本文内容取自《概率论与数理统计 浙江大学 第四版》
目录 7
第一章 概率论的基本概念 11
确定性现象
随机现象:在大量重复试验中其结果又具有统计规律性的现象
1. 随机试验 11
2. 样本空间、随机事件 12
随机试验E,E的所有可能结果组成的集合称为E的样本空间,记为S,样本空间的每个元素,即E的每个结果,称为样本点
称试验E的样本空间S的子集为E 的随机事件,简称事件,在每次试验中,当且仅当这一子集中的一个样本点出现时,称这一事件发生。
基本事件:由一个样本点组成的单点集。还有必然事件、不可能事件
事件之间的运算:事件A,B,C

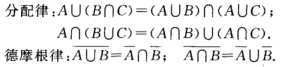
3. 频率与概率 15
相同条件下,进行了n次试验,在这n次试验中,事件A发生的次数nA称为事件A发生的频数,比值nA/n称为事件A发生的频率,记作 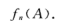

概率:设E是随机试验,S是它的样本空间,对于E的每一事件A赋予一个实数,记作P(A),称为事件A的概率。
由概率的定义,推得概率的一些重要性质。
性质i:1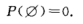
性质ii:有限可加性,若A1,A2..... An是不互相容的事件,则
性质iii:设A,B是两个事件,若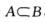 ,则
,则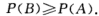
性质iv:对于任一事件A,P(A) <= 1
性质v:逆事件的概率,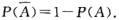
性质vi:加法公式,对于任意事件A,B 有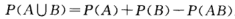
4. 等可能概型(古典概型) 19
等可能概型的两个特点:第一:试验的样本空间只包含有限个元素;第二:试验中每个基本事件发生的可能性相同。
样本空间 S = {e1, e2, e3, ..., en},则P({e1}) = P({e2}) = ... = P({en})

若事件A包含k个基本事件,即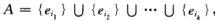 则有:
则有:
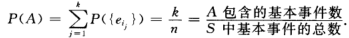
这就是等可能概型中事件A的概率计算公式(4.1)
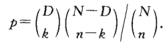
超几何分布的概率公式(4.2)
5. 条件概率 24
(一)条件概率 24
条件概率,是事件A已发生的条件下事件B发生的概率,记为P(B|A)
定义,设A,B是两个事件,且P(A) > 0 ,称  是在事件A发生的条件下事件B发生的条件概率
是在事件A发生的条件下事件B发生的条件概率
条件概率符合概率定义中的三个条件:A
非负性:对于每一事件B,有P(B|A)>=0
规范性:对于必然事件S,有P(S|A)=1
可列可加性:
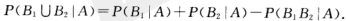
(二)乘法定理 26
乘法定理:设P(A)>0,则有 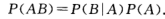
推广: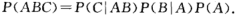
(三)全概率公式和贝叶斯公式 27 有先验概率,后验概率
全概率公式:设试验E的样本空间为S,A为E的事件,B1,B2,B3,....Bn 为S的一个划分,且P(Bi) >0,则有: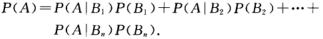
在很多实际问题中P(A)是不易求得,但却容易找到S的一个划分B1,B2,..Bn,且P(Bi)和P(A|Bi)或为已知,那么可以根据全概率公式求得P(A)
贝叶斯公式:设试验E的样本空间为S,A为E的事件,B1,B2,B3,....Bn 为S的一个划分,且P(A)>0,P(Bi)>0,则:

由条件概率的定义及全概率公式即可得到:
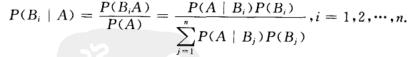
当n=2时,并将B1记为B,B2记为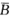 ,那么
,那么
全概率公式: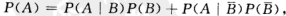
贝叶斯公式:
6.独立性 31
设A,B是试验E的两事件,若P(A)>0,可以定义P(B|A),一般,A的发生对B发生的概率是有影响的,这时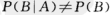 ,只有在这种影响不存在时才会有P(B|A)=P(B),
,只有在这种影响不存在时才会有P(B|A)=P(B),
这时有 P(AB) = P(B|A)P(A) = P(A)P(B)
定义,设A,B是两事件,如果满足等式 P(AB) = P(A) P(B),则称事件A,B相互独立,简称A,B独立
定理一,定理二,A,B,C相互独立(略)
第二章 随机变量及其分布 40
1.随机变量
对于样本空间 S={e}中的每一个样本点e,X都有一个数与之对应,X是定义在样本空间S上的一个实值单值函数,它的定义域是样本空间S,值域是实数集合{0,1,2,3} ,使用函数记号可以将X写成

