节点,那就相当于有3个逻辑回归分类器啊。这三个分类器各画各的决策面,那一般情况下它们的偏置项b也会各不相同的呀。比如下面这个复杂的决策边界就可能是由三个隐层节点的神经网络画出来的:
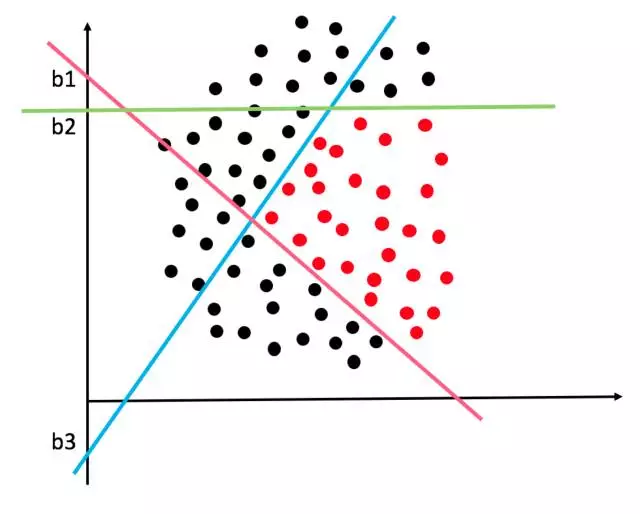
那如何机智的为三个分类器(隐节点)分配不同的b呢?或者说如果让模型在训练的过程中,动态的调整三个分类器的b以画出各自最佳的决策面呢?
那就是先在X的前面加个1,作为偏置项的基底,(此时X就从n维向量变成了n+1维向量,即变成 [1, x1,x2…] ),然后,让每个分类器去训练自己的偏置项权重,所以每个分类器的权重就也变成了n+1维,即[w0,w1,…],其中,w0就是偏置项的权重,所以1*w0就是本分类器的偏置/截距啦。这样,就让截距b这个看似与斜率W不同的参数,都统一到了一个框架下,使得模型在训练的过程中不断调整参数w0,从而达到调整b的目的。
所以,如果你在写神经网络的代码的时候,要是把偏置项给漏掉了,那么神经网络很有可能变得很差,收敛很慢而且精度差,甚至可能陷入“僵死”状态无法收敛。因此,除非你有非常确定的理由去掉偏置项b,否则不要看它小,就丢掉它哦。