GDB的深入研究
一、GDB代码调试
(一)GDB调试实例
- 在终端中编译一个示例C语言小程序,保存为文件 gdblianxi.c 中,用GCC编译。


- 在上面的命令行中,使用
-o参数指定了编译生成的可执行文件名为 gdblianxi,使用参数-g表示将源代码信息编译到可执行文件中。如果不使用参数-g,会给后面的GDB调试造成不便。 - 下面输入“gdb”命令启动GDB,将首先显示GDB说明:

- 下面使用“file”命令载入被调试程序 gdblianxi(这里的 gdblianxi 即前面 GCC 编译输出的可执行文件)

- 上图中最后一行“(gdb) ”为GDB内部命令引导符,等待用户输入GDB命令。
- 上图倒数第二行提示已经加载成功。
- 下面使用“r”命令执行(Run)被调试文件,因为尚未设置任何断点,将直接执行到程序结束
- 使用“b”命令在 main 函数开头设置一个断点(Breakpoint)
- 之后一行提示已经成功设置断点,并给出了该断点信息:在源文件 gdblianxi.c 第14行处设置断点;这是本程序的第一个断点(序号为1);断点处的代码地址为 0x40055d。向上看源代码,第14行中的代码为“n = 1”,恰好是 main 函数中的第一个可执行语句(因为前面的“int n;”为变量定义语句,并非可执行语句)。
- 再次使用“r”命令执行(Run)被调试程序:

- 程序中断在gdblianxi.c第14行处,即main函数是第一个可执行语句处。 上面最后一行信息为:下一条将要执行的源代码为“n = 1;”,它是源代码文件gdblianxi.c中的第14行。
- 下面使用“s”命令(Step)执行下一行代码(即第14行“n = 1;”):

-
上面的信息表示已经执行完“n = 1;”,并显示下一条要执行的代码为第15行的“n++;”。
-
下面我们分别在第21行打印处、tempFunction 函数开头各设置一个断点(分别使用命令“b 21”“b tempFunction”):

- 使用“c”命令继续(Continue)执行被调试程序,程序将中断在第二个断点(21行),此时全局变量 nGlobalVar 的值应该是 88;再一次执行“c”命令,程序将中断于第三个断点(7行,tempFunction 函数开头处),此时tempFunction 函数的两个参数 a、b 的值应分别是 1 和 2:

- 再一次执行“c”命令(Continue),因为后面再也没有其它断点,程序将一直执行到结束:

(二)GDB常用命令
| 命令 | 解释 | 示例 |
|---|---|---|
| file <文件名> | 加载被调试的可执行程序文件。 因为一般都在被调试程序所在目录下执行GDB,因而文本名不需要带路径 |
(gdb) file gdblianxi |
| r | Run的简写,运行被调试的程序。 如果此前没有下过断点,则执行完整个程序;如果有断点,则程序暂停在第一个可用断点处。 |
(gdb) r |
| c | Continue的简写,继续执行被调试程序,直至下一个断点或程序结束。 | (gdb) c |
| b <行号> b <函数名称> b * <函数名称> b * <代码地址> d [编号] |
b: Breakpoint的简写,设置断点。两可以使用“行号”“函数名称”“执行地址”等方式指定断点位置。 其中在函数名称前面加“*”符号表示将断点设置在“由编译器生成的prolog代码处”。如果不了解汇编,可以不予理会此用法。 d: Delete breakpoint的简写,删除指定编号的某个断点,或删除所有断点。断点编号从1开始递增。 |
(gdb) b 8 (gdb) b main (gdb) b * main (gdb) b * 0x804835c (gdb) d |
| s, n | s: 执行一行源程序代码,如果此行代码中有函数调用,则进入该函数; n: 执行一行源程序代码,此行代码中的函数调用也一并执行。 s 相当于其它调试器中的“Step Into (单步跟踪进入)” n 相当于其它调试器中的“Step Over (单步跟踪)” 这两个命令必须在有源代码调试信息的情况下才可以使用(GCC编译时使用“-g”参数)。 |
(gdb) s (gdb) n |
| si, ni | si命令类似于s命令,ni命令类似于n命令。 所不同的是,这两个命令(si/ni)所针对的是汇编指令,而s/n针对的是源代码。 |
(gdb) si (gdb) ni |
| p <变量名称> | Print的简写,显示指定变量(临时变量或全局变量)的值。 | (gdb) p i (gdb) p nGlobalVar |
| display ... undisplay <编号> |
display,设置程序中断后欲显示的数据及其格式。 例如,如果希望每次程序中断后可以看到即将被执行的下一条汇编指令,可以使用命令“display /i $pc” 其中 $pc 代表当前汇编指令,/i 表示以十六进行显示。当需要关心汇编代码时,此命令相当有用。 undispaly,取消先前的display设置,编号从1开始递增。 |
(gdb) display /i $pc (gdb) undisplay 1 |
| i | Info的简写,用于显示各类信息,详情请查阅“help i”。 | (gdb) i r |
| q | Quit的简写,退出GDB调试环境。 | (gdb) q |
| help [命令名称] | GDB帮助命令,提供对GDB名种命令的解释说明。 如果指定了“命令名称”参数,则显示该命令的详细说明;如果没有指定参数,则分类显示所有GDB命令,供用户进一步浏览和查询。 |
(gdb) help display |
二、CGDB代码调试
- cgdb可以看作gdb的界面增强版,cgdb主要功能是在调试时进行代码的同步显示,这增加了调试的方便性,提高了调试效率。其他功能则与gdb一样,可使用其常用命令。所以这里只做简单介绍,常用命令等参见gdb。
主要功能介绍:
(1)相比GDB,增加了语法加亮的代码窗口,显示在GDB窗口的上部,随GDB的调试位置代码同步显示。
(2)断点设置可视化 。
(3)在代码窗口中可使用GDB常用命令 。
(4)在代码窗口可进行代码查找,支持正则表达式 。
界面及使用说明
(1)代码窗口
调试时同步显示被调试程序源代码,自动标记出程序运行到的位置。当焦点在代码窗口时,可以浏览代码、查找代码以及执行命令 ,操作方式同vi 。常用命令如下:
i : 焦点切换到GDB窗口 。
o :打开文件选择框,可选择要显示的代码文件 。
空格 :设置/取消断点 。
k:向上移动
j:向下移动
/:查找
(2)状态条窗口
- 同vi的状态条,一般显示当前打开的源文件名,当代码窗口进入命令状态时,显示输入的命令等信息
(3)GDB窗口
-
CGDB的操作界面,同GDB ,按ESC键则焦点切换到代码窗口 。
-
启动&退出——启动:cgdb;退出:在代码窗口或GDB窗口,执行quit命令 。
代码实现:


“(gdb)”表示GDB已经启动,等待我们输入命令。此时程序并未开始运行,输入“run”开始运行程序。这种方式在GDB内部运行程序:

List n,m表示显示n到m行的代码

设置断点,break n,用step单步执行(这里break 21):

三、汇编代码调试
汇编级的调试或跟踪,需要用到display命令“display /i $pc”,如上表所示,
“display /i $pc”
其中 $pc 代表当前汇编指令,/i 表示以十六进行显示。当需要关心汇编代码时,此命令相当有用。
undispaly,取消先前的display设置,编号从1开始递增。

并且以后程序每次中断都将显示下一条汇编指定(“si”命令用于执行一条汇编代码——区别于“s”执行一行C代码)

接下来我们试一下命令“b *<函数名称>”。 为了更简明,有必要先删除目前所有断点(使用“d”命令——Delete breakpoint)

当被询问是否删除所有断点时,输入“y”并按回车键即可。
下面使用命令“b *main”在 main 函数的 prolog 代码处设置断点(prolog、epilog,分别表示编译器在每个函数的开头和结尾自行插入的代码):