随机变量的定义:设随机试验的样本空间为S = {e},X = X(e)是定义在样本空间S上的实值单值函数,称X=X(e)为随机变量。
本书中,我们 一般以大写的字母,X,Y,Z。。。表示随机变量,而以小写字母x,y,z。。。表示实数。
2.离散随机变量及其分布 42
有些随机变量,它全部可能的取值是有限个,可枚举的,这种叫离散型随机变量。
三种重要的离散型随机变量
(一)(0-1)分布
设随机变量X只有两个值 0和1,它的分布律是 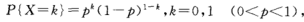 ,则称X服从以p为参数的(0-1)分布或两点分布。
,则称X服从以p为参数的(0-1)分布或两点分布。
0-1 分布的分布律也可写成

应用:性别、是否合格、抛硬币
(二)伯努利试验、二项分布 43
设试验E只有两个可能结果: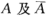 ,则称E为伯努利试验。n重伯努利试验
,则称E为伯努利试验。n重伯努利试验
(三)泊松分布 47
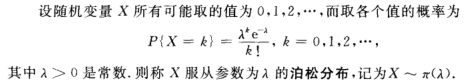
应用:某地区在一天内邮递遗失的信件数,某一医院在一天内的急诊病人数,某地区在一个时间间隔内发生的交通事故的次数
3. 随机变量的分布函数 48
对于非离散型随机变量X,由于其可能的值不能一一列举出来,因此就不能像离散型随机变量那样可以用分布律来描述它,我理解是用分布函数来描述它。
定义,设X是一个随机变量,x是任意实数,函数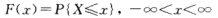 称为X的分布函数。
称为X的分布函数。
对于任意实数x1,x2 (x1<x2),有
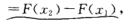
因此,若已知X的分布函数,我们就知道X落在任一区间(x1, x2]上的概率,从这个意义上说,分布函数完整地描述了随机变量的统计规律性。
分布函数是一个普通的函数,正是通过它,我们将能用数学分析的的方法来研究随机变量。
如果将X看成数轴上的随机点的坐标,那么,分布函数F(x)在x处的函数值就表示X落在区间(-无穷,x]上的概率。
4. 连续型随机变量及其概率密度 52
如果对于随机变量X的分布函数F(x),存在非负函数f(x),使对于任意实数x,有: ,则称X为连续型随机变量,其中函数f(x)称为X的随机密度函数,简称密度函数。
,则称X为连续型随机变量,其中函数f(x)称为X的随机密度函数,简称密度函数。
据数学分析的知识,连续型随机变量的分布函数是连续的。在实际应用中遇到的基本上是离线型的或者连续型的随机变量,本书只讨论这两种情况。
由定义可知,概率密度f(x)具有以下性质:
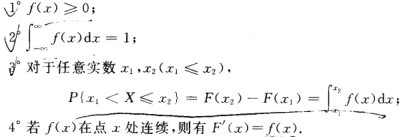
由第2点可知,曲线 y = f(x) 与Ox轴之间的面积等于1,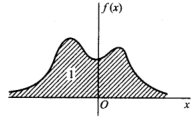
由第3点可知,X落在区间(x1, x2]的概率P{x1 < X <=x2}等于区间(x1, x2]上曲线y=f(x)之下的曲边梯形的面积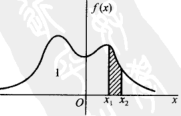
由第4点可知,f(x)的连续点x处有 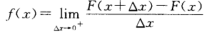
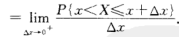
从这里我们看到概率密度的定义与物理学中的线密度的定义相类似,这就是为什么称f(x)为概率密度的缘故。
注意:F(x)是X的分布函数,f(x)是X的概率密度
