时间:2021/01/23
一.深度学习概论
1.1你将学到什么

1.2什么是神经网络
下图是一个根据房屋的面积预测房屋价格的函数,通过拟合得到的,它同时也可以看作是最简单的神经网络,只有一个隐藏神经节点的神经网络,该隐藏神经节点完成了这个函数的功能

当然,房屋的价格可能收到很多因素的影响,就像下图显示的这样,此时表示输入与输出之间关系的函数便不再是简单的线性函数。对于神经网络而言,当你构建出整个神经网络的结构时,你只要给他足够多的(x,y),他就能无限接近输入与输出之间的函数关系。
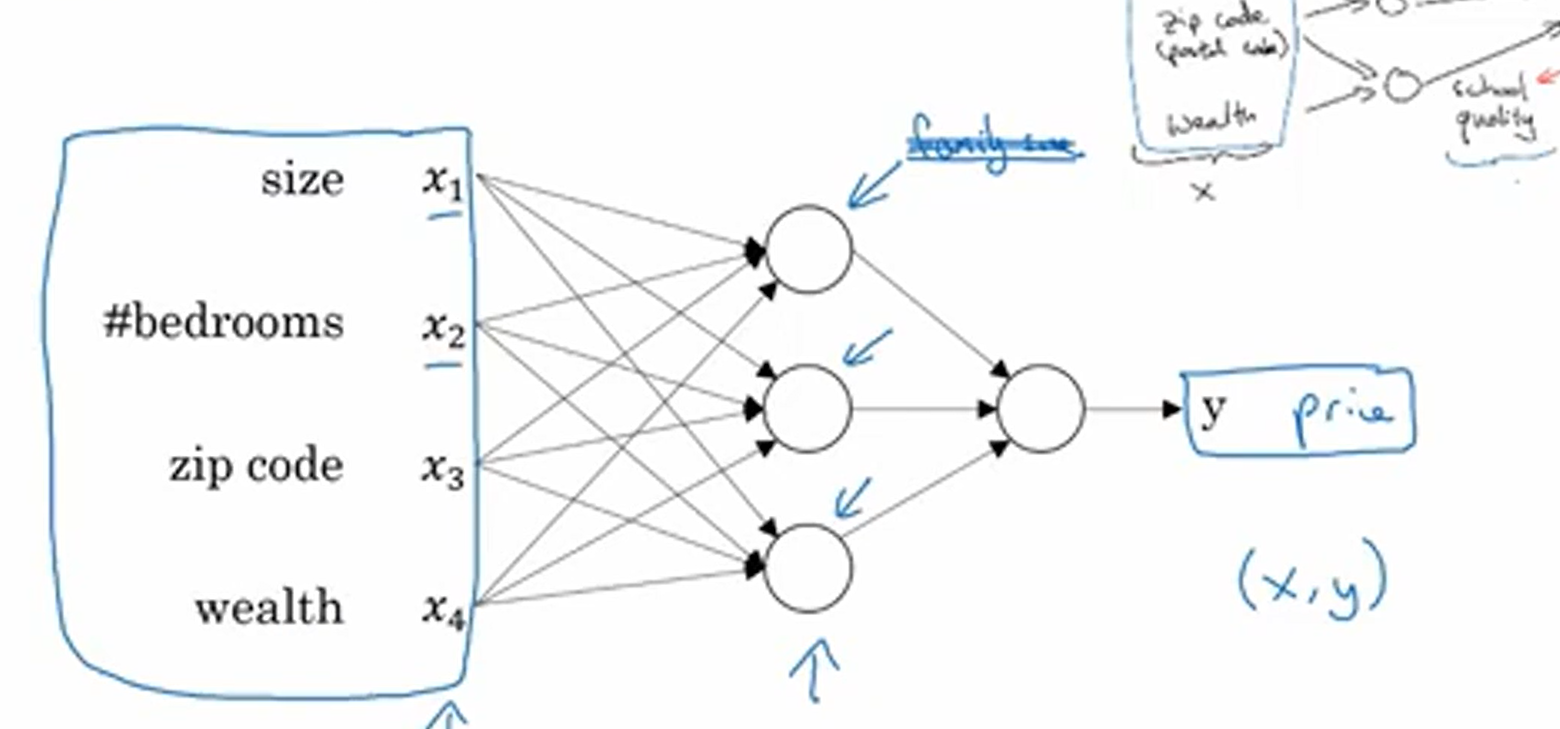
1.3监督学习与非监督学习
个人理解,监督学习指的是在训练模型时给出的数据带有标签,即在训练模型的过程中,不仅给出输入值,还要给出输出值。而非监督学习是只给输入值,让计算机自己学习怎么做 。
1.4为什么深度学习会兴起
由于传统机器学习的方式无法处理大量数据,直到深度学习出现,大型的神经网络成为可能,并且由于大量数据的获得使得深度学习兴起。
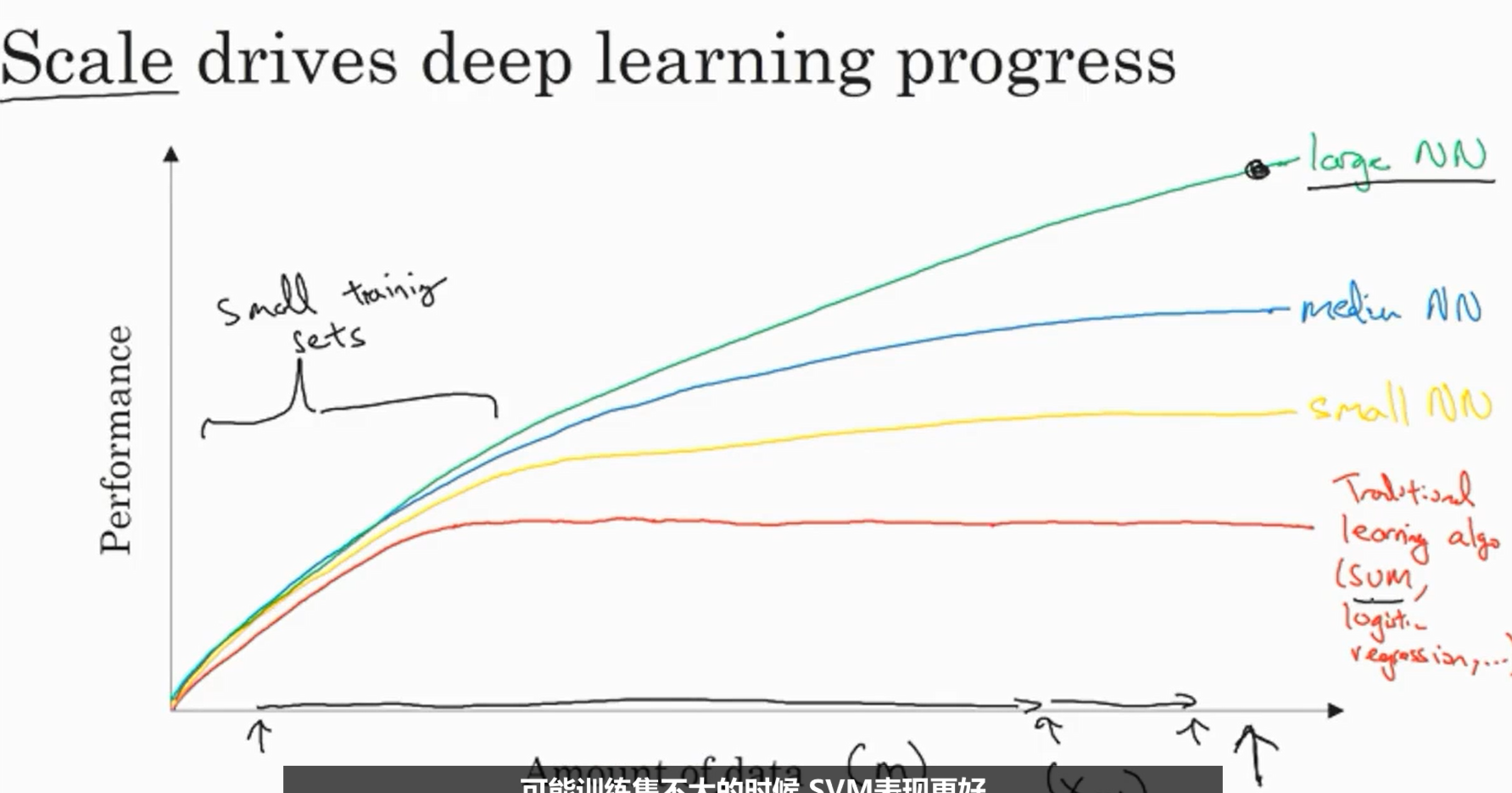
数据的规模、硬件和算法对于深度学习至关重要

