首先,在电脑上安装jieba库,进入命令提示符,输入pip install jieba,接下来就等系统自动安装
然后再进入IDLE建立一个脚本,用open函数打开只读模式,用jieba.lcut函数剪下词组,对每一个剪下的词组进行统计,最后输出。
1 import jieba 2 txt = open(r"F:清道夫.txt", "r", encoding='utf-8').read() 3 words = jieba.lcut(txt) 4 counts = {} 5 for word in words: 6 if len(word) == 1: #排除单个字符的分词结果 7 continue 8 else: 9 counts[word] = counts.get(word,0) + 1 10 items = list(counts.items()) 11 items.sort(key=lambda x:x[1], reverse=True) 12 for i in range(10): 13 word, count = items[i] 14 print ("{0:<10}{1:>5}".format(word, count))
运行结果如下
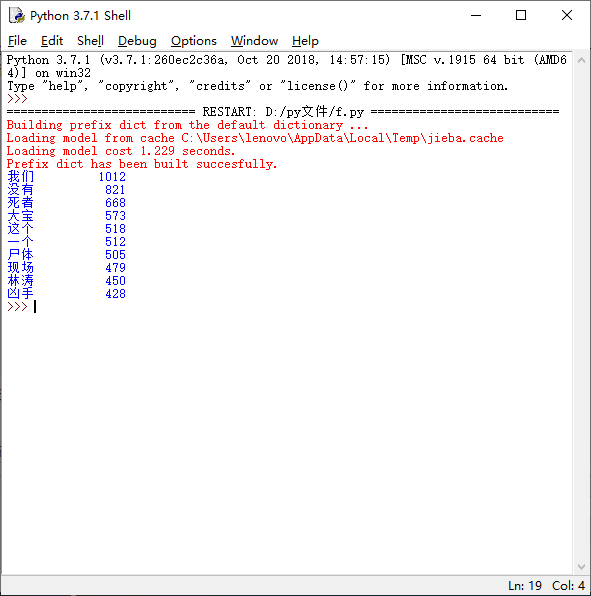
然后来绘制词云,需要先安装wordcloud库,还是用上面的方法,pip install wordcloud,安装好之后,执行如下代码
from wordcloud import WordCloud with open("F:清道夫.txt",encoding="utf-8")as file: text=file.read() wordcloud=WordCloud( font_path="C:/Windows/Fonts/simfang.ttf", background_color="white", width=600, height=300,max_words=50).generate(text) image=wordcloud.to_image() image.show()
效果如下