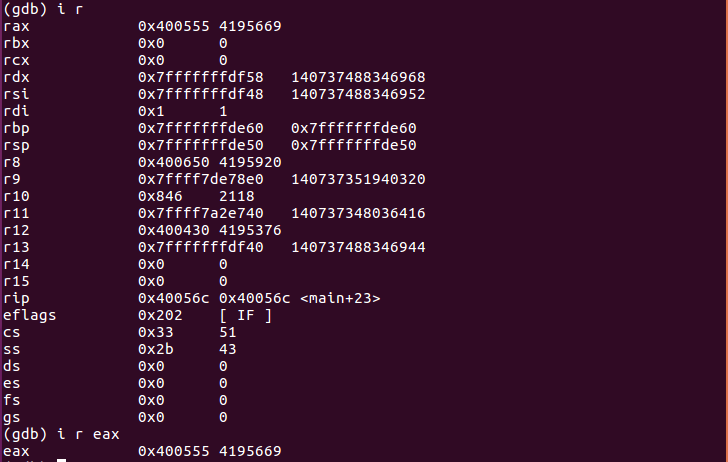
此时可以使用“i r”命令显示寄存器中的当前值———“i r”即“Infomation Register”,
也可以输入“i r 寄存器名”显示任意一个指定的寄存器值:
最后输入命令“q”,退出(Quit)GDB调试环境

四、DDD代码调试
(一)DDD简介
- DDD,全称是Data Display Debugger,对于Linux系统中的编程人员来说,它就是windows系统下面的visual studio ,功能强大,是Linux世界中少数有图形界面的程序调试工具。DDD是命令行调试器的图形前端,除了一般的程序调试功能以外,还具有交互式图形数据显示的功能。它在嵌入式应用开发中也十分出色。DDD最初源于1990年Andreas Zeller编写的VSL结构化语言,后来经过一些程序员的努力,演化成今天的模样。DDD的功能非常强大,可以调试用CC++、Ada、 Fortran、Pascal、Modula-2和Modula-3编写的程序;可以超文本方式浏览源代码;能够进行断点设置、回溯调试和历史纪录编辑;具有程序在终端运行的仿真窗口,并在远程主机上进行调试的能力;图形数据显示功能(Graphical Data Display)是创建该调试器的初衷之一,能够显示各种数据结构之间的关系,并将数据结构以图形化形式显示;具有GDB/DBX/XDB的命令行界面,包括完全的文本编辑、历史纪录、搜寻引擎。
(二)DDD调试过程
打开终端命令行窗口,输入命令vi testddd.c,建立testddd.c文件作为之后调试的文件:
在testddd.c文件中输入一些C语言的程序数据,DDD工具可以调试很多种程序设置基于的代码,本次调试以C语言作为说明对象。

把testddd.c文件编译成可以执行的文件testddd,命令:gcc -g -o testddd testddd.c,注意一定要带-g参数,否则生成的可执行文件中没有必要的调试信息,最终使用DDD工具不能调试。
运行DDD调试工具,直接输入命令ddd就可以打开DDD工具。

DDD工具打开后如下图所示,上面较大空白部分为代码区,和工具区,分割线下面是调试生成信息区。

点击菜单栏上的“文件”----->“打开程序”,准备打开我们上面准备的testddd.c文件
在打开程序框中,定位到我们要调试的程序的目录下,在Files列表下选择我们要调试 信息,之后点击左下方的打开按钮。

调试程序打开后,在代码区可以看到我们的代码,右边的一些按钮是我们调试要用的工具。

在代码区点鼠标右键,会弹出如图所示的菜单:

我们可以给程序设置断点等,点击工具区里面的Run按钮,可以执行程序,在下面的调试信息区可以看到程序的执行结果。

如上图所示:在鼠标右键点击的地方设置了断点,在下方调试信息生成区显示了程序运行的输入信息。
PS:也可以在Terminal中输入ddd 文件名来直接打开ddd调试该文件的界面:

在怀疑程序哪个变量为可疑变量时,可以在控制台输入如下命令

或者在主窗口原程序中点击某个变量如sum选中该变量,右击后选择display sum 选项就会看到该变量的值在主窗口的上方。 接着往下单步运行,多次点击工具栏中的“Step”按钮,观察变量sum的结果。