1.5关于这门课

二.神经网络基础
2.1二分分类
二分分类是一种逻辑回归,即对于给定的输入,它的输出只有两种结果。
对于给定的图片,它是由红绿蓝三个矩阵表示的,也可以将三个矩阵合并成一个列向量,如下图
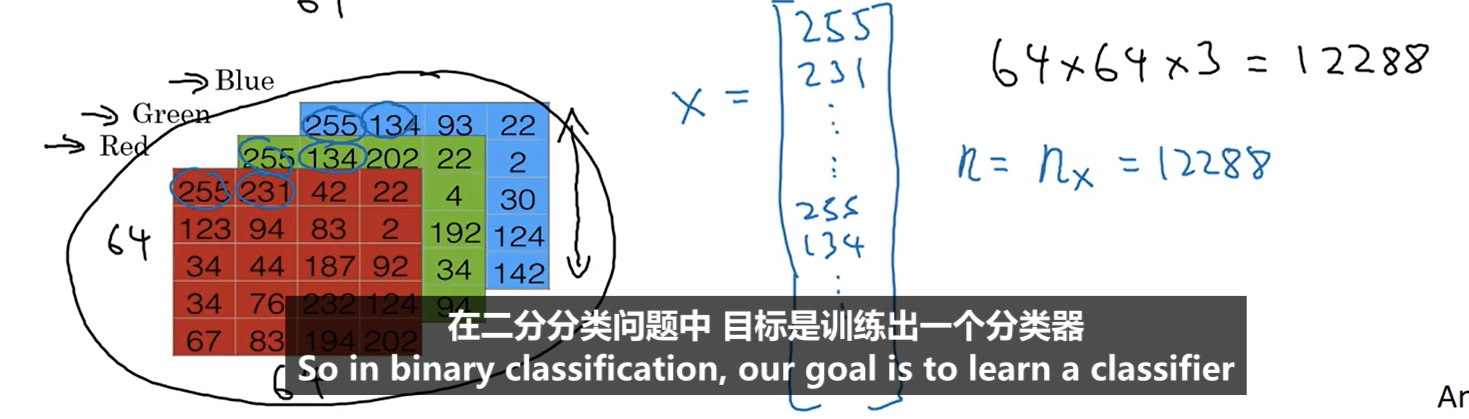
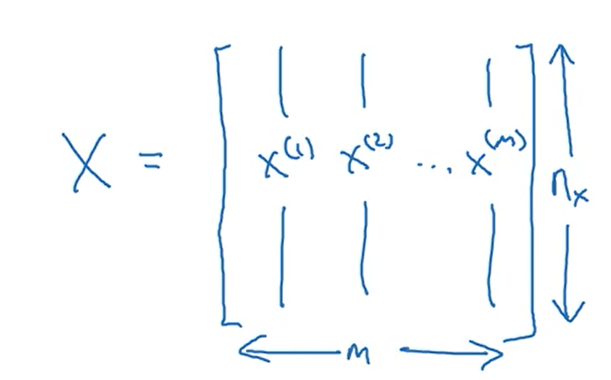
矩阵X是由所有输入列向量构成的矩阵,矩阵Y是由所有输出值组成的向量
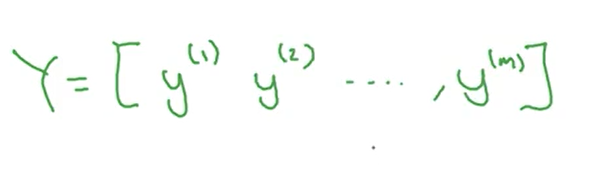
2.2Logistic回归
logistic回归属于2.1中所说的二分分类,通过设置参数w和b构造神经网络,对于给定输入x,该神经网络会输出y=1的概率,由于概率必须是0~1之间的数值,若以通过Sigmoid激活函数来限制输出的取值范围

2.3Logistic回归损失函数
下图给出了y的预测值的计算公式
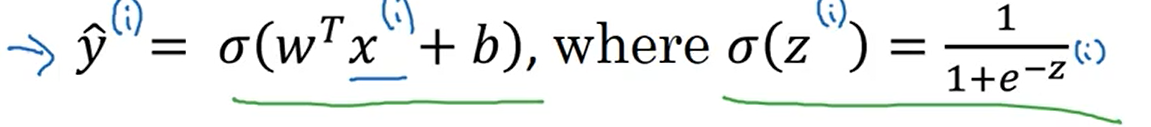
我们的目的是使由神经网络计算出的预测值与训练集标签上的值相等(约等于) 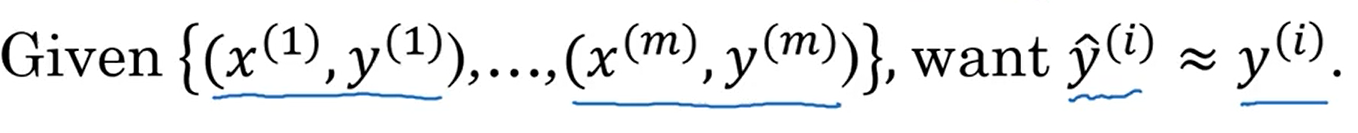
logistic回归的损失函数:(通过极大似然函数求导获得)

logisitic回归的成本函数:
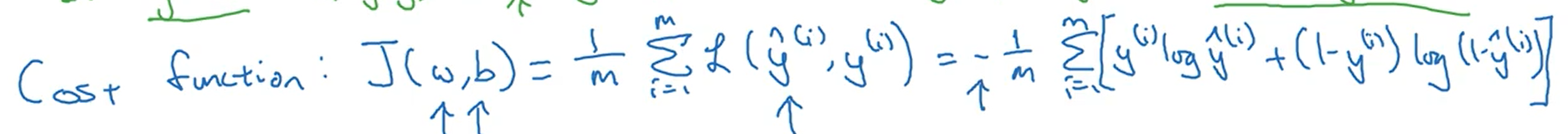
损失函数与成本函数的区别:
损失函数是对于单个样本而言,用来衡量预测值与真实值之间的差距;成本函数对于样本总体而言,是所有样本损失函数之和。
2.4梯度下降法
在求解logistic回归中的参数w和b时,我们使用的是梯度下降法。对于梯度下降法,我们要重复计算神经网络的成本函数,并且使用第二张图的公式对参数进行更新。
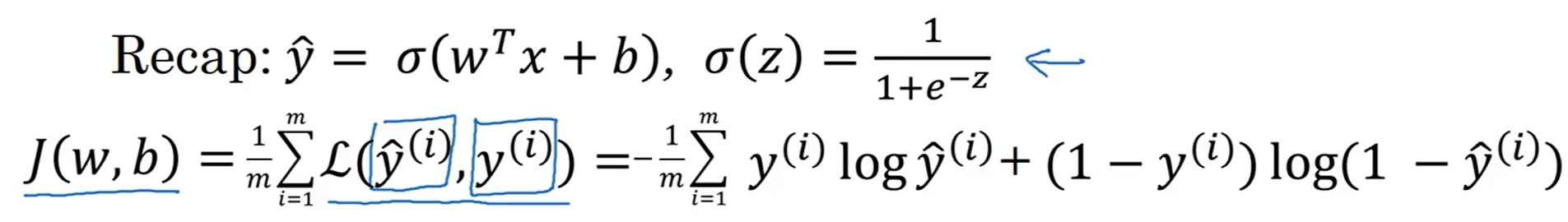
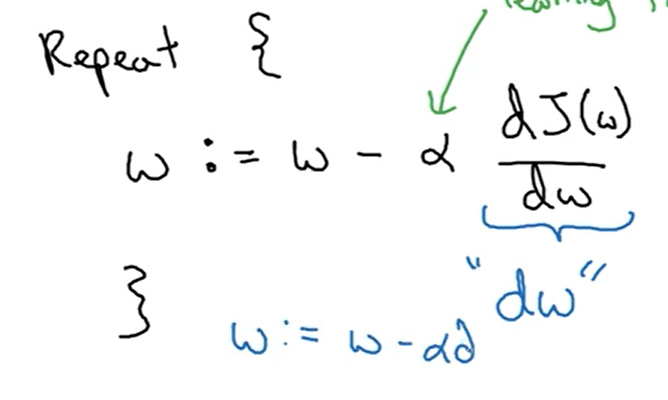
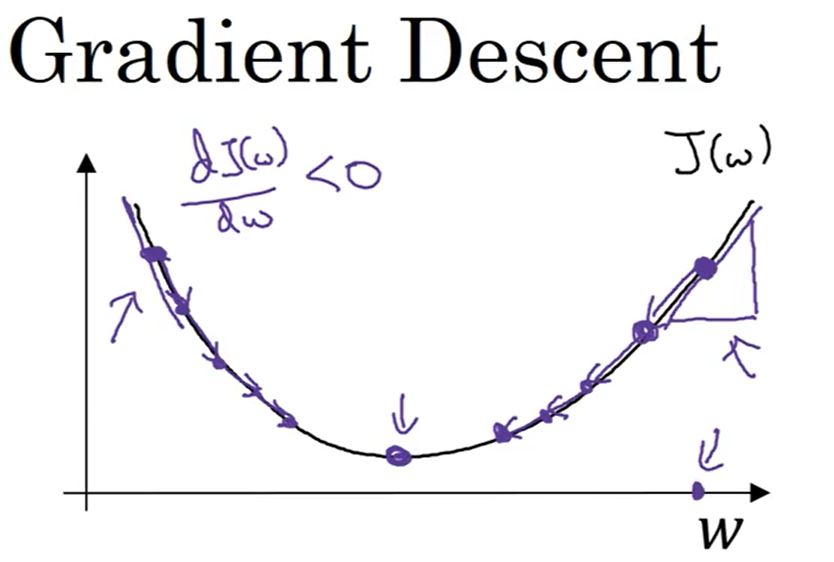
所谓的梯度下降法,就是使函数沿着导数最大的方向降低,进而使成本函数达到最小值,此时的参数基本上为最优的,成本函数达到最低意味着预测值与真实值之间的差距最小,即神经网络最优。
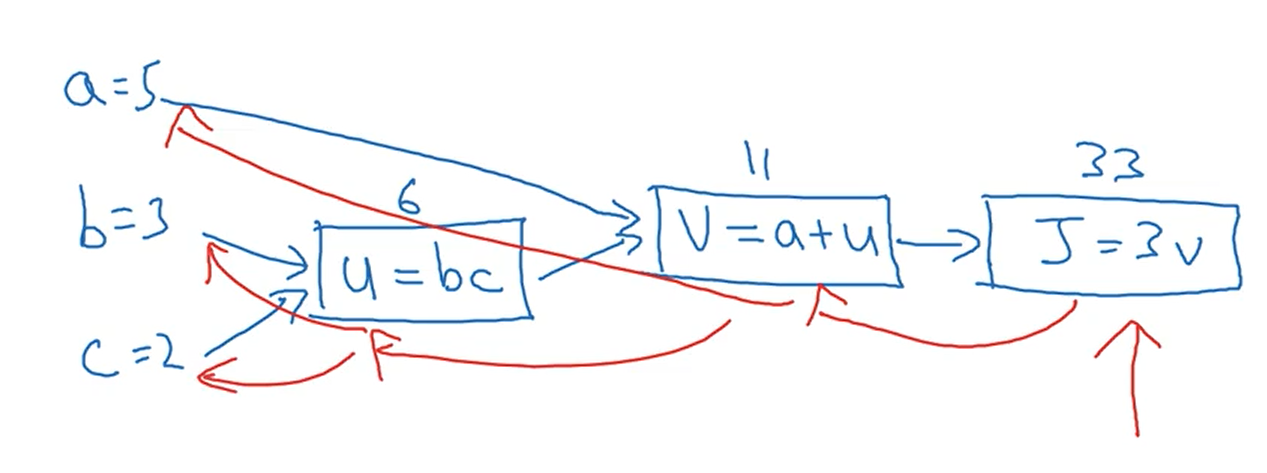
2.5计算图
下图中蓝线是正向传播,即通过输入计算预测值的过程,红线是反向传播,即通过求导使用梯度下降法优化参数的过程。
2.6Logistic回归中的梯度下降法
如下图,通过蓝框中公式计算出相应的导数值,然后通过黄框中的公式对参数进行调整,以上过程就是logistic回归中的梯度下降法。(以上过程对于一个样本而言)

这里要注意单个样本的损失函数与样本整体的成本函数在梯度下降中的区别,一个是对损失函数求导,另一个是对成本函数求导。
2.7m个样本的梯度下降
下图中存在两个循换,其中外层循换是对m个样本进行循换,内层循换则是对n个特征值进行循环,dwi之所以要除以m,是因为前面求的是m个dwi的和。最后是要对参数进行更新。

2.7向量化Logistic回归
使用下图蓝框中的两个公式就可以计算出m个样本正向传播的结果,而不用显式的使用for循换(正向传播的向量化)

2.8向量化logistic回归的梯度输出
下图是对于反向传播的向量化,以蓝色竖线为界,左侧是未向量化的运算过程,右侧是使用向量化的运算过程。

2.9Python中的广播
Python中的广播相当于对于数组维数的隐式匹配,不需要进行显式的声明。下图是关于广播的几个例子

这是关于广播的几个规则:当一个(m,n)的矩阵加减乘除一个(1,n)的矩阵时,(1,n)的矩阵复制m份,变成一个(m,n)的矩阵;同理,当一个(m,n)的矩阵加减乘除一个(m,1)的矩阵时,(m,1)的矩阵复制n份,变成一个(m,n)的矩阵。即维数小的矩阵向维数大的矩阵变化。常数看成(1,1)的矩阵。
2.10关于python_numpy向量的声明
这一节主要是讲解如何避免编程时向量维数带来的问题。下图绿框中代码书写方式是不建议的,因为他会产生一个秩为1的矩阵,并不是传统意义上的行向量或者列向量,在使用的过程中会产生难以预测的行为,所以要尽量避免这样创建向量。下面两个紫框中是推荐使用的代码书写方式,其中第一个紫框是声明一个行向量和列向量;第二个紫框使用了asset()声明,用来确保向量的维数与自己想要的是一致的。

2.11Logistic损失函数的解释
下图中之所以可以取log,是因为log函数单调递增,对于函数的单调性以及最值的取值没有影响。

2.12第二周作业
参考博文:https://hekuan.blog.csdn.net/article/details/79639509,下面是我在参考上面文章中的内容写出来的,用到了链接中数据集以及解析数据集的函数
import lr_utils as lu import numpy as np #获取数据集中的数据 train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = lu.load_dataset() #print(train_set_x_orig) #降低数组的维数,将一个图片的数据变成一个列向量 train_set_x_reduce = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T test_set_x_reduce = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T #对数据进行归一化 train_set_x = train_set_x_reduce / 255 test_set_x = test_set_x_reduce / 255 #定义sigmod函数 def sigmod(z): s = 1 / (1 + np.exp(-z)) return s #训练模型 #初始化模型参数 w = np.zeros((train_set_x.shape[0], 1)) b = 0 count = 2000 learning_rate = 0.01 #实现正向传播的函数 def forward_propagating(x, w, b): z = np.dot(w.T, x) + b a = sigmod(z) return a #反向传播中计算导数值的函数 def back_propagating(a, x, y, m): cost = (- 1 / m) * np.sum(y * np.log(a) + (1 - y) * (np.log(1 - a))) #计算成本 dz = a - y dw = np.dot(x, dz.T)/m db = np.sum(dz)/m return dw, db, cost #实现训练模型的函数 def train_model(count, learning_rate, w, b): #使用元组来存放成本函数值 costs = [] #对模型参数进行优化 for i in range(count): a = forward_propagating(train_set_x, w, b) dw, db, cost = back_propagating(a, train_set_x, train_set_y_orig, train_set_x.shape[0]) w = w - learning_rate*dw b = b - learning_rate*db #向元组中添加成本值 if i % 100 == 0: costs.append(cost) return w, b, costs #使用训练好的模型进行测试 def test_model(w, b): w, b, costs = train_model(count, learning_rate, w, b) train_y = forward_propagating(train_set_x, w, b) test_y = forward_propagating(test_set_x, w, b) print("训练集准确性:", format(100 - np.mean(np.abs(train_y - train_set_y_orig)) * 100), "%") print("测试集准确性:", format(100 - np.mean(np.abs(test_y - test_set_y_orig)) * 100), "%") test_model(w, b);
具体思路:
首先要将数据集以及解析数据集的函数放到自己项目的路径下,然后是读取数据集并对数据集进行降维和归一化处理,之所以要降维,是因为之前的数据集是四维的,我们需要一个二维的矩阵进行计算,之后是定义正向传播和反向传播的函数,然后使用训练集对模型进行训练,在训练的过程中要定义迭代的次数,最后就是用测试集的数据进行测试,也就是先使用训练好的模型进行预测,然后看有多少图像时预测准确的,由此可以得出准确性。
三.浅层神经网络
3.1神经网络概览
将多个sigmod叠加起来就是一个神经网络,如下图:

3.2神经网络表示
下图是一个双层神经网络,有一个输入层,一个隐藏层和一个输出层组成。一般意义上输入层被称为第零层,不算一个标准层。其中隐藏层和输出层都含有参数。
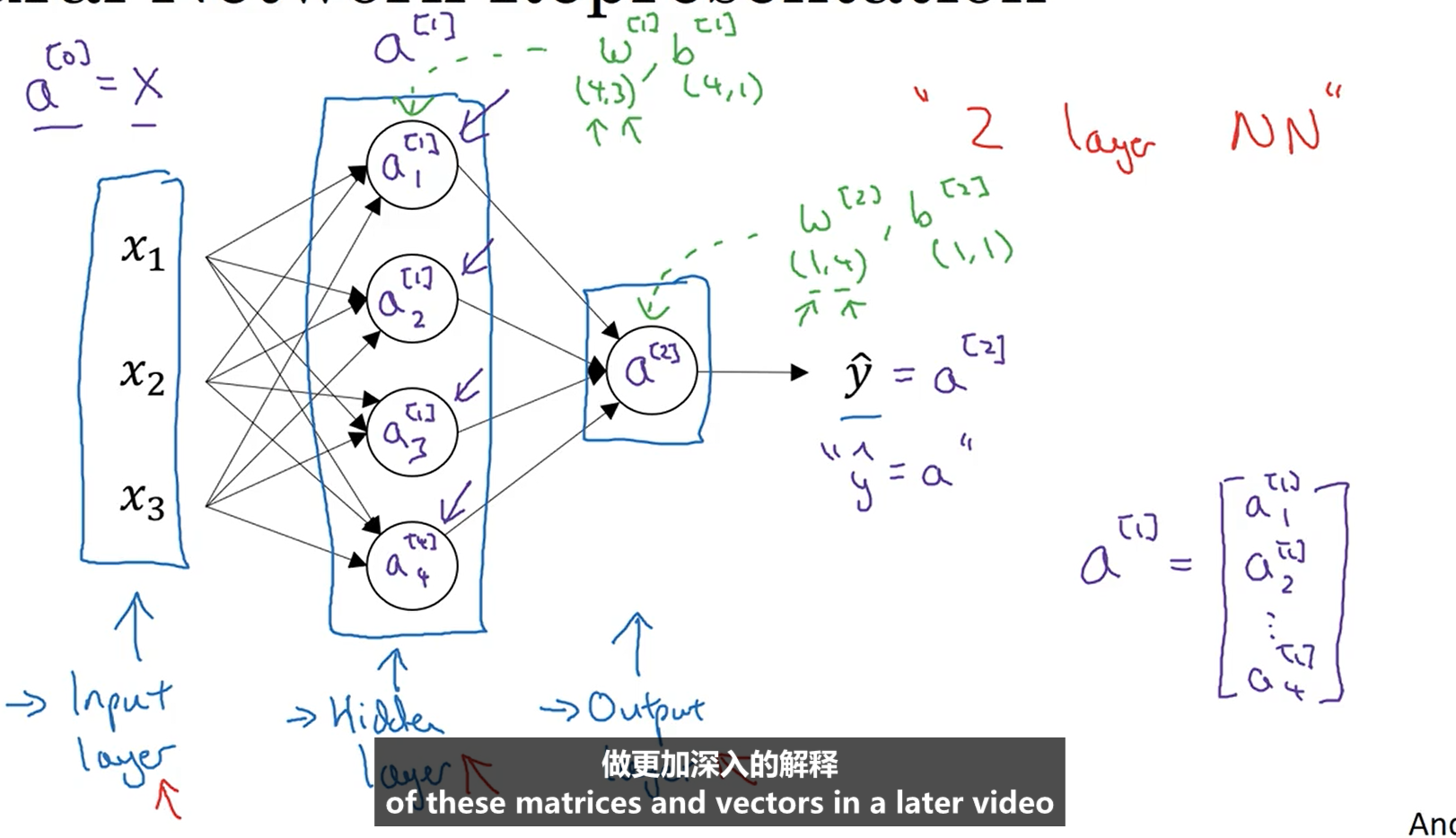
3.3计算神经网络的输出
对于上一节给出的两层神经网络,每一个神经节点的计算都像logistic回归一样。如下:
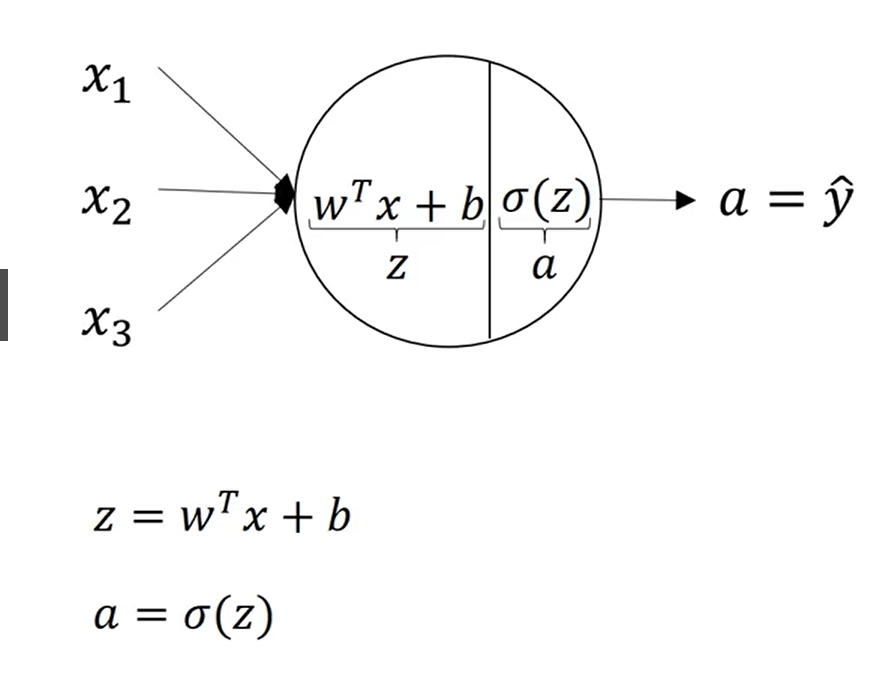
下图是进行向量化的一个推导过程:
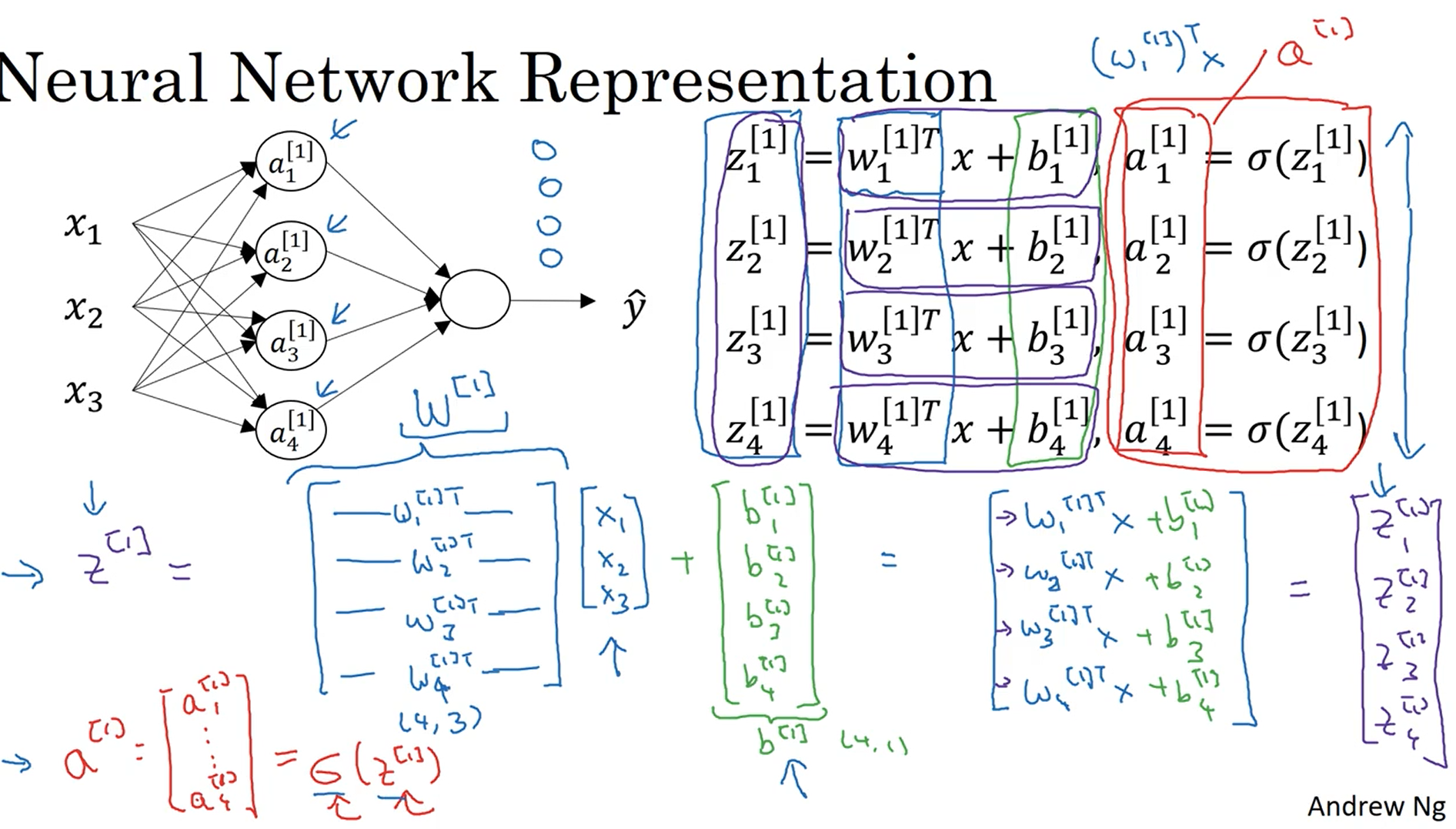
下图是向量化最后的表达式:
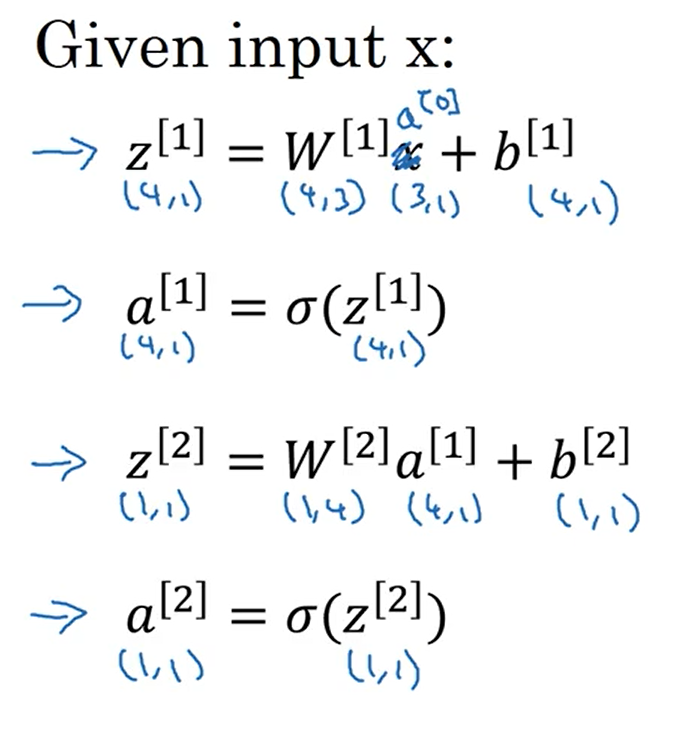
3.4多个例子中的向量化
这是未向量化时使用循换进行计算
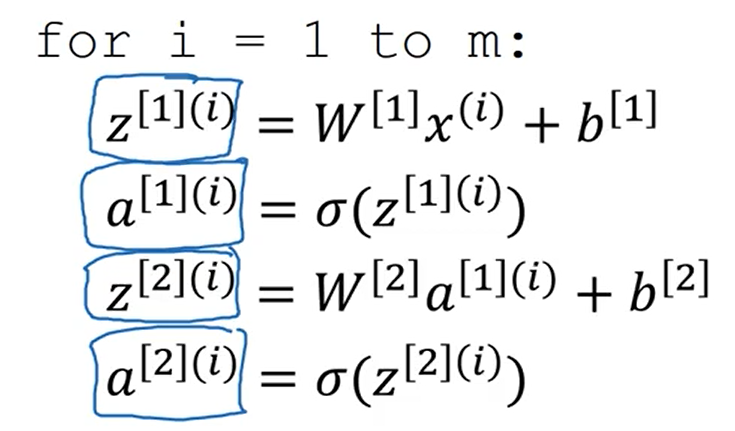
这是向量化后使用矩阵进行计算
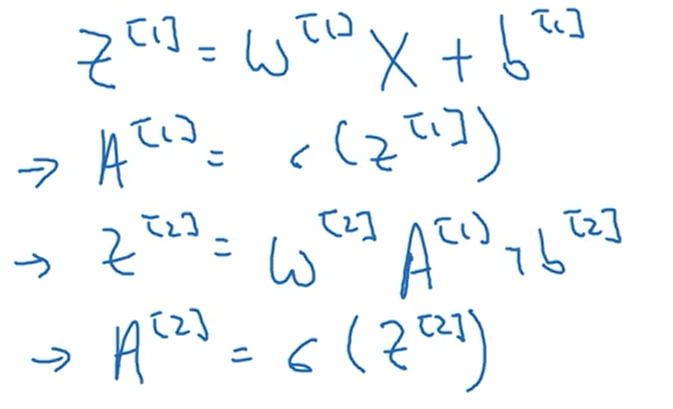
3.5向量化实现的解释
下图是在假设b为0的情况下向量化的推导过程,要注意w是一个矩阵而不是一个列向量。
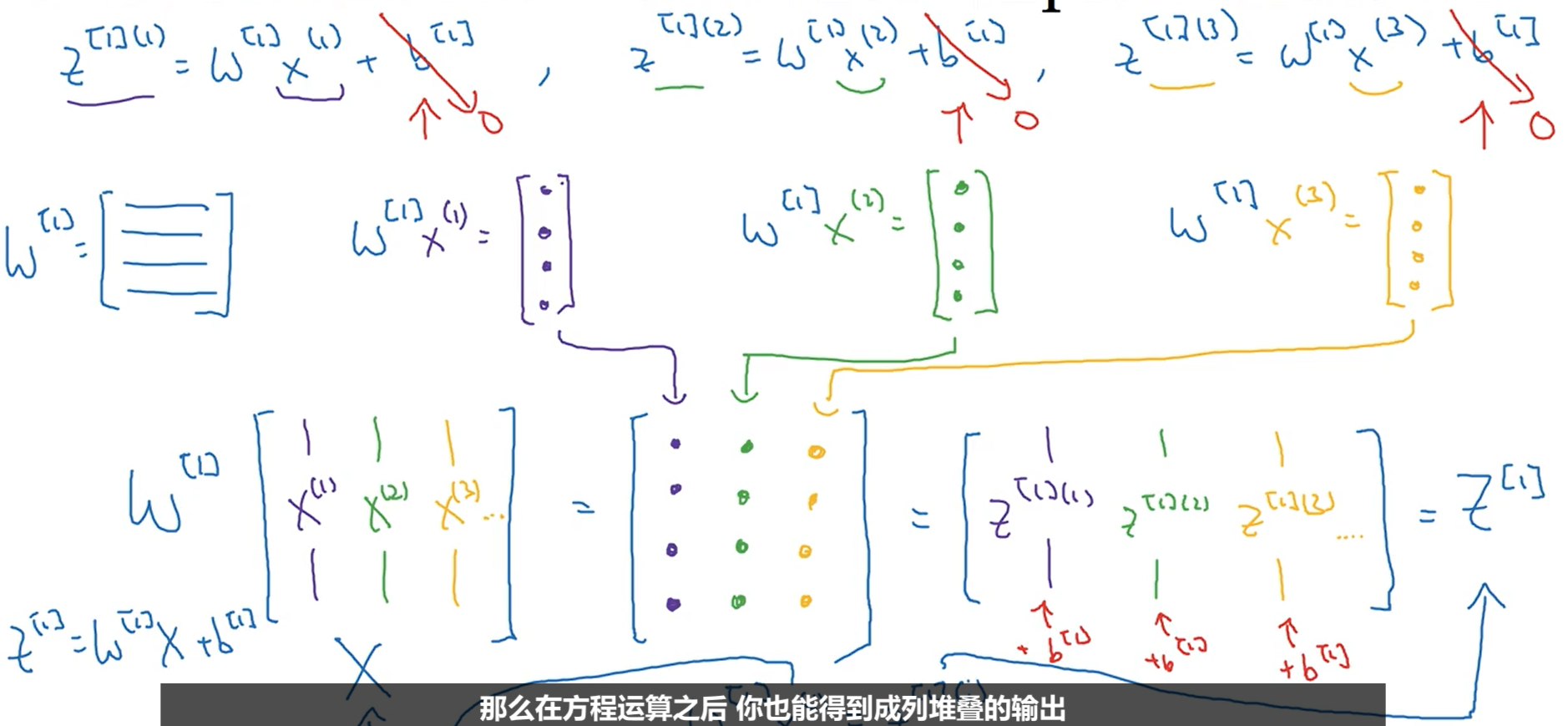
3.6激活函数
在之前的例子中我们通常会使用sigmoid函数作为激活函数,如下图:

但通常tanh函数的效果比sigmoid函数要好,除了进行二分类以及神经网络的输出结点,因为最后的预测范围在0到1之间,所以使用sigmoid函数更好。

sigmoid函数和tanh函数都有一个缺陷,即当z的值很大或很小的时候,函数的梯度值(或者称为斜率)接近0,这样会拖慢梯度下降算法。
最经常使用的激活函数是修正线性单元ReLU,如果不确定隐藏层使用哪个激活函数,一般使用ReLU
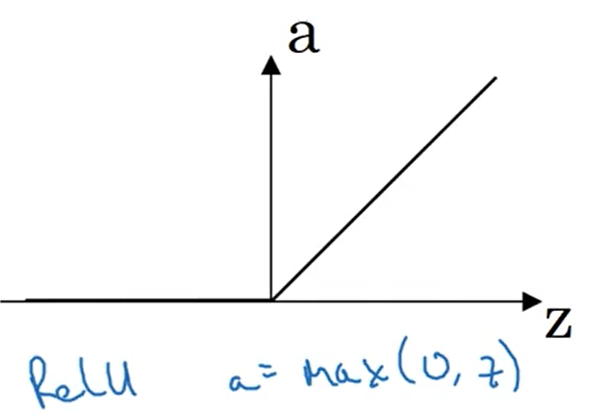
当z<0时,激活函数的斜率为0,但在实践中有足够多的隐藏单元令z>0,所以对于大多数训练样本来说还是很快的
下图是带泄露的ReLU函数
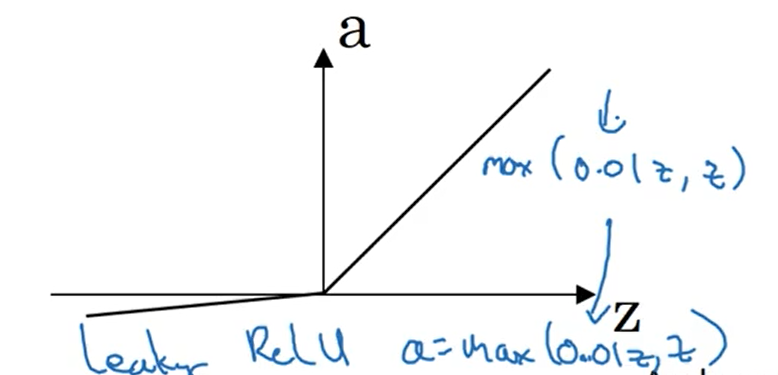
3.7为什么需要非线性激活函数
除了在一些回归问题或者神经网络的输出层上,线性激活函数是不会被使用的,因为它对于整个模型并无帮助,隐藏层中的线性激活函数不会增加模型复杂的。
3.8激活函数的导数
sigmoid函数的导数
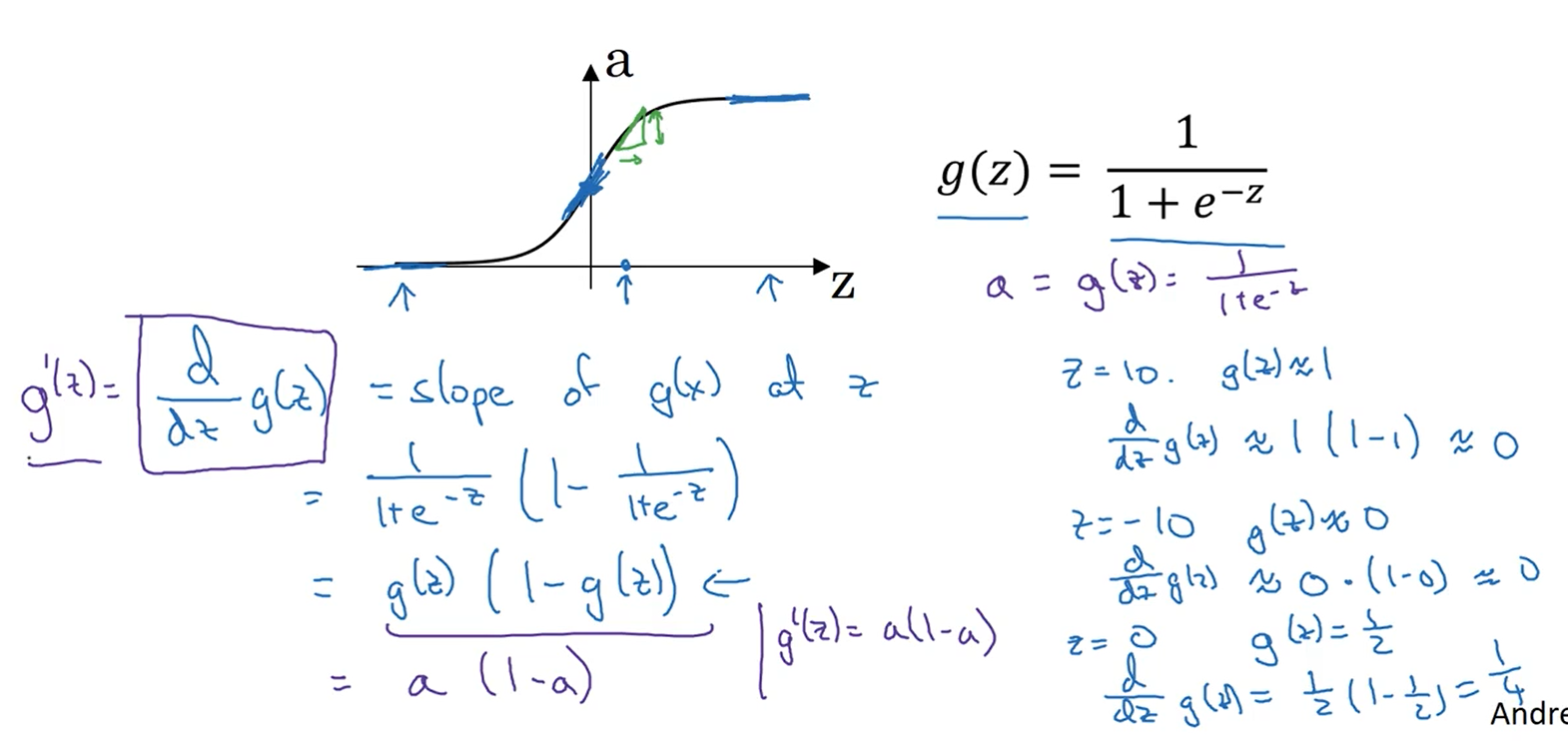
tanh函数的导数

