一、使用request和get访问某个网页20次并且打印返回状态,内容
扩展:常见状态码含义 200 - 服务器成功返回网页,404 - 请求的网页不存在,403(禁止)服务器拒绝请求,404(未找到)服务器找不到请求的网页,503 - 服务器超时,3xx (重定向)
(1)request库简介:处理HTTP请求的第三方库,建立在urllib3库的基础上
(2)常用函数 get(url[,timeout = n ]), post
delete,head,options,put等等
(3)status_code返回状态。 text返回字符串形式。encoding返回编码方式。content返回二进制形式。注:response.text是解过码的字符串(比如html代码)。当requests发送请求到一个网页时,requests库会推测目标网页的编码,并对其解码,转为字符串(str)。这种方法比较容易出现乱码。
(4)实例代码
import requests r = requests.get('https://www.sogou.com/', timeout = 4) #使用get方式请求搜狗网站 print("状态码 = {}".format( r.status_code))#输出状态码 print("text内容 = {}".format(r.text)) print("编码方式 = {}".format(r.encoding)) print("二进制形式 = {}".format(r.content))
(5)输出结果:
状态码 = 200
。。。。。。。。。。。。。。。。省略
编码方式 = UTF-8
二进制形式 = b'<!DOCTYPE。。。。。。。。。。。。省略
(6)测试连续访问20次的结果

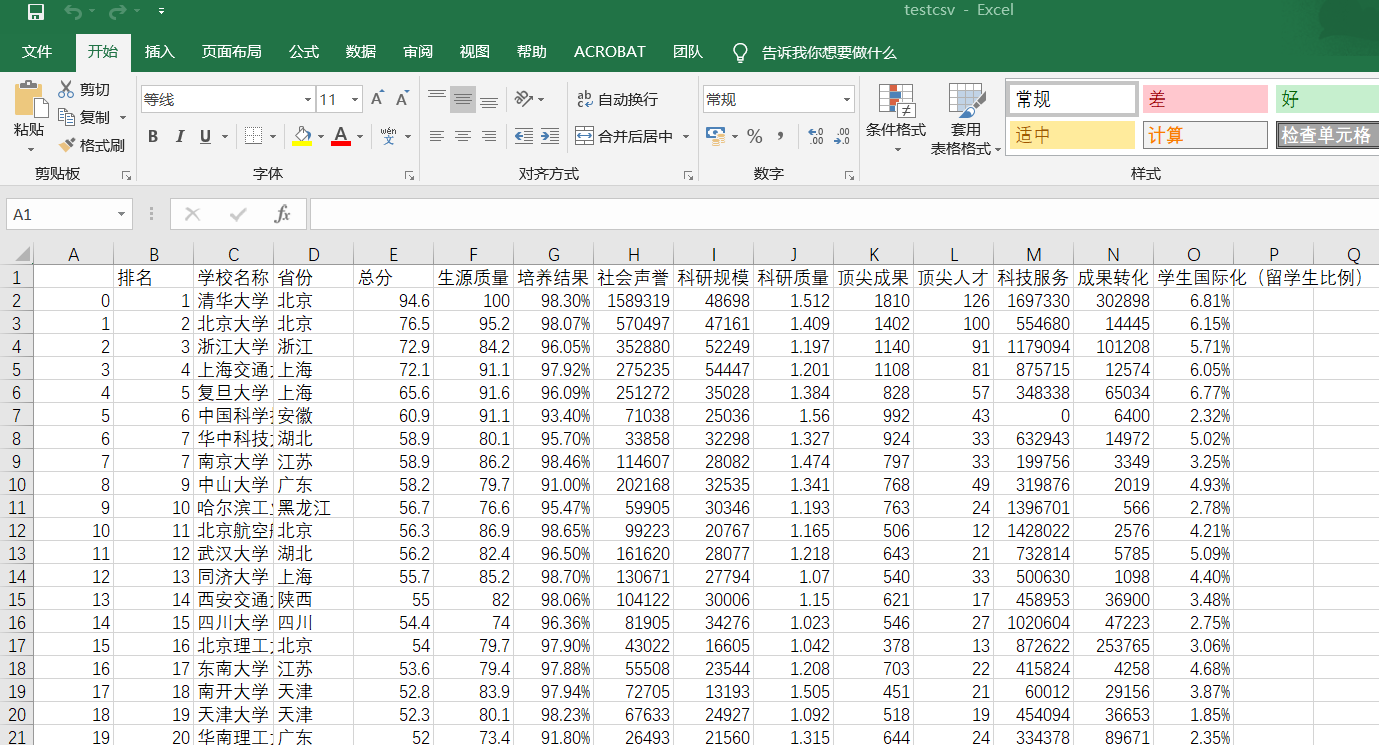
二、爬取中国大学排名
from bs4 import BeautifulSoup import requests import pandas as pd allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=10) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def filUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd) == 0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) write_csv(allUniv) def write_csv(list): name = ['排名', '学校名称', '省份', '总分', '生源质量(新生高考成绩得分)', '培养结果(毕业生就业率)', '社会声誉(社会捐赠收入·千元)', '科研规模(论文数量·篇)', '科研质量(论文质量·FWCI)', '顶尖成果(高被引论文·篇)', '顶尖人才(高被引学者·人)', '科技服务(企业科研经费·千元)', '成果转化(技术转让收入·千元)', '学生国际化(留学生比例)'] name2 = ['a', 'b', 'c'] test = pd.DataFrame(columns=name, data=list) test.to_csv('e:/testcsv.csv', encoding='gbk') def main(): url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") filUnivList(soup) print("完成") main()
效果图: