20145227《信息安全系统设计基础》第十三周学习总结
第十一章 网络编程
客户端-服务器编程模型
1.每个网络应用都是基于客户端-服务器模型的。采用这个模型,一个应用是由一个服务器进程和一个或者多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源来为它的客户端提供某种服务。
eg:一个Web服务器管理了一组磁盘文件,它为客户端进行它会为客户端进行存储和检索。一个FTP管理了一组磁盘文件。相似地一个电子邮件服务器管理了一些文件,它为客户端进行读和更新。
2.客户端-服务器模型中的基本操作是事务。
3.一个客户端-服务器事务由四步组成
- (1)当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务。例如,当Web览器需要一个文件时,它就发送一个请求给Web服务器
- (2)服务器收到请求后,解释它,并以适当的方式操作它的资源。例如,当Web服务器收到浏览器发出的请求后,它就读一个磁盘文件
- (3)服务器给客户端发送一响应,并等待下一个请求。例如,Web服务器将文件发送回客户端;
- (4)客户端收到响应并处理它。例如,当Web浏览器收到来自服务器的一页后,它就在屏幕上显示此页。
网络
- 客户端和服务器通常运行在不同的主机上,并且通过计算机网络的硬件和软件资源来通信。
- 对于一个主机而言,网络只是又一种I/O设备,作为数据源和数据接收方。
- 一个插到I/O总线扩展槽的适配器提供了到网络的物理接口。从网络上接收到的数据从适配器经过I/O和存储器总线拷贝到存储器,典型地是通过DMA(译者注:直接存储器存取方式)传送。相似地,数据也能从存储器拷贝到网络。
1.一个以太网段,包括电缆和集线器。
- 每根电缆都有相同的最大位带宽,集线器不加分辩地将一个端口上收到的每个位复制到其他所有的端口上。因此,每台主机都能看到每个位。
2.每个以太网适配器都有一个全球唯一的48位地址。
- 它存储在这个适配器的非易失性存储器上。每个主机适配器都能看到这个帧,但是只有目的主机实际读取它。
3.桥接以太网
- 它由电缆和网桥将多个以太网段连接起来,形成的较大的局域网。连接网桥的电缆传输速率可以不同(例:网桥与网桥之间1GB/S, 网桥与集线器之间100MB/S)。
4.网桥作用:连接不同网段。
- 同一网段内A向B传输数据时,帧到达网桥输入端口,网桥将其丢弃,不予转发。A向另一网段内C传输数据时,网桥才将帧拷贝到与相应网段连接的端口上。从而节省了网段的带宽
5.协议软件的基本能力:
- 命名机制 为每台主机至少分配一个互联网地址,从而消除不同主机地址格式的差异,这个地址唯一地标识了这台主机。
- 传送机制 不同格式的数据进行封装,使其具有相同的格式。
全球ip因特网
ip地址
- 一个IP地址就是一个32位无符号整数。网络程序将IP地址存放在下图所示的IP地址结构中。
因特网域名
- 1.因特网客户端和服务器互相通信时使用的是IP地址。为了方便记忆,因特网也定义了一组更加人性化的域名,以及一种将域名映射到IP地址的机制。域名是一串用句点分隔的单词(字母、数字和破折号)。
- 2.域名集合形成了一个层次结构,每个域名编码了它在这个层次中的位置。通过一个示例你将很容易理解这点。下展示了域名层次结构的一部分。层次结构可以表示为一棵树。树的节点表示城名,反向到根的路径形成了域名。子树称为子域。层次结构中的第一层是个未命名的根节点。下一层是一组一级域名由非赢利组织(因特网分酒名字数字协会)定义。常见的第一层域名包括com、edu、gov、org、net,这些域名是由ICANN的各个授权代理按照先到先服务的基础分配的的。一旦一个组织得到了一个二级域名,那么它就可以在这个子域中创建任何新的域名了。
因特网连接