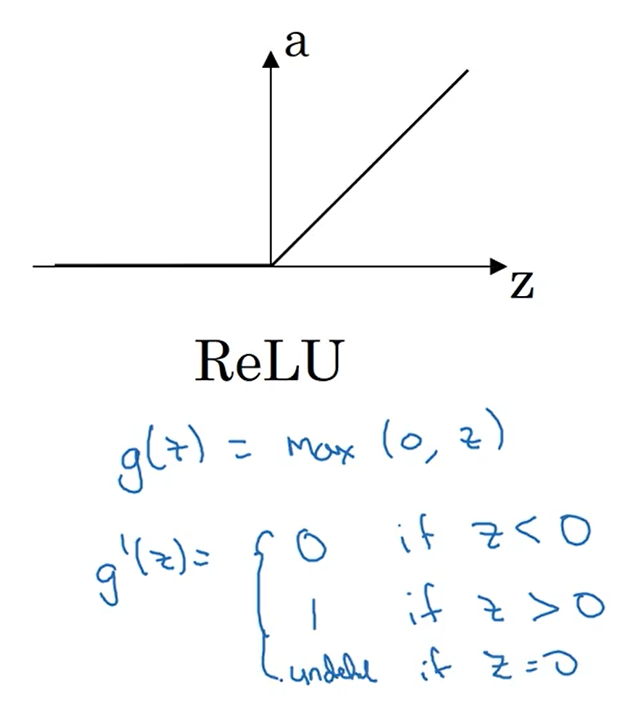
ReLU函数的导数,z=0时导数值也可以定义为1
Leaky ReLU函数的导数
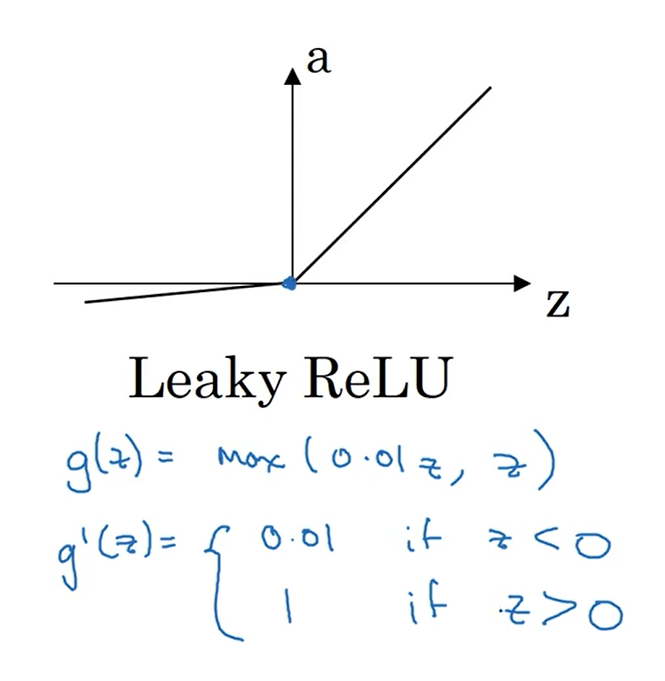
3.9神经网络的梯度下降法
下图是向前传播的四个公式
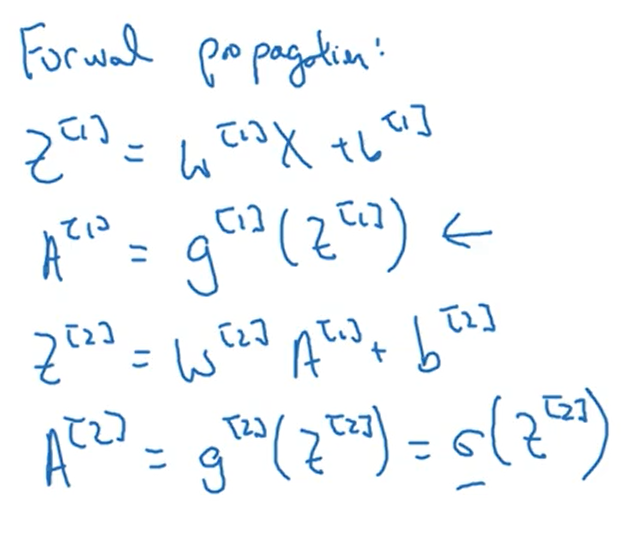
下图是向下传播的六个公式

3.10直观理解反向传播
下图是一个样本反向传播时导数的表达式(下式中导数的计算结果默认激活函数使用的是sigmoid函数)
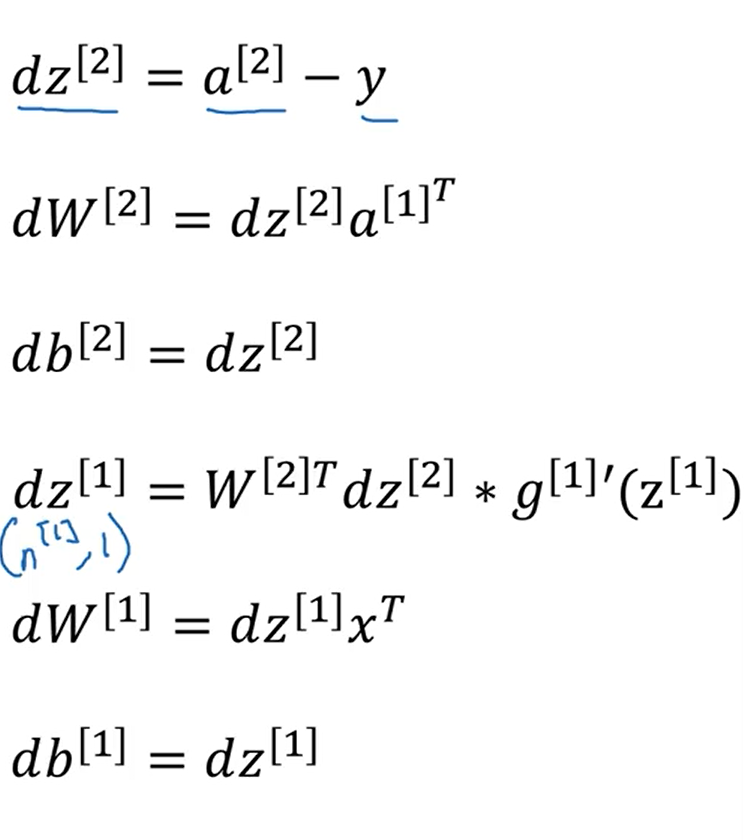
下图是m个样本反向传播时导数的表达式,也就是向量化之后的结果

在进行相关推导时一定要注意矩阵相乘时行列是否匹配

最后,在初始化神经网络权重时,不要全零,要随机初始化(第二周的Logistic回归的权重可以全零)
3.11随机初始化
对于下图中的神经网络,如果我们将参数都初始化为0,则隐藏层中两个神经单元做的是完全相同的计算,这就导致每次迭代后w的第一行和第二行是完全相同的,在这种情况下,多个隐藏单元没有意义,因为他们计算的都是相同的东西
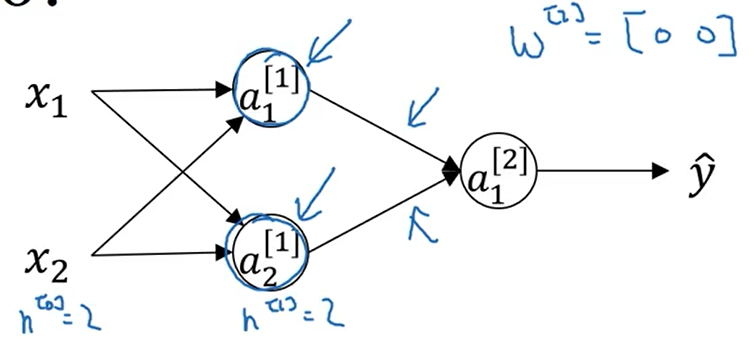
正确的初始化方法是如下图的随机初始化
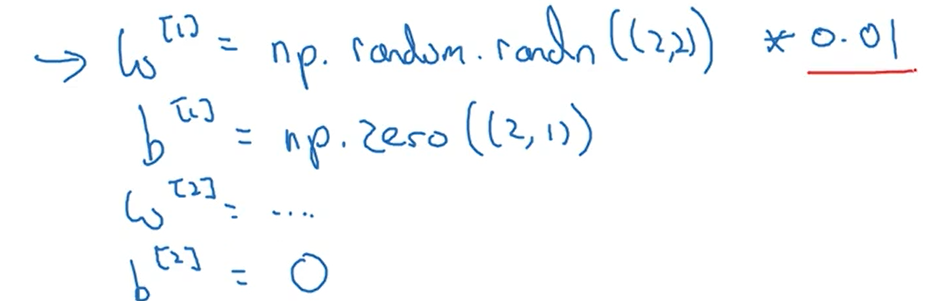
上图红线处之所以乘以0.01,是因为如果激活函数使用的是sigmoid或者tanh,当参数过大时,计算出来的预测值也很大,导致反向传播使用梯度下降时会很慢,因为导数趋于0,所以参数值一般要小一些,所以乘以0.01,但这个也不是规定,在创建深度神经网络时,为了使网络收敛的更快,可以尝试乘以不同的常数值。
3.12第三周作业
参考博文:https://blog.csdn.net/u013733326/article/details/79702148,这篇博文讲解的非常详细,推荐参考
创建一个如下图的两层神经网络进行二分类
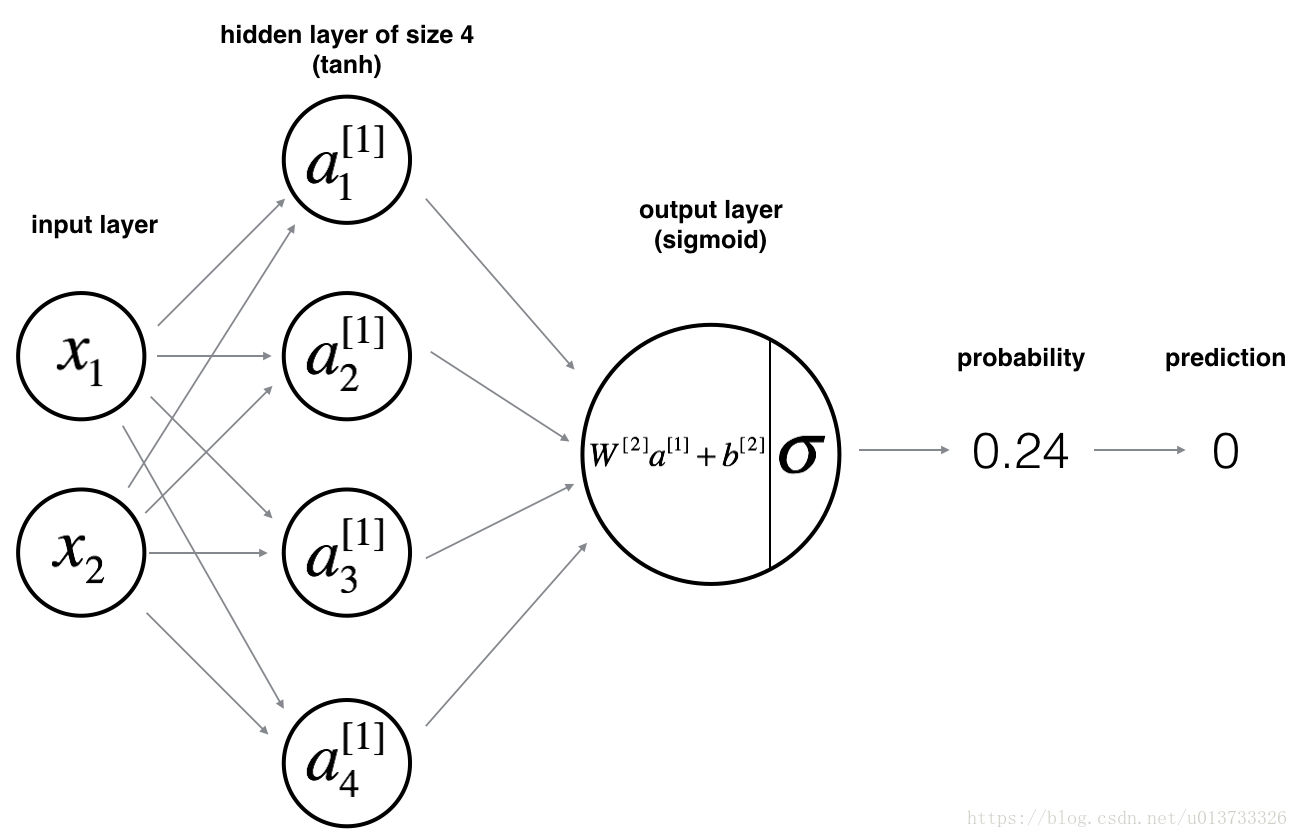
加载数据集的方法:
import matplotlib.pyplot as plt import numpy as np import sklearn import sklearn.datasets import sklearn.linear_model def plot_decision_boundary(model, X, y): # Set min and max values and give it some padding x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1 y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1 h = 0.01 # Generate a grid of points with distance h between them xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Predict the function value for the whole grid Z = model(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plot the contour and training examples plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.ylabel('x2') plt.xlabel('x1') plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral) def sigmoid(x): s = 1/(1+np.exp(-x)) return s def load_planar_dataset(): np.random.seed(1) m = 400 # number of examples N = int(m/2) # number of points per class D = 2 # dimensionality X = np.zeros((m,D)) # data matrix where each row is a single example Y = np.zeros((m,1), dtype='uint8') # labels vector (0 for red, 1 for blue) a = 4 # maximum ray of the flower for j in range(2): ix = range(N*j,N*(j+1)) t = np.linspace(j*3.12,(j+1)*3.12,N) + np.random.randn(N)*0.2 # theta r = a*np.sin(4*t) + np.random.randn(N)*0.2 # radius X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] Y[ix] = j X = X.T Y = Y.T return X, Y def load_extra_datasets(): N = 200 noisy_circles = sklearn.datasets.make_circles(n_samples=N, factor=.5, noise=.3) noisy_moons = sklearn.datasets.make_moons(n_samples=N, noise=.2) blobs = sklearn.datasets.make_blobs(n_samples=N, random_state=5, n_features=2, centers=6) gaussian_quantiles = sklearn.datasets.make_gaussian_quantiles(mean=None, cov=0.5, n_samples=N, n_features=2, n_classes=2, shuffle=True, random_state=None) no_structure = np.random.rand(N, 2), np.random.rand(N, 2) return noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure
创建神经网络的代码:
import numpy as np import planar_utils as pu # print("数组的长度: " + str(l)) # print("X的维度: " + str(shape_X)) # print("Y的维度: " + str(shape_Y)) def sigmoid(z): """ 参数: z-任何大小的标量或numpy数组。 返回: s-sigmoid(z) """ s = 1 / (1 + np.exp(-z)) return s # 对神经网络中的参数进行随机初始化 def initialization(n): """ 参数: n-神经网络每层的节点数 返回: 由参数值构成的字典 """ np.random.seed(2) #设置一个随机数种子以便结果统一 W1 = np.random.randn(n[1], n[0]) * 0.01 b1 = np.zeros((n[1], 1)) W2 = np.random.randn(n[2], n[1]) * 0.01 b2 = np.zeros((n[2], 1)) parameters = { "W1": W1, "b1": b1, "W2": W2, "b2": b2 } return parameters # parameters = initialization() # print(parameters["W1"]) # 定义实现前向传播的函数 def forward_propagation(X, parameters): """ 参数: X-神经网络的输入值 parameters-神经网络的参数值 返回: cache-缓存正向传播的结果 """ W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] Z1 = np.dot(W1, X) + b1 A1 = np.tanh(Z1) Z2 = np.dot(W2, A1) + b2 A2 = sigmoid(Z2) cache = { "Z1": Z1, "A1": A1, "Z2": Z2, "A2": A2 } return cache # 计算成本函数值 def count_cost(cache, Y, m): """ 参数: cache-缓存的成本函数值 Y-样本的输出值 m-输入样本值的数量 返回: cost-成本函数值 """ A2 = cache["A2"] logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2)) cost = -np.sum(logprobs) / m return cost # 定义实现反向传播的函数 def back_propagation(parameters, cache, X, Y, m): """ 参数: parameters-神经网络的参数值 cache-缓存的正向传播的结果值 X-神经网络的输入值 Y-样本的输出值 m-输入样本的数量 返回: grads-反向传播计算的导数值构成的字典 """ W2 = parameters["W2"] A1 = cache["A1"] A2 = cache["A2"] dZ2 = A2 - Y dW2 = (1 / m) * np.dot(dZ2, A1.T) db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True) dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2)) dW1 = (1 / m) * np.dot(dZ1, X.T) db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True) grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2} return grads # 定义更新参数值的函数 def update(patameters, grads, learning_rate): """ 参数: parameters-神经网络参数值 grads-反向传播的导数值 learning_rate-学习率 返回: parameters-更新后的参数值 """ W1 = patameters["W1"] b1 = patameters["b1"] W2 = patameters["W2"] b2 = patameters["b2"] dW1 = grads["dW1"] db1 = grads["db1"] dW2 = grads["dW2"] db2 = grads["db2"] W1 = W1 - learning_rate * dW1 b1 = b1 - learning_rate * db1 W2 = W2 - learning_rate * dW2 b2 = b2 - learning_rate * db2 parameters = { "W1": W1, "b1": b1, "W2": W2, "b2": b2 } return parameters # 对神经网络进行训练 def nn_model(count): """ 参数: count-神经网络的迭代次数 返回: patameters-训练完成后神经网络的参数值 """ n = [2, 4, 1] # 神经网络每层的节点数 l = len(n) - 1 # 神经网络的层数 X, Y = pu.load_planar_dataset() # 加载训练集的数据 # 矩阵X、Y的维度 shape_X = X.shape shape_Y = Y.shape m = shape_X[1] parameters = initialization(n) # 初始化参数值 learning_rate = 0.5 # 对神经网络进行训练 for i in range(count): cache = forward_propagation(X, parameters) # 进行前向传播 cost = count_cost(cache, Y, m) # 计算成本函数 grads = back_propagation(parameters, cache, X ,Y, m) # 进行反向传播 parameters = update(parameters, grads, learning_rate) # 更新参数值 if(i%100 == 0): print("第" , i, "次学习的成本函数值: " + str(cost)) return parameters #对神经网络进行训练 count = 10000 parameters = nn_model(count) # 使用训练好的神经网络进行预测 def predict(X, parameters): """ 参数: X-输入的样本值 parameters-神经网络的参数值 返回: predictions-预测值 """ cache = forward_propagation(X, parameters) A2 = cache["A2"] predictions = np.round(A2) return predictions # 对样本进行预测并查看准确率 X, Y = pu.load_planar_dataset() # 加载训练集的数据 predictions = predict(X, parameters) print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
具体思路:
创建一个两层神经网络,一个输入层,一个隐藏层和一个输出层,输入层有两个特征值,隐藏层有四个神经单元,隐藏层使用的激活函数时tanh,输出层使用的激活函数时sigmoid。具体方法和实现logistic回归相似,主要分为训练和预测。训练主要包括四步:向前传播、计算成本函数值、向后传播和更新参数值。预测即向前传播的过程。
四.深度神经网络
4.1深层神经网络
下图是一个四层神经网络(输入层不计算在内),紫框中是常见的符号约定。