如果问题出在count上。这时点击命令工具栏上的“Kill”按钮将程序断掉,把初始化sum的那一句改正确。重新运行之后,发现结果正确,调试过程完毕。
(三)常用命令简介
run 执行程序
step 单步调试
kill 杀死正在运行的程序
interrupt 退出此次调试回到原始状态
- DDD的数据显示功能非常强大。
- 对于固定大小的数组,用鼠标选中数组名,点击plot按钮即可画出图形。
- 对于变长数组,可以使用graph plot数组名[起始索引] @ 数组大小的命令来显示。
- 对于复杂的数据结构,DDD也可以用图形方式解析: DDD有一个detect aliases的选项,可以智能的判别数据是否会被重复显示。这种方式通过内存地址的检测来实现的。
五、段错误
- 定义:段错误是指访问的内存超出了系统给这个程序所设定的内存空间,例如访问了不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址等等情况。
段错误产生的原因:
(1) 访问不存在的内存地址
(2) 访问系统保护的内存地址
(3) 访问只读的内存地址
(4) 栈溢出
下面以原因一访问不存在的内存地址为例,进行实践。
(一)使用gcc和gdb(对于简单代码)
- 首先,编写一段代码,访问不存在内存地址。编译后进入CGDB,运行程序:

-
从输出中可以看出,程序收到SIGSEGV信号,触发段错误,并提示0x00000000004004e6、调用main报的错,在Derro.c中23行。并且在代码窗口第23行被标记出来。
-
适用场景
仅当能确定程序一定会发生段错误的情况下使用。
当程序的源码可以获得的情况下,使用-g参数编译程序。
一般用于测试阶段,生产环境下gdb会有副作用:使程序运行减慢,运行不够稳定,等等。
即使在测试阶段,如果程序过于复杂,gdb也不能处理。
(二)使用core文件和gdb
- 提到段错误会触发SIGSEGV信号,通过man 7 signal,可以看到SIGSEGV默认的handler会打印段错误出错信息,并产生core文件,由此我们可以借助于程序异常退出时生成的core文件中的调试信息,使用gdb工具来调试程序中的段错误。
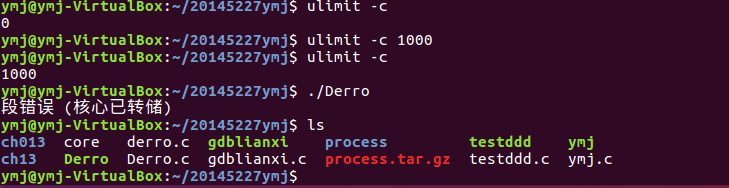
- 查看core文件发现不存在:

- 查看系统core文件的大小限制,发现为0,这样不会自动生成core文件。把大小设置为1000。运行程序后再次查看可看到存在core文件:
- 加载core文件,使用gdb工具进行调试。从输出中可以看出同样的段错误信息:

六、多进程与多线程
(一)多进程
1、进程的基本概念
- 进程定义了一个计算的基本单元,可以认为是一个程序的一次运行。它是一个动态实体,是独立的任务。它拥有独立的地址空间、执行堆栈、文件描述符等。 每个进程拥有独立的地址空间,进程间正常情况下,互不影响,一个进程的崩溃不会造成其他进程的崩溃。 当进程间共享某一资源时,需注意两个问题:同步问题和通信问题。
2、创建进程
- 父进程通过调用fork函数来创建一个新的运行子进程。fork函数定义如下:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
- fork函数只被调用一次,但是会返回两次:父进程返回子进程的PID,子进程返回0.如果失败返回-1。
- fork后,子进程和父进程继续执行fork()函数后的指令。子进程是父进程的副本。子进程拥有父进程的数据空间、堆栈的副本。但父、子进程并不共享这些存储空间部分。如果代码段是只读的,则父子进程共享代码段。如果父子进程同时对同一文件描述字操作,而又没有任何形式的同步,则会出现混乱的状况; 父进程中调用fork之前打开的所有描述字在函数fork返回之后子进程会得到一个副本。fork后,父子进程均需要将自己不使用的描述字关闭,有两方面的原因:(1)以免出现不同步的情况;(2)最后能正常关闭描述字


