本文介绍的是关联规则,分为两部分:第一部分是---不考虑用户购买的items之间严格的时序关系,每个用户有一个“购物篮”,查找其中的关联规则。第二部分--- 考虑items之间的严格的时序关系来分析用户道具购买路径以及关联规则挖掘。此文为第一部分的讲解。(本文所需的代码和数据集可以在这里下载。)
关联规则最常听说的例子是“啤酒与尿布”:购买啤酒的用户通常也会购买尿布。在日常浏览电商网站时也会出现“购买该商品的用户还会购买….”等提示,这其中应用的就是关联规则的算法。
本文重点讲解的是关联规则的R语言实现以及关联规则的可视化,这里不对关联规则的原理进行讲解,可以参考百度百科---关联规则、维基百科--- Apriori algorithm、维基百科--- Association rule learning
目录 0.创建购买记录的数据集 1.将购买记录转换为0-1矩阵 2.将0-1矩阵转换成“transcations”形式 3.删除冗余规则 4.关联规则可视化
0.创建购买记录的数据集
下面创建一个1W条购买记录的数据集,一行代表一个用户,列分别是:用户id、道具名称pname、付费金额amount、购买时间time
数据的样式如下:

###有放回地抽取1W个从10000000到10002000,作为用户id
uid<-sample(10000000:10002000,10000,replace=T)
###将日期限定在20160401 10:01:01~20160408 10:01:01,将其转换为unix时间戳的形式,也是取1W条
start_time<-as.numeric(as.POSIXct("2016/04/01 10:01:01", format="%Y/%m/%d %H:%M:%S")) end_time<-as.numeric(as.POSIXct("2016/04/08 10:01:01", format="%Y/%m/%d %H:%M:%S")) time<-sample(start_time:end_time,10000,replace=T)
#将两者合并成一个数据框orders
orders<-data.frame(uid,time)
head(orders)
###下面用P1~P20来表示购买的道具名称
pname_list<-c(1:20) for(i in 1:20){ pname_list[i]<-paste('P',i,sep="") }
#随机将道具名称传递到1W行上
orders$pname<-'P1' for(i in 1:20){ orders[sample(1:nrow(orders),1000,replace=T),'pname']<-pname_list[i] } orders$pname<-as.factor(orders$pname)
#随机将付费金额amount(1到50)传递到1W行上
orders$amount<-10 for(i in 1:50){ orders[sample(1:nrow(orders),1000,replace=T),'amount']<-i }
#查看一下数据集,看生成的模拟数据是否正常
head(orders)
summary(orders)
#将数据集写回本地
write.table(orders,'orders_test.txt',sep=' ',row.names = F,col.names = T)
1.将购买记录转换为0-1矩阵
以上只是完成了第一步:创建数据集。下面进行第二步:将购买记录转换为0-1矩阵形式,其中行表示用户,列表示商品,用1表示用户购买了该道具。
#读取数据集
payer<-read.table("orders_test.txt",sep=' ',header=T) head(payer) dim(payer)
#转换成cast1:行为用户id,列为道具,值为金额
payer2<-payer[,c('uid','pname','amount')] head(payer2) library(reshape2) melt1<-melt(payer2,id=c("uid","pname")); head(melt1)
cast1<-dcast(melt1,uid~pname,sum);
#下面查看cast1数据集的形式,注意到其中的道具(列名)是按照“字母顺序”排列的,一行代表一个用户,列表示商品,其中的值表示用户在该道具上的总付费金额,一行中所有非0的列名组成了这个用户的“购物篮”,“购物篮”是没有时间先后顺序的。
head(cast1)

#将矩阵cast1转换成0-1矩阵cast2,其中1表示用户购买了该道具
cast2<-matrix(0,ncol=ncol(cast1),nrow=nrow(cast1)) for(j in 1:ncol(cast1)){ cast2[cast1[,j]>0,j]<-1 }
#注意到其中原本为用户id的第一列全变成了1;列名不是原本的道具名
head(cast2)
#将0-1矩阵cast2的列名换成cast1的列名(道具名)
colnames(cast2)<-names(cast1); cast2<-as.data.frame(cast2) cast2$uid<-cast1$uid head(cast2)

2.将0-1矩阵转换成“transcations”形式
#将0-1转换成Apriori算法能用的“transcations”形式
cast3<-cast2[,-1]#需要先把第一列uid去掉
#此时还不能转换成transactions形式
library(arules) arules<-as(cast3,"transactions")
会提示错误:Error in asMethod(object) : column(s) … not logical or a factor. Use as.factor, as.logical or categorize first.