4.2深层网络中的前向传播
下图上节中深层神经网络前向传播的公式,对于如下过程需要进行for循换,循环次数是神经网络的层数。
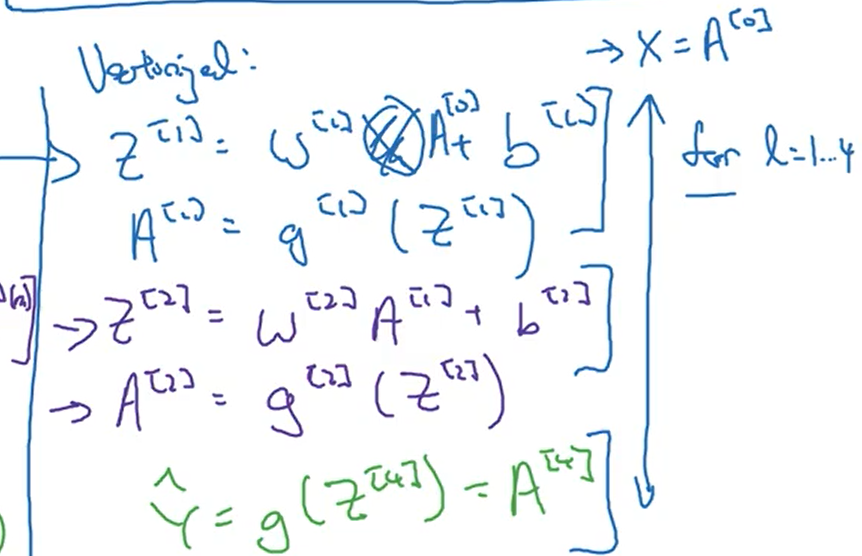
在调试神经网络的程序中,程序中很多bug是由于矩阵维数不匹配导致的,要注意检查。
4.3核对矩阵维数
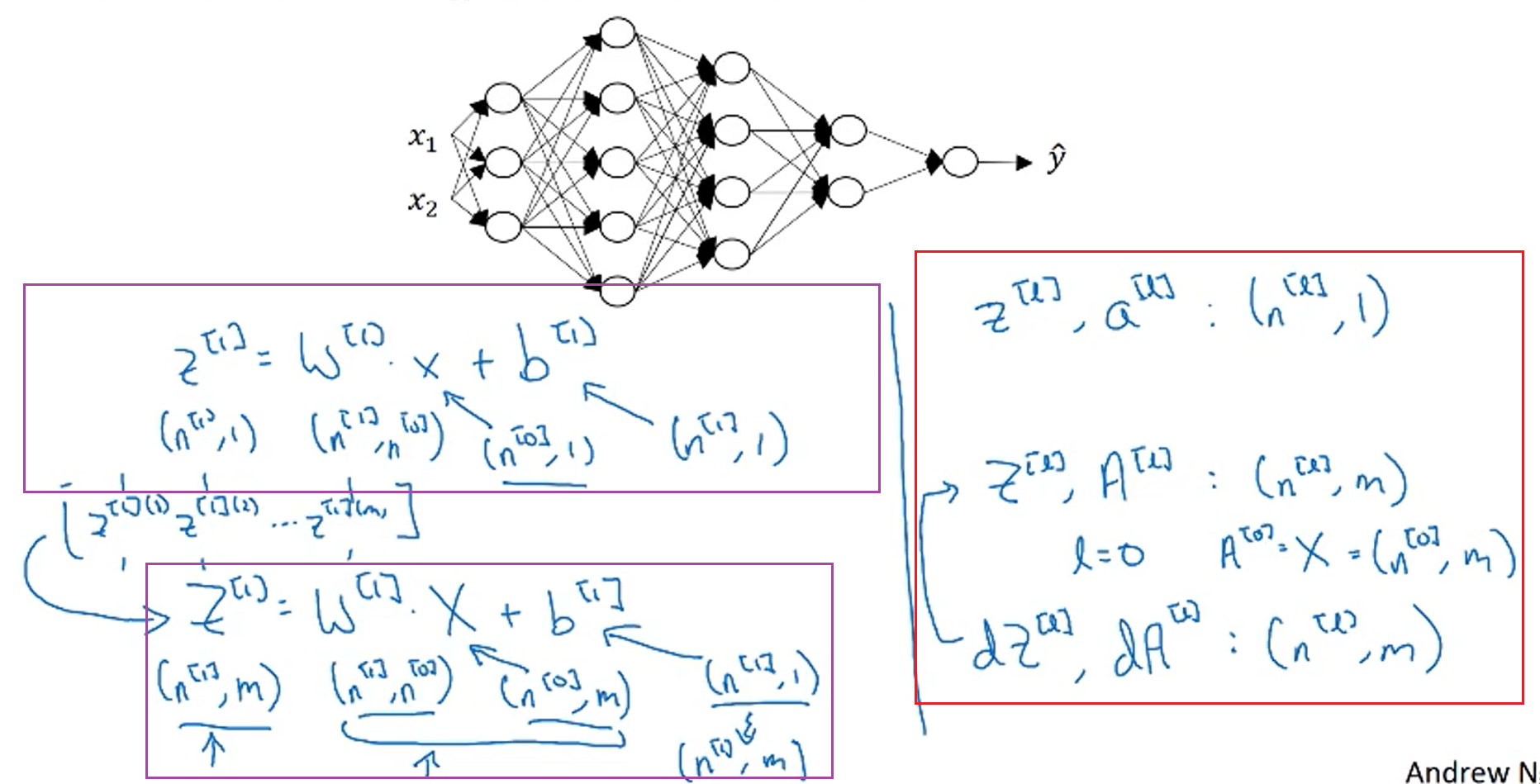
对于一个样本的矩阵维数公式,a的维数与z的维数相同
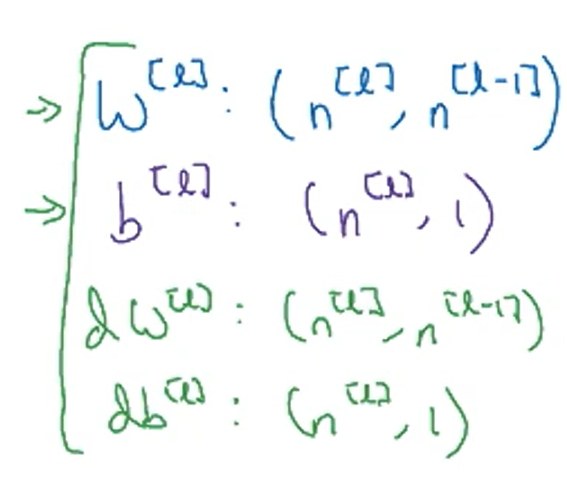
对于m个样本,紫框中是推导过程,红框中是m个样本的矩阵维数的公式
4.4为什么使用深层表示
对于深度神经网络的第一层,你可以看作一个特征探测器,它可以学习一些低层次的东西,比如探测照片的边缘,但这通常是对于一个小的部分的边缘探测,将前面的探测结果与后面几层结合后就可以学习更加复杂的函数。
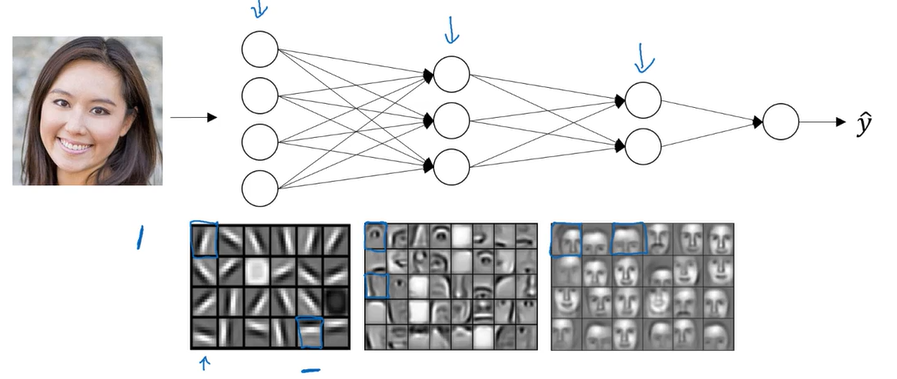
下图使用电路理论来说明为什么深度神经网络的效果很好。如果使用树形结构,模型的复杂度是logn,而如果使用一层的话,复杂度是2的n次方。
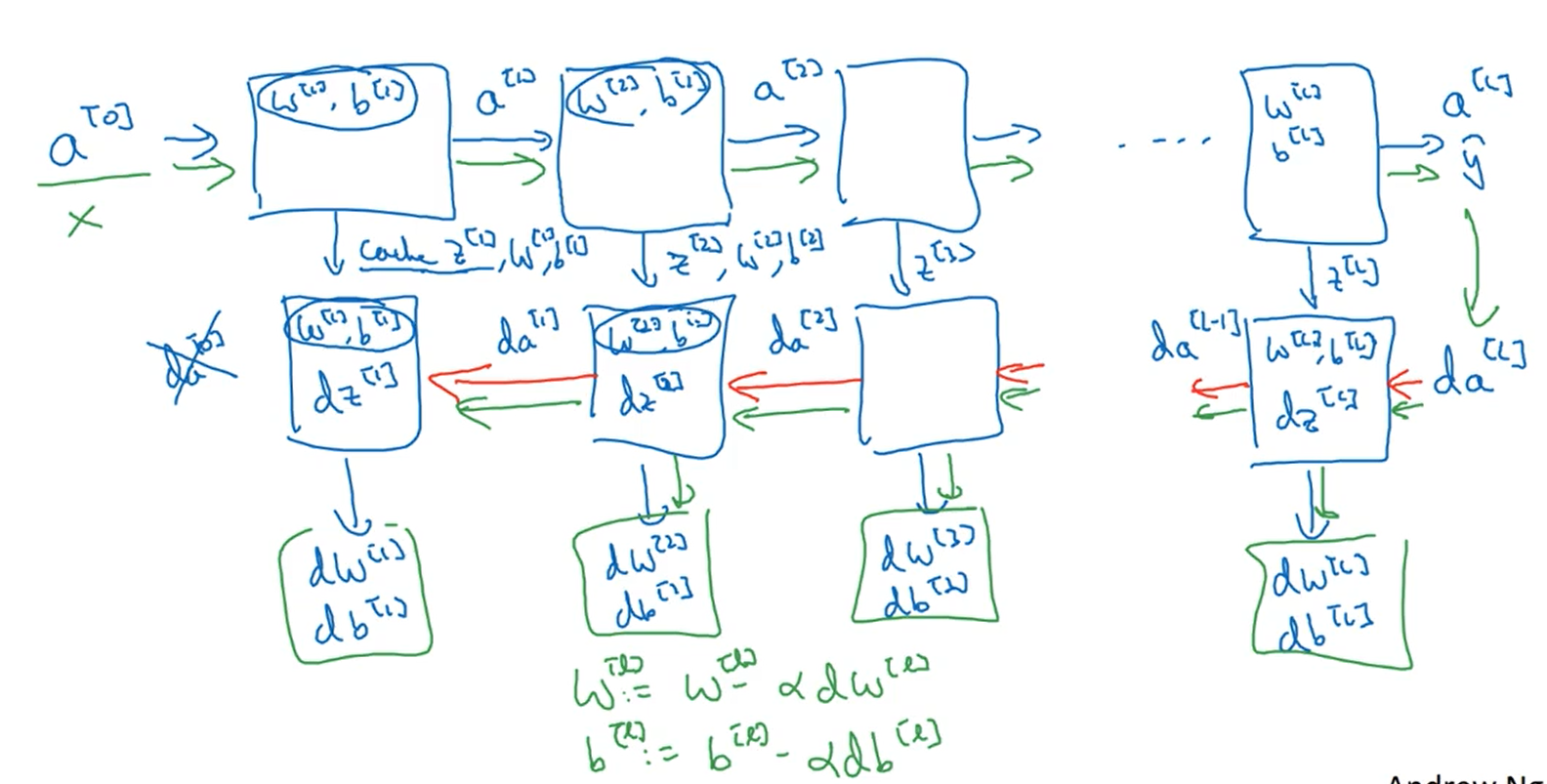
4.5搭建深层神经网络块
下图说明了神经网络正向和方向传播过程中每一层的输入和输出。在计算正向传播时,要把z值缓存下来,因为反向传播还要使用z的值。
4.6前向和反向传播
下图是神经网络前向传播过程中所用到的公式,竖线左侧是单个样本计算的公式,右侧是对于m个样本向量化后的公式。

下图是神经网络在反向传播过程中所用到的公式,竖线左侧是单个样本的,右侧是m个样本向量化后的结果。这里解释一下为什么要除以m,因为在使用梯度下降算法的过程中,成本函数是对于m个样本的损失函数取平均值,所以反向传递过程中参数的导数也是m个样本的平均值。

4.7参数VS超参数
下图列出了常见的超参数,比如学习率、神经网络的迭代次数、层数L、每层的神经元节点数和每层选择的激活函数等。超参数的选择最后会影响想到参数w和b的值,至于如何选择超参数的值,现在很大程度上是根据经验,然后不断的尝试不同的值,看神经网络的迭代速度以及成本函数值是否变小。

4.8这和大脑有什么关系
由于目前还不知道大脑的运行机制,所以很难说明神经网络与大脑有什么关系。