- 因特网客户端和服务器通过在连接上发送和接收字节流来通信。从连接一对进程的意义上而言,连接是点对点的。从数据可以同时双向流动的角度来说,它是全双工的。并且从(除了一些如粗心的耕锄机操作员切断了电缆引起灾对性的失败以外)由源进程发出的字节流最终被目的进程以它发出的顺序收到它的角度来说,它也是可靠的。
web服务器
- Web客户端和服务器之间的交互用的是一个基于文本的应用级协议,叫做HTTP。
- HTTP是一个简单的协议。一个web客户端(即浏览器)打开一个到服务器的因特网连接。浏览器读取这些内容,并请求某些内容。服务器响应所请求的内容,然后关闭连接。浏览器读取并把它显示在屏幕内。
- 主要的区别是Web内容可以用HTML来编写。一个HTML程序(页)包含指令(标记)它们告诉浏览器如何显示这页中的各种文本和图形对象。
- Web服务器以两种不同的方式向客户端提供内容:
(1)取一个磁盘文件,并将它的内容返回给客户端。
(2)运行一个可执行文件,并将它的输出返回给客户端。
服务动态内容
- 1.客户端如何将程序参数传递给服务器
- 2.服务器如何将参数传递给子进程
- 3.服务器如何将其他信息传递给子进程
- 4.子进程将它的输出发送到哪里
第十二章 并发编程
三种基本的构造并发程序的方法:
进程
- 每个逻辑控制流是一个进程,由内核进行调度,进程有独立的虚拟地址空间
I/O多路复用
- 逻辑流被模型化为状态机,所有流共享同一个地址空间
线程
- 运行在单一进程上下文中的逻辑流,由内核进行调度,共享同一个虚拟地址空间
基于进程的并发编程
- 构造并发程序最简单的方法——用进程
- 构造并发服务器:在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。
- 注意:
(1)父进程需要关闭它的已连接描述符的拷贝(子进程也需要关闭)
(2)必须要包括一个SIGCHLD处理程序来回收僵死子进程的资源
(3)父子进程之间共享文件表,但是不共享用户地址空间,这个在以前的学习过程中提到过 - 关于独立地址空间
(1)优点:防止虚拟存储器被错误覆盖
(2)缺点:开销高,共享状态信息才需要IPC机制
基于I/O多路复用的并发编程
-
就是使用select函数要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。
-
select函数处理类型为fd_set的集合,即描述符集合,并在逻辑上描述为一个大小为n的位向量,每一位b[k]对应描述符k,但当且仅当b[k]=1,描述符k才表明是描述符集合的一个元素。
-
描述符能做的三件事:
(1)分配他们
(2)将一个此种类型的变量赋值给另一个变量
(3)用FD_ZERO、FD_SET、FD_CLR和FD_ISSET宏指令来修改和检查它们
基于I/O多路复用的并发事件驱动服务器
事件驱动程序:将逻辑流模型化为状态机。
状态机:
- 状态
- 输入事件
- 转移
整体的流程是:
select函数检测到输入事件
add_client函数创建新状态机
check_clients函数执行状态转移(在课本的例题中是回送输入行),并且完成时删除该状态机。
几个需要注意的函数:
init_pool:初始化客户端池
add_client:添加一个新的客户端到活动客户端池中
check_clients:回送来自每个准备好的已连接描述符的一个文本行
I/O多路复用技术的优劣
-
优点
(1)相较基于进程的设计,给了程序员更多的对程序程序的控制
(2)运行在单一进程上下文中,所以每个逻辑流都可以访问该进程的全部地址空间,共享数据容易实现
(3)可以使用GDB调试
(4)高效 -
缺点
(1)编码复杂
(2)不能充分利用多核处理器
基于线程的并发编程
线程执行模型
1.主线程
- 在每个进程开始生命周期时都是单一线程——主线程,与其他进程的区别仅有:它总是进程中第一个运行的线程。
