Redis简介
Redis数据类型丰富,支持数据磁盘持久化存储,支持主从,支持分片。完全基于内存,绝大部分请求是基于内存的操作,执行效率高。采用单线程,单线程也能处理高并发请求。使用多路I/O复用模型,非阻塞IO。
Redis数据结构
String:最基本的数据类型,二进制安全
Hash:String元素组成的字典,适用于存储对象
List:列表,按照String元素插入顺序排序
Set:String元素组成的无序集合,通过哈希表实现,不允许重复
Sorted Set:通过分数来为集合中的成员进行从小到大的排序
HyperLogLog:用于计数
Geo:支持存储地理位置信息
从海量数据里查询出某一个固定前缀key
keys pattern:查询所有符合给定模式pattern的key
keys指令一次性返回所有匹配的key
键的数量过大会使服务卡顿
scan cursor [MATCH pattern] [COUNT count]
基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
以0作为游标开始一次新的迭代,知道命令返回游标0完成一次遍历
不保证每次执行都返回某个给定数量的元素,支持模糊查询
一次返回的数量不可控,只能是大概率符合count的参数
分布式锁
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置键的过期时间为second秒
PX millisecond:设置键的过期时间为millisecond毫秒
NX:只有键不存在时,才对键进行设置操作
XX:只有键已经存在时,才对键进行设置操作
set操作成功完成时,返回OK,否则返回nil
redis 设置过期时间
定期删除+惰性删除
- 定期删除:redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
- 惰性删除 :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。
redis 内存淘汰机制
redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的).
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。
持久化方式
RDB(快照)持久化:保存某个时间点的全量数据快照
采用方式 BGSAVE:Fork出一个子进程来创建RDB文件,不阻塞服务器进程
优点:全量数据快照,文件小,恢复快。 缺点:无法保存最近一次的快照
AOF(Append-Only-File)持久化:保存写状态
记录下除了查询以外的所有变更数据库状态的指令
以append的形式追加保存到AOF文件中(增量)
使用 AOF 持久化需要设置同步选项,从而确保写命令什么时候会同步到磁盘文件上。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘

Redis可采用RDB-AOF混合持久化的方式:BGSAVE做镜像全量持久化,AOF做增量持久化
Redis集群
分片:按照某种规则去划分数据,分散存储在多个节点上
采用一致性哈希算法:对2^32取模,将哈希值空间组织成虚拟的圆环。将数据key使用相同的函数Hash计算出哈希值,redis节点可以通过IP地址计算出哈希值。每个key通过顺时针去找出离它最近的节点进行存储。
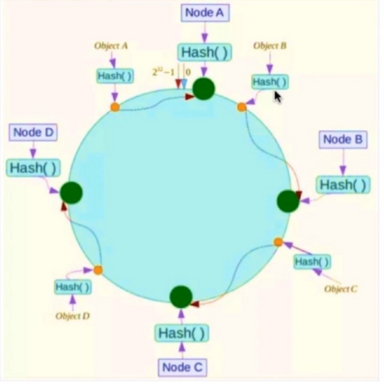
这样不管时增加机器还是减少机器,都能提供最小化的有损服务,只需要重新定位一小部分数据,具有较好的容错性和扩展性。
但是节点的分布不均匀,也有可能存在Hash环的数据倾斜问题
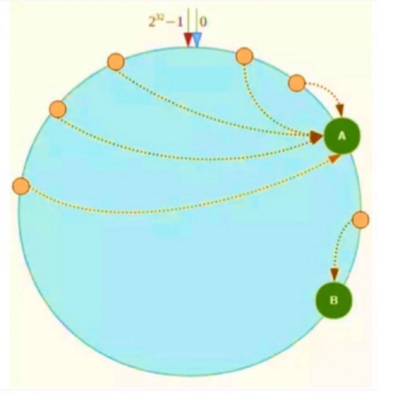
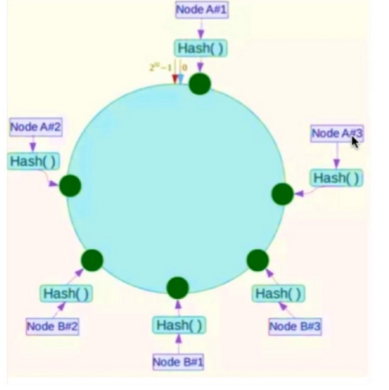
可以通过引入虚拟节点来解决数据倾斜的问题,也就是说每个节点都分配一定数量的虚拟节点,从而让key能更加均匀地分配到各个节点中
参考:https://github.com/Snailclimb/JavaGuide/blob/master/%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8/Redis/Redis.md