按照上述错误的提示,在将0-1矩阵转换成transactions前,需要先将列转换成factor 或者 logical 型,但是一定要将0-1矩阵转换为logical型而不是factor型,否则会把factor=0的数据也当做项集,后面执行Apriori算法时会消耗大量内存
#之前转换成Factor型后,执行Apriori函数,迟迟出不来结果,内存却蹭蹭蹭往上涨,直到最后宕机,后面通过测试一个小的数据集时才发现其会把factor=0的列也当做项集,尤其当行和列较多的时候,会存在海量的无效项集,从而导致内存爆满。正确方式如下:
for (j in 1:ncol(cast3)){ cast3[,j]<-as.logical(cast3[,j])#再次提醒!!!一定要将0-1矩阵转换为logical型而不是factor型 }
#转换为apriori算法可用的transactions形式
library(arules) arules<-as(cast3,"transactions")
#查看其中的项集,就是每个用户的购物篮,如下图所示
inspect(arules[1:10])

######下面执行apriori算法,将支持度support的阈值设置为0.01,置信度confidence的阈值设置为0.5,你可以根据自己的需求设置阈值。
rules<-apriori(arules,parameter = list(support=0.01,confidence=0.5))
inspect(rules)
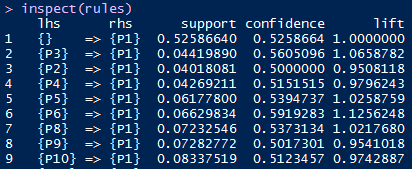
#可以按照提升度排序
sorted_lift<-sort(rules,by='lift') inspect(sorted_lift)

3.删除冗余规则
#下面进行第三步,上面满足支持度阈值和置信度阈值的规则共有152条,其中有很多的冗余规则,冗余规则的定义是:如果rules2的lhs和rhs是包含于rules1的,而且rules2的lift小于或者等于rules1,则称rules2是rules1的冗余规则。下面对冗余规则进行删除。
subset.matrix<-is.subset(rules,rules)#生成一个所有规则的子集矩阵,行和列分别是每条rules,其中的值是TRUE和FALSE,当rules2是rules1的子集时,rules2在rules1的值为TRUE subset.matrix[lower.tri(subset.matrix,diag=T)]<-NA#将矩阵对角线以下的元素置为空,只保留上三角 redundant<-colSums(subset.matrix,na.rm=T)>=1#R会将矩阵中的TRUE当做1,统计每列的和(忽略缺失值),如果该列的和大于等于1,也就是表示该列(规则)是别的规则的子集,应该删除。 rules.pruned<-rules[!redundant]#去掉冗余的规则
#原本152条规则精简到4条规则
inspect(rules.pruned)

#写回本地
write(rules.pruned,"rules_pruned.txt",col.names=NA)
4.关联规则可视化
直接plot画出散点图:
plot(rules)

图中的点颜色越深,表示lift值越大,可以看到lift值高的点集中在低support上。另外也有一些人认为最有意思的规则在support/conf的边沿上。
可以使用interactive=TRUE来实现散点图的互动功能,可以选中一些点查看其具体的规则
plot(rules,interactive=TRUE)

还有类似“气泡图”的展现形式:提升度lift是圈的颜色深浅,圈的大小表示支持度support的大小。LHS的个数和分组中最重要(频繁)项集显示在列的标签里。lift从左上角到右下角逐渐减少。
plot(rules, method = "grouped")

通过箭头和圆圈来表示关联规则,利用顶点代表项集,边表示规则中关系。圆圈越大表示支持度support越大,颜色越深表示提升度lift越大。但是如果规则较多的话会显得很混乱,难以发现其中的规律,因此,通常只对较少的规则使用这样的图,如下是对lift的top10条规则进行可视化。
plot(sorted_lift[1:10], method = "graph")

以上,就是关联规则的R语言实现以及关联规则的可视化,这里不考虑用户购买items之间的时序关系,而是从用户“购物篮”中去挖掘关联规则,下一篇将考虑items之间的严格的时序关系来分析用户道具购买路径以及关联规则挖掘。本文所需的代码和数据集可以在这里下载。