2.对等线程
- 某时刻主线程创建,之后两个线程并发运行。
- 每个对等线程都能读写相同的共享数据。
3.主线程切换到对等线程的原因:
- 主线程执行一个慢速系统调用,如read或sleep
- 被系统的间隔计时器中断
4.线程和进程的区别
- 线程的上下文切换比进程快得多
- 组织形式:
- 进程:严格的父子层次
- 线程:一个进程相关线程组成对等(线程)池,和其他进程的线程独立开来。一个线程可以杀死它的任意对等线程,或者等待他的任意对等线程终止。
Posix线程
Posix线程是C程序中处理线程的一个标准接口。基本用法是:
- 线程的代码和本地数据被封装在一个线程例程中
- 每个线程例程都以一个通用指针为输入,并返回一个通用指针。
创建线程
1.创建线程:pthread_create函数
#include <pthread.h>
typedef void *(func)(void *);
int pthread_create(pthread_t *tid, pthread_attr_t *attr, func *f, void *arg);
- 成功返回0,出错返回非0
- 创建一个新的线程,带着一个输入变量arg,在新线程的上下文运行线程例程f。
- attr默认为NULL
- 参数tid中包含新创建线程的ID
2.查看线程ID——pthread_self函数
#include <pthread.h>
pthread_t pthread_self(void);
返回调用者的线程ID(TID)
终止线程
1.终止线程的几个方式:
- 隐式终止:顶层的线程例程返回
- 显示终止:调用pthread_exit函数
- 如果主线程调用,会先等待所有其他对等线程终止,再终止主线程和整个进程,返回值为pthread_return
- 某个对等线程调用Unix的exit函数,会终止进程与其相关线程
- 另一个对等线程通过以当前线程ID作为参数调用pthread_cancle来终止当前线程
2.pthread_exit函数
#include <pthread.h>
void pthread_exit(void *thread_return);
- 若成功返回0,出错为非0
3.pthread_cancle函数
#include <pthread.h>
void pthread_cancle(pthread_t tid);
- 若成功返回0,出错为非0
回收已终止线程的资源
- 用pthread_join函数:
#include <pthread.h>
int pthread_join(pthread_t tid,void **thrad_return);
- 这个函数会阻塞,知道线程tid终止,将线程例程返回的(void*)指针赋值为thread_return指向的位置,然后回收已终止线程占用的所有存储器资源
分离线程
1.可结合的线程
- 能够被其他线程收回其资源和杀死
- 被收回前,它的存储器资源没有被释放
- 每个可结合线程要么被其他线程显式的收回,要么通过调用pthread_detach函数被分离
2.分离的线程
- 不能被其他线程回收或杀死
- 存储器资源在它终止时由系统自动释放
3.pthread_detach函数
#include <pthread.h>
void pthread_detach(pthread_t tid);
- 若成功返回0,出错为非0
- 这个函数可以分离可结合线程tid。
- 线程能够通过以pthread_self()为参数的pthread_detach调用来分离他们自己。
- 每个对等线程都应该在他开始处理请求之前分离他自身,以使得系统能在它终止后回收它的存储器资源。
初始化线程:pthread_once函数
#include <pthread.h>