- 在BSD3.0中开始出现,主要为了解决fork昂贵的开销。它是完全共享的创建,新老进程共享同样的资源,完全没有拷贝。 两者的基本区别在于当使用vfork()创建新进程时,父进程将被暂时阻塞,而子进程则可以借用父进程的地址空间。这个奇特状态将持续直到子进程退出或调用execve()函数,至此父进程才继续执行。


3、终止进程
进程的终止存在两个可能:(1)父进程先于子进程终止(init进程领养) (2)子进程先于主进程终止。对于后者,系统内核为子进程保留一定的状态信息:进程ID、终止状态、CPU时间等;当父进程调用wait或waitpid函数时,获取这些信息; 当子进程正常或异常终止时,系统内核向其父进程发送SIGCHLD信号;缺省情况下,父进程忽略该信号,或者提供一个该信号发生时即被调用的函数。
#include <stdlib.h>
void exit(int status);
- 本函数终止调用进程。关闭所有子进程打开的描述符,向父进程发送SIGCHLD信号,并返回状态。
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *stat_loc);
-
返回:终止子进程的ID-成功;-1-出错;statloc存储子进程的终止状态(一个整数);
-
如果没有终止的子进程,但是有一个或多个正在执行的子进程,则该函数将堵塞,直到有一个子进程终止或者wait被信号中断时,wait返回。 当调用该系统调用时,如果有一个子进程已经终止,则该系统调用立即返回,并释放子进程所有资源。
pidt waitpid(pidt pid, int *statloc, int options);
- 返回:终止子进程的ID-成功;-1-出错;statloc存储子进程的终止状态;
- 当pid=-1,option=0时,该函数等同于wait,否则由参数pid和option共同决定函数行为,其中pid参数意义如下:
-1:要求知道任何一个子进程的返回状态(等待第一个终止的子进程);
>0:要求知道进程号为pid的子进程的状态;
<-1: wait for any child process whose process group ID is equal to the absolute value of pid.
-
Options最常用的选项是WNOHANG,它通知内核在没有已终止进程时不要堵塞。
-
调用wait或waitpid函数时,正常情况下,可能会有以下几种情况:
阻塞(如果其所有子进程都还在运行);
获得子进程的终止状态并立即返回(如果一个子进程已终止,正等待父进程存取其终止状态);
出错立即返回(如果它没有任何子进程)


4、调试进程
- 一般情况下,父进程fork一个子进程,gdb只会继续调试父进程而不会管子进程的运行。如果想跟踪子进程进行调试,可以使用
set follow-fork-mode mode来设置fork跟随模式。 - set follow-fork-mode 所带的mode参数可以是以下的一种:
parent gdb只跟踪父进程,不跟踪子进程,这是默认的模式。
child gdb在子进程产生以后只跟踪子进程,放弃对父进程的跟踪。
- 进入gdb以后,我们可以使用
show follow-fork-mode来查看目前的跟踪模式。

-
可以看到目前使用的模式是parent。
-
有时,我们想同时调试父进程和子进程,以上的方法就不能满足了。Linux提供了
set detach-on-fork mode命令来供我们使用。其使用的mode可以是以下的一种:
on 只调试父进程或子进程的其中一个(根据follow-fork-mode来决定),这是默认的模式。
off 父子进程都在gdb的控制之下,其中一个进程正常调试(根据follow-fork-mode来决定)
- 另一个进程会被设置为暂停状态。
- 同样,
show detach-on-fork显示了目前是的detach-on-fork模式,如图所示。

