今天做实验【Spark SQL 编程初级实践】,虽然网上有答案,但在自己的环境下并不能够顺利进行
在第二题中,要求编程实现将 RDD 转换为 DataFrame。根据所谓标准答案,在进行sbt 打包时,报如下错误
[error] /home/hadoop/mycode/rddtodf/src/main/scala/rddtodf.scala:1: object types is not a member of package org.apache.spark.sql
[error] import org.apache.spark.sql.types._
[error] ^
[error] /home/hadoop/mycode/rddtodf/src/main/scala/rddtodf.scala:2: object Encoder is not a member of package org.apache.spark.sql
[error] import org.apache.spark.sql.Encoder
……
截图:
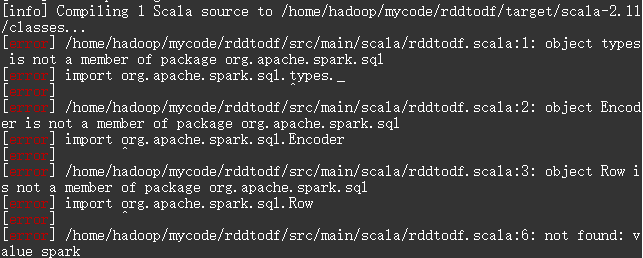
根据错误描述可知,程序在第一行 import org.apache.spark.sql.types._ 处出错:types不是org.apache.spark.sql的成员
解决方案:
把程序每一行看作一个spark命令,在spark-shell一条一条地执行好了。。。
第三题【编程实现利用 DataFrame 读写 MySQL 的数据】
读取mysql?一定要用到 mysql-connector-java-xxx.jar 吧,但是答案中并未提及
查阅书籍了解到,需要把mysql的jar包放在 /usr/local/spark/jars/mysql-connector-java-xxx/文件夹下,其中/usr/local/spark是spark安装目录xxx是mysql jar包版本。
且启动Spark Shell时,须指定MySQL jar包,如图:
 (表示命令还没有结束)
(表示命令还没有结束)
然后再把程序一条一条执行
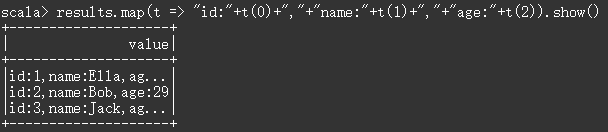
执行结果:
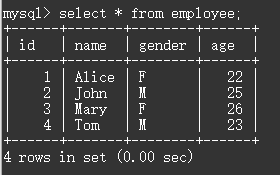
可以看到,已经将新的两条数据插入到mysql数据库了
(用时:1小时30分钟)