pthread_once_t once_control = PTHREAD_ONCE_INIT;
int pthread_once(pthread_once_t *once_control, void (*init_routine)(void));
- 总是返回0
多线程程序中的共享变量
线程存储器模型
- 每个线程都有自己独立的线程上下文,包括一个唯一的整数线程ID,栈、栈指针、程序计数器、通用目的寄存器和条件码。
- 寄存器是从不共享的,而虚拟存储器总是共享的。
- 各自独立的线程栈被保存在虚拟地址空间的栈区域中,并且通常是被相应的线程独立地访问的。
将变量映射到存储器
- 全局变量:定义在函数之外的变量
- 本地自动变量:定义在函数内部但是没有static属性的变量。
- 本地静态变量:定义在函数内部并有static属性的变量。
共享变量
- 一个变量V是共享的,当且仅当它的一个实例被一个以上的线程引用。例如,示例程序中的变量cnt就是共享的,因为它只有一个运行时实例,并且这个实例被两个对等线程引用在- 另一方面,myid不是共享的,因为它的两个实例中每一个都只被一个线程引用。然而,认识到像msgs这样的本地自动变量也能被共享是很重要的。
用信号量同步线程
- 共享变量的同时引入了同步错误,即没有办法预测操作系统是否为线程选择一个正确的顺序。
进度图
- 进度图是将n个并发线程的执行模型化为一条n维笛卡尔空间中的轨迹线,原点对应于没有任何线程完成一条指令的初始状态。
- 当n=2时,状态比较简单,是比较熟悉的二维坐标图,横纵坐标各代表一个线程,而转换被表示为有向边
转换规则:
- 合法的转换是向右或者向上,即某一个线程中的一条指令完成
- 两条指令不能在同一时刻完成,即不允许出现对角线
- 程序不能反向运行,即不能出现向下或向左
信号量
- P(s):如果s是非零的,那么P将s减一,并且立即返回。如果s为零,那么就挂起这个线程,直到s变为非零。
- V(s):将s加一,如果有任何线程阻塞在P操作等待s变为非零,那么V操作会重启线程中的一个,然后该线程将s减一,完成他的P操作。
- 信号量不变性:一个正确初始化了的信号量有一个负值。
- 信号量操作函数:
int sem_init(sem_t *sem,0,unsigned int value);//将信号量初始化为value
int sem_wait(sem_t *s);//P(s)
int sem_post(sem_t *s);//V(s)
使用信号量来实现互斥
- 信号量提供了一种很方便的方法来确保对共享变量的互斥访问。基本思想是将每个共享变量(或者一组相关的共享变量)与一个信号量联系起来 。以这种方式来保护共享变量的信号量叫做二元信号量,因为它的值总是0或者1。以提供互斥为目的的二元信号量常常也称为互斥锁。在一个互斥锁上执行P操作称为对互斥锁加锁。类似地,执行V操作称为对互斥锁解锁。对一个互斥锁加了锁但是还没有解锁的线程称为占用这个互斥锁。一个被用作一组可用资源的计数器的信号量称为计数信号量。关键思想是这种P和V操作的结合创建了一组状态,叫做禁止区。因为信号量的不变性,没有实际可行的轨迹线能够包含禁止区中的状态。而且,因为禁止区完全包括了不安全区,所以没有实际可行的轨迹线能够接触不安全区的任何部分。因此,每条实际可行的轨迹线都是安全的,而且不管运行时指令顺序是怎样的,程序都会正确地增加计数器的值。
利用信号量来调度共享资源
信号量有两个作用:
- 实现互斥
- 调度共享资源
综合:基于预线程化的并发服务器
- 在如图所示的并发服务器中,我们为每一个新客户端创建了一个新线程这种方法的缺点是我们为每一个新客户端创建一个新线程,导致不小的代价。一个基于预线程化的服务器试图通过使用如图所示的生产者-消费者模型来降低这种开销。服务器是由一个主线程和一组工作者线程构成的。主线程不断地接受来自客户端的连接请求,并将得到的连接描述符放在一个不限缓冲区中。每一个工作者线程反复地从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符。

使用线程提高并行性
- 到目前为止,在对并发的研究中,我们都假设并发线程是在单处许多现代机器具有多核处理器。并发程序通常在这样的机器上运理器系统上执行的。然而,在多个核上并行地调度这些并发线程,而不是在单个核顺序地调度,在像繁忙的Web服务器、数据库服务器和大型科学计算代码这样的应用中利用这种并行性是至关重要的。
其他并发问题
1.线程安全
定义四个(不相交的)线程不安全函数类:
- 不保护共享变量的函数。
- 保持跨越多个调用状态的函数。
- 返回指向静态变量指针的函数。
- 调用线程不安全函数的函数。
2.可重入性
- 当它们被多个线程调用时,不会引用任何共享数据。
(1)显式可重入的: - 所有函数参数都是传值传递,没有指针,并且所有的数据引用都是本地的自动栈变量,没有引用静态或全剧变量。
(2)隐式可重入的: - 调用线程小心的传递指向非共享数据的指针。
3.竞争
(1)竞争发生的原因:
- 一个程序的正确性依赖于一个线程要在另一个线程到达y点之前到达它的控制流中的x点。也就是说,程序员假定线程会按照某种特殊的轨迹穿过执行状态空间,忘了一条准则规定:线程化的程序必须对任何可行的轨迹线都正确工作。
(2)消除方法: - 动态的为每个整数ID分配一个独立的块,并且传递给线程例程一个指向这个块的指针
4.死锁
(1)一组线程被阻塞了,等待一个永远也不会为真的条件。
- 程序员使用P和V操作顺序不当,以至于两个信号量的禁止区域重叠。
- 重叠的禁止区域引起了一组称为死锁区域的状态。
- 死锁是一个相当难的问题,因为它是不可预测的。
(2)互斥锁加锁顺序规则:如果对于程序中每对互斥锁(s,t),给所有的锁分配一个全序,每个线程按照这个顺序来请求锁,并且按照逆序来释放,这个程序就是无死锁的。
(3)解决死锁的方法
a、不让死锁发生: - 静态策略:设计合适的资源分配算法,不让死锁发生---死锁预防;
- 动态策略:进程在申请资源时,系统审查是否会产生死锁,若会产生死锁则不分配---死锁避免。
b、让死锁发生:
- 进程申请资源时不进行限制,系统定期或者不定期检测是否有死锁发生,当检测到时解决死锁----死锁检测与解除。
遇到的问题和解决过程
一开始编译代码时按照之前的方法编译,报错。根据错误提示,发现pthread库不是linux系统默认的库,因此pthread_creat创建线程时,在编译中要加上-lpthread参数。修正后顺利编译。
实践
condvar.c
- 代码分析:
(1)这个代码演示的是生产者生产和消费者消费交替进行的过程。是线程间同步的一种情况。
(2)主函数中用srand(time(NULL))设置当前的时间值为种子,在后面的producer和consumer函数中调用rand()函数产生随机数。 - 运行结果:
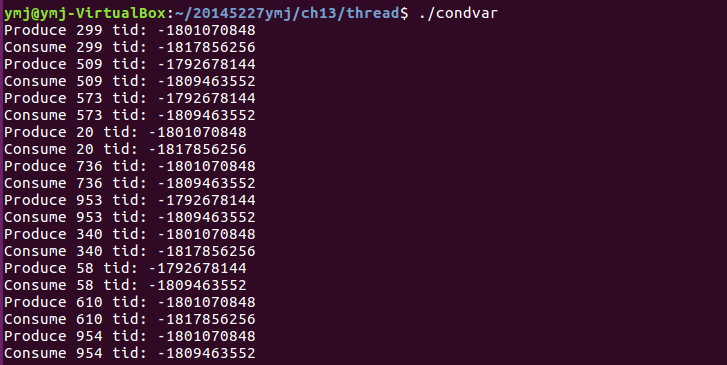
- 将主函数做如下修改后,发现生产和消费的速率比原来慢了一倍左右,因此也可以知道,通过增加或减少创建的线程数量能够影响程序输出的速率。这也侧面反应出了互斥锁在程序中所起的作用。
cp_t.c
- 代码分析:
(1)mmap函数
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
将一个文件或者其他对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。
成功执行时,mmap()返回被映射区的指针,munmap()返回0.失败时,mmap()返回MAP_FAILED,munmap返回-1.
(2)lseek函数
off_t lseek(int fd,off_t offset,int whence);
fd表示要操作的文件描述符,offset是相对于whence(基准)的偏移量,whence可以是SEEK_SET(文件指针开始),SEEK_CUR(文件指针当前位置),SEEK_END(文件指针尾)
lseek主要作用是移动文件读写指针,返回文件读写指针距文件开头的字节大小,若出错则返回-1. - 运行结果:

createthread.c
- 代码分析:
(1)程序主要演示了创建线程函数pthread_create()函数的使用,用来打印进程和线程的ID。
(2)主函数中先利用pthread_create()函数创建一个线程,接着调用printids函数(打印标识符的函数)打印主线程号,最后线程函数thr_fn中打印出新建的线程号。 - 运行结果:

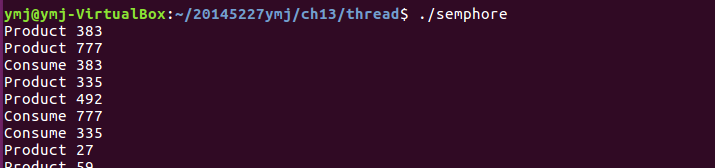
semphore.c
- 代码分析:
(1)sem_init函数
sem_init(sem_t *sem, int pshared, umsigned int value);
函数初始化一个定位在sem的匿名信号量;pshared参数为0指明信号量是由进程内线程共享,若为非0值则信号量在进程之间共享;value参数指定信号量的初始值。
(2)sem_init()成功时返回0;错误时返回-1,并把errno设置为合适的值。
(3)sem_destroy()函数用于销毁由sem指向的匿名信号量。只有通过sem_init()初始化的信号量才应该使用该函数销毁。函数成功时返回0,错误时返回-1,并把errno设置为合适的值。
(4)这个函数和之前的condvar.c一样都是展示生产者和消费者交替工作的过程。区别是本程序实现生产或消费的过程是利用sem_wait()和sem_post(),它们的作用分别是从信号量的值减去一个“1”和从信号量的值加上一个“1” - 运行结果:
hello_multi.c
- 代码分析:程序中的print_msg()函数中:在printf后的fflush(stdout);说明要立刻将要输出的内容输出,每输出一次停1秒,并循环5次。
- 运行结果:

- 若想要使程序输出像预期的打印出5个完整的helloworld,只需要将线程t1和t2的位置互换,修改代码如下:
- 修改后代码运行如下:

hello_multi1.c
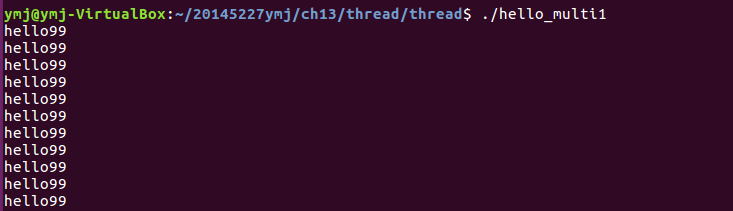
- 代码分析:运行结果只输出hello99
- 运行结果:
hello_single.c
- 代码分析:根据代码,先单独执行print_msg("hello");——输出5个hello,后输出5个带换行的world
- 运行结果:

incprint.c
-
代码分析:由于定义中NUM=5,所以输出的count为1——5
-
运行结果:

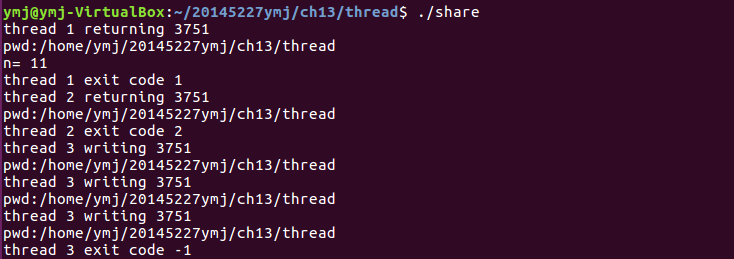
share.c
- 运行结果:
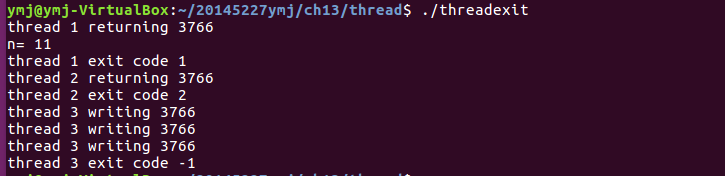
threadexit.c
- 运行结果:
countwithmutex.c
- 代码分析:
(1)代码中涉及到的函数:
- pthread_creat:创建线程,若成功则返回0,若失败则返回出错编号。第一个参数为指向线程标识符的指针,创建成功时指向的内存单元被设置为新创建线程的线程ID;第二个参数设置线程属性;第三个参数是线程运行函数的起始地址;最后一个参数是运行函数的参数
- pthread_join:用来等待一个线程的结束。当函数返回时,被等待线程的资源被收回。
- pthread_mutex_lock:线程调用该函数让互斥锁上锁。成功锁定时返回0,其他任何返回值都表示出现了错误。
- pthread_mutex_unlock:与pthread_mutex_lock成对存在。释放互斥锁。
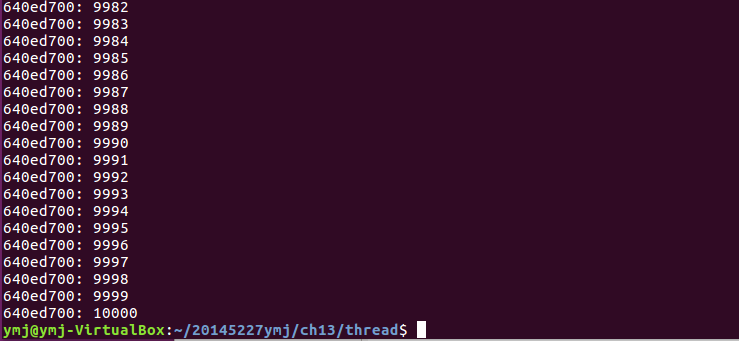
(2)程序首先定义了一个宏PTHREAD_MUTEX_INITIALIZER来静态初始化互斥锁。先创建tidA线程后运行doit函数,利用互斥锁锁定资源,进行计数,执行完毕后解锁。后创建tidB,与tidA交替执行。由于定义的NLOOP值为5000,所以程序最后的输出值为10000.程序的最后还需要分别回收tidA和tidB的资源。
- 运行结果:
count.c
- 代码分析:这个代码用于与countwithmutex.c进行对比,差别在于本代码doit函数的for循环中没有引入互斥锁,只进行了单纯的计数,创建两个线程共享同一变量都实现加一操作。
- 运行结果
本周代码托管链接
https://git.oschina.net/20145227/IS-Design-20145227/tree/master/ch13
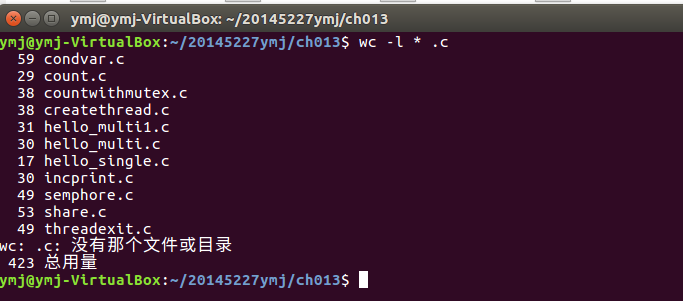
本周代码总数
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0 | 2/2 | 20/20 | |
| 第二周 | 100/100 | 1/3 | 20/40 | |
| 第三周 | 200/300 | 1/4 | 22/62 | |
| 第五周 | 200/500 | 1/5 | 22/84 | |
| 第六周 | 274/774 | 1/6 | 22/106 | |
| 第七周 | 127/901 | 2/8 | 22/128 | |
| 第八周 | 50/951 | 2/10 | 22/150 | |
| 第九周 | 418/1369 | 2/12 | 22/172 | |
| 第十周 | 485/1854 | 2/14 | 22/194 | |
| 第十一周 | 628/2482 | 3/17 | 32/226 | |
| 第十二周 | 68/2550 | 2/19 | 32/258 | |
| 第十三周 | 423/2973 | 2/21 | 32/290 |