- 以上是调试fork产生子进程的情况,但是如果子进程使用exec系统函数而装载了新程序执行,我们就使用set follow-exec-mode mode提供的模式来跟踪这个exec装载的程序。mode可以是以下的一种:
new 当发生exec的时候,如果这个选项是new,则新建一个inferior给执行起来的子进程,而父进程的inferior仍然保留,当前保留的inferior的程序状态是没有执行。
same 当发生exec的时候,如果这个选项是same(默认值),因为父进程已经退出,所以自动在执行exec的inferior上控制子进程。
(二)多线程
- 线程:运行在单一进程上下文中的逻辑流,由内核进行调度,共享同一进程的虚拟地址空间。
基于线程的并发编程
- 线程由内核自动调度,每个线程都有它自己的线程上下文(thread context),包括一个惟一的整数线程ID(Thread ID,TID),栈,栈指针,程序计数器,通用目的寄存器和条件码。每个线程和其他线程一起共享进程上下文的剩余部分,包括整个用户的虚拟地址空间,它是由只读文本(代码),读/写数据,堆以及所有的共享库代码和数据区域组成的,还有,线程也共享同样的打开文件的集合。
- 线程不像进程那样,不是按照严格的父子层次来组织的。和一个进程相关的线程组成一个对等线程池,独立于其他线程创建的线程。进程中第一个运行的线程称为主线程。对等(线程)池概念的主要影响是,一个线程可以杀死它的任何对等线程,或者等待它的任意对等线程终止;进一步来说,每个对等线程都能读写相同的共享数据。
- 线程是可执行代码的可分派单元。这个名称来源于“执行的线索”的概念。在基于线程的多任务的环境中,所有进程有至少一个线程,但是它们可以具有多个任务。这意味着单个程序可以并发执行两个或者多个任务。
- 简而言之,线程就是把一个进程分为很多片,每一片都可以是一个独立的流程。这已经明显不同于多进程了,进程是一个拷贝的流程,而线程只是把一条河流截成很多条小溪。它没有拷贝这些额外的开销,但是仅仅是现存的一条河流,就被多线程技术几乎无开销地转成很多条小流程,它的伟大就在于它少之又少的系统开销。
linux提供的多线程的系统调用:
(1)函数pthread_create用来创建一个线程,它的原型为:
extern int pthread_create __P ((pthread_t *__thread, __const pthread_attr_t *__attr,void *(*__start_routine) (void *), void *__arg));
第一个参数为指向线程标识符的指针,第二个参数用来设置线程属性,第三个参数是线程运行函数的起始地址,最后一个参数是运行函数的参数。
(2)函数pthread_join用来等待一个线程的结束。函数原型为:
2extern int pthread_join __P ((pthread_t __th, void **__thread_return));
第一个参数为被等待的线程标识符,第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。
(3)一个线程的结束有两种途径,一种是象我们上面的例子一样,函数结束了,调用它的线程也就结束了;另一种方式是通过函数pthread_exit来实现。它的函数原型为:
extern void pthread_exit __P ((void *__retval)) __attribute__ ((__noreturn__));
唯一的参数是函数的返回代码,只要pthread_ join中的第二个参数thread_ return不是NULL,这个值将被传递给 thread_return。
最后要说明的是,一个线程不能被多个线程等待,否则第一个接收到信号的线程成功返回,其余调用pthread_join的线程则返回错误代码ESRCH。
-
Linux系统下的多线程遵循POSIX线程接口,称为pthread。编写Linux下的多线程程序,需要使用头文件pthread.h,连接时需要使用库libpthread.a。Linux下pthread的实现是通过系统调用clone()来实现的。clone()是Linux所特有的系统调用,它的使用方式类似fork。
-
下面代码示例:


-
代码分析:主线程做自己的事情,生成2个子线程,task1为分离,任其自生自灭,而task2还是继续送外卖,需要等待返回。
-
编译运行:


- 多次运行发现结果并不完全相同,这是不同的线程抢占CPU的结果。
七、心得体会
这篇GDB的深入研究是我做的第一个加分项目,到此算是告一段落了。在做之前,一直感觉GDB调试是很困难的一件事,但是自己真正去实践才发现它并没有我想象中的那么难。这次我完成了GDB代码调试、CGDB代码调试、汇编代码调试、DDD代码调试以及多进程与多线程的学习,中途也遇到过很多问题,但是通过查阅资料,参考之前的学长学姐的经验最终都解决了。不知不觉,写博客已经有一年的时间了,这门课程也快结束了。从一开始的烦躁到后面的适应再到习惯,自己自主学习的能力提升了太多。以后继续加油!