以后当我们提到一个随机变量X的“概率分布”时,指的是它的分布函数;或者,当X是连续型随机变量时,指的是它的概率密度,当X时离散型随机变量时,指的是它的分布律
下面介绍三种重要的连续型随机变量:
(一)均匀分布 54
若连续型随机变量X具有概率密度 (4.6),则称X在区间(a,b)上服从均匀分布,记为X~U(a,b)
(4.6),则称X在区间(a,b)上服从均匀分布,记为X~U(a,b)
f(x) >=0, 且
在区间(a,b)上服从均匀分布的随机变量X,具有下述意义的等可能性,即它落在区间(a,b)中任意等长度的子区间内的可能性是相同的,或者说它落在(a,b)的子区间内的概率只依赖于子区间的长度,而与子区间的位置无关。
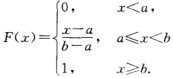
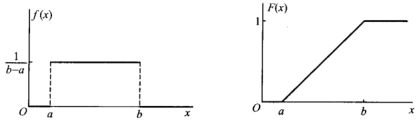
例2:设电阻值R是一个随机变量,均匀分布在900欧~1100欧,求R的概率密度及R落在950欧~1050欧的概率
(二)指数分布 55
若连续型随机变量X的概率密度为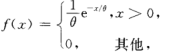 (4.7),其中 θ>0 为常数,则称X服从参数θ的指数分布。
(4.7),其中 θ>0 为常数,则称X服从参数θ的指数分布。 
易知  由(4.7)式容易得到随机变量X的分布函数为
由(4.7)式容易得到随机变量X的分布函数为 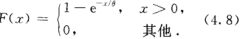 (取了个积分而已)
(取了个积分而已)
服从指数分布的随机变量X具有以下有趣的性质:对于任意s,t > 0 有 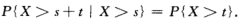 (4.9)
(4.9)
性质4.9称为无记忆性,如果X是某一元件的寿命,那么(4.9)式表明:已知元件使用了s小时,它总共能使用至少s+t小时的条件概率,与从开始使用时算起它至少能使用t小时的概率相等。这就是说,元件对它已使用过s小时没有记忆,具有这一性质是指数分布有广泛应用的重要原因。
指数分布在可靠性理论和排队论中有广泛的应用。
(三)正态分布 56
若连续型随机变量X的概率密度为 (4.10)其中
(4.10)其中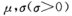 为常数,则称X服从参数为
为常数,则称X服从参数为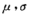 的正态分布或高斯Gauss分布,记作
的正态分布或高斯Gauss分布,记作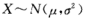
证明得到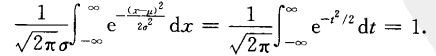
它具有以下的性质:
(1) 曲线关于 x=u 对称,这表明对于任意h>0,有
(2) 当x=u 时取到最大值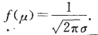
x离u越远,f(x)的值越小,这表明对于同样长度的区间,当区间离u越远,X落在这个区间上的概率越小。
在  处曲线有拐点,曲线以Ox轴为渐近线。
处曲线有拐点,曲线以Ox轴为渐近线。
另外,
如果固定σ,改变μ 的值,则图形沿着Ox轴平移,而不改变其形状,可见正态分布的概率密度曲线y=f(x)的位置完全由参数μ 所确定,μ 称为位置参数。
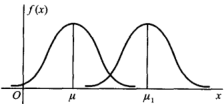
如果固定μ,改变σ 的值,由于最大值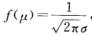 ,可知当σ 越小时图形变得越尖,因而X落在μ附近的概率越大。
,可知当σ 越小时图形变得越尖,因而X落在μ附近的概率越大。

由(4.10)式得X的分布函数为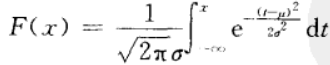 (4.12)
(4.12)
特别,当μ=0,σ=1时称随机变量X服从标准正态分布,其概率密度和分布函数分别用 φ(x) 和 Φ(x)表示,则有:
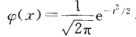 (4.13)
(4.13)
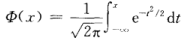 (4.14)
(4.14)
F(x) 的图形:
f(x) 的图形:
一般,若X~N(μ,σ2),我们只要通过一个线性变换就能将它化成标准正态分布。
3σ法则:尽管正态变量的取值范围是(-∞, +∞),但它的值落在 (μ-3σ,μ+3σ)内几乎是肯定的事,这就是人们所说的“3σ”法则
分位点,略
应用:在自然现象和社会现象中,大量随机变量都服从或近似服从正太分布,例如,一个地区的男性成年人的身高,测量某零件长度的误差,海洋波浪的高度,半导体器件中的热噪声电流或电压等,都服从正态分布。
在概率论和数理统计的理论研究和实际应用中正态随机变量起着特别重要的作用。
5. 随机变量的函数的分布 60
就是由X组成的函数的分布,比如:X是随机变量,Y=X-1,这个函数的分布。如果X是离散型的,Y也是离散的,用分布律;如果X是连续的,Y也是连续的,用密度函数。
第三章 多维随机变量及其分布 70
二维随机变量
离散型随机变量:求分布律,连续型随机变量:求概率密度
二维离散型随机变量的联合分布:F(x,y)
二维离散型随机变量的边缘分布:Fx(y), Fy(x)
二维离散型随机变量的条件分布:两者之间的关系
二维连续型随机变量的联合概率密度
性质:非负性、归一性(概率和为1)、求概率、分布函数与概率密度函数之间的关系
二维连续型随机变量的边缘分布:
第四章 随机变量的数字特征 100
上一章介绍了随机变量的分布函数、概率密度和分布律,它们都能完整地描述随机变量,但在某些实际或理论问题中,人们感兴趣于某些能描述随机变量某一特征的常数,例如,一篮球队上场比赛的运动员的身高是一个随机变量,人们常关心上场运动员的平均身高。
一个城市一户家庭拥有汽车的数量是一个随机变量,在考察城市的交通情况时,人们关心户均用户汽车的辆数。
评价棉花的质量时,既需要注意纤维的平均长度,又需要注意纤维长度与平均长度的偏离程度,平均长度较大,偏离程度较小,质量就较好。
这种由随机变量的分布所确定的,能刻画随机变量某一方面的特征的的常数称为数字特征,它在理论和实际应用中都很重要,本章将介绍几个重要的数字特征:数学期望、方差、相关系数和矩。
1. 数学期望
设离散型随机变量X的分布律为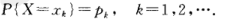
若级数 绝对收敛,则称级数
绝对收敛,则称级数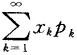 的和 为随机变量X的数学期望,记为E(X),即E(X) =
的和 为随机变量X的数学期望,记为E(X),即E(X) = 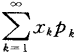
设连续型随机变量X的概率密度为f(x)
若积分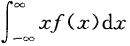 绝对收敛,则称积分
绝对收敛,则称积分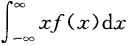 的值为随机变量X的数学期望,记为E(X),即E(X) =
的值为随机变量X的数学期望,记为E(X),即E(X) =
数学期望简称期望,又称均值
数学期望E(X)完全由随机变量X的概率分布所确定,若X服从某一分布,也称E(X)是这一分布的数学期望。
2.方差 110
容易看到能度量随机变量与其均值E(X)的偏离程度,但由于它带有绝对值,为运算方便起见,通常用量
来度量随机变量与其均值E(X)的偏离程度。
定义:设X是一个随机变量,若存在,则称
为X的方差,记为D(X)或Var(X)。
在应用上引入量 称为标准差或者均方差。
按照定义,随机变量X的方差表达了X的取值预期数学期望的偏离程度,若D(X)较小,意味着X的取值集中在E(X)的附近,反之,若D(X)较大则表示X的取值较为分散,因此D(X)是刻画X取值分散程度的一个量,它是衡量X取值分散程度的一个尺度。
由定义可知,方差实际上是随机变量X的函数的数学期望,于是
对于离散型随机变量,有
(2.2)
其中 是X的分布律。
对于连续性随机变量,有
(2.3)
其中f(x)是X的概率密度
随机变量X的方差可按下列公式计算
(2.4) 平方的期望减去期望的平方
方差的几个重要性质:
切比雪夫不等式 115
附表 389
附录表1中列出了多种常用的随机变量的数学期望和方差,供读者查用。
3.协方差及相关系数 116
对于二维随机变量(X,Y),我们讨论了X与Y的数学期望和方差以外,还需讨论描述X与Y之间相互关系的数字特征。
协方差和相关系数的重要公式 117
4.矩、协方差矩阵 120
略
第五章 大数定律及中心极限定理
极限定理是概率论的基本理论,在理论研究和应用中起着重要作用,其中最重要的是“大数定律”和“中心极限定理”的一些定理。
大数定律是叙述随机变量序列的前一些项的算术平均值在某种条件下收敛到这些项的平均值的算术平均值;
中心极限定理则是确定什么条件下,大量随机变量之和的分布逼近于正态分布。
本章节介绍几个大数定理和中心极限定理。
1.大数定律 129
第一章曾讲过,大量试验验证,随机事件A的频率当重复试验的次数n增大时呈现出稳定性,稳定在一个常数附近。频率的稳定性是概率定义的客观基础。
本节我们将对频率的稳定性作出理论的说明。
弱大数定律(辛钦大数定律)
下面介绍辛钦大数定理的一个重要推论
频率稳定性的真正含义,用事件的频率代替时间的概率。
2.中心极限定理 131
在客观实际中有许多随机变量,它们是由大量的相互独立的随机因素的综合影响所形成的,而其中每一个别元素在总的影响中所起的作用都是微小的,这种随机变量往往近似地服从正态分布。
这种现象就是中心极限定理的客观背景。本节只介绍三个常用的中心极限定理。
定理一 独立同分布的中心极限定理
这就是独立同分布中心极限定理结果的另一种表现形式,就是说,均值为μ,方差为 σ方>0 的独立同分布的随机变量X1,X2。。Xn的算术平均,当n充分大时近似地服从均值为μ,方差为
的正态分布。这一结果是数理统计中大样本统计推断的基础。
定理二 李雅普诺夫(Lyapunov)定理
定理三 拉普拉斯定理
中心极限定理表明,在相当一般的条件下,当独立的随机变量的个数不断增加时,其和的分布趋于正态分布。
第六章 样本及抽样分布
-----------------
统计量:不含任何未知参数的样本的函数称为统计量。X1,X2,X3.。。Xn是来自总体X的一个样本,g(X1,X2,X3。。Xn)是X1,X2,X3.。。Xn的一个函数。若g中不含任何未知参数,则g(X1,X2,X3。。Xn)是一个统计量