一.Java集合框架
集合,有时也称为容器,是一个用来存储和管理多个元素的对象。Java中的集合框架定义了一套规范,用来表示和操作集合,使具体操作与实现细节解耦。集合框架都包含下列内容:
- 接口:这些是表示集合的抽象数据类型,它们定义了集合中常见的操作。
- 实现:为各种集合提供了具体的实现。
- 算法:这些是对实现集合接口的对象执行有用计算(如搜索和排序)的方法。算法被认为是多态的:也就是说,相同的方法可以用于集合接口的不同实现。
集合框架有以下优点:
- 减少编程工作:通过提供有用的数据结构和算法,集合可以让我们专注于程序的重要部分,而不是考虑如何实现集合。
- 提高程序速度和质量:集合框架提供了各种集合的高性能、高质量实现,使得我们在编写代码时不必过多地考虑程序的速度和性能。
- 促进代码重用:如果我们要实现自己的集合,只需要实现集合框架中的标准接口,就可以应用集合框架提供的算法,而无需重复地“造轮子”。
二.接口
下图是集合框架中的核心接口:
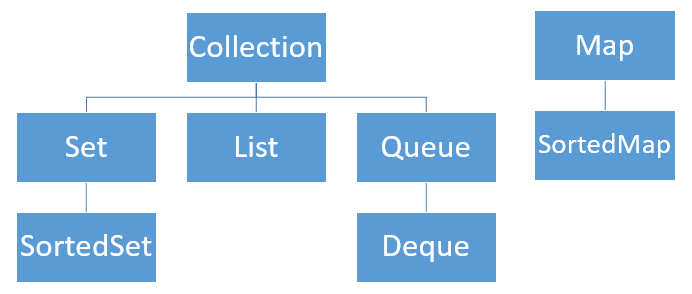
Java中的集合框架分为Collection和Map两类。下面是这两个接口的声明:
public interface Collection<E> extends Iterable<E> {...}
public interface Map<K,V> {...}
可以看到,Java中的集合都是泛型的。在声明集合时,应该指定集合中包含的对象类型。这样编译器可以帮我们验证放入集合中的对象类型是否正确,从而减少运行时的错误。
现在对上图中的接口进行介绍:
- Collection:集合层次结构的根接口。集合表示一组被称为元素的对象,不同的集合有不同的特点。例如,有些集合允许存在重复的元素,有些则不允许;有些集合的元素是有序的,有些则是无序的。这个接口定义了所有集合都应该具有的行为,至于这些特性行为则交给子接口去定义。Java平台不提供这个接口的直接实现,而是提供它的子接口的实现。
- Set:不能包含重复元素的集合。这个接口是对数学概念中的集合的抽象。
- List:List表示有序集合。注意,这个有序的意思是位置有序,而不是内容有序。它与Set的区别在于,Set没有位置的概念,并且List允许有重复的元素。
- Queue:Queue是对数据结构中的队列的抽象。队列按照(但不一定)FIFO(first in first out,先进先出)方式对元素进行存放,它的插入和删除操作是在不同的两端进行的。
- Deque:Deque表示双端队列,它与Queue的不同之处在于它的两端都支持插入和删除。
- Map:映射层次结构的根接口。它可以用来存储多个键值对,但是Map中不能包含重复键。
最后的两个接口仅仅是Set和Map接口的排序版本:
- SortedSet:按升序维护Set中的元素。它提供了几个额外的操作来利用Set中的顺序。
- SortedMap:按键的升序来维护Map中的键值对。它也提供了几个额外的操作来利用Map中的顺序。
下面分别对这些接口进行介绍。
1.Collection接口
集合表示一组被称为元素的对象,它与数组的最大区别就是数组的长度是固定的,而集合的长度是可以动态变化的。当我们无法事先预估元素的个数时,就可以选择使用集合。此外,使用集合还可以利用集合为我们提供的大量实用的方法。
Collection接口用在需要最大通用性地传递集合的地方。例如,按照惯例,每种集合的实现都有一个接受Collection参数的构造方法。这个方法被称为转换构造器,它使用指定集合中的所有元素来初始化新的集合,无论给定的集合是什么类型。换句话说,使用这个构造方法可以转换集合的类型。
例如,现在有一个Collection
List<String> list = new ArrayList<>(c);
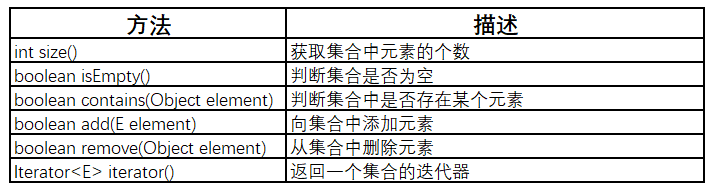
Collection接口中包含了一些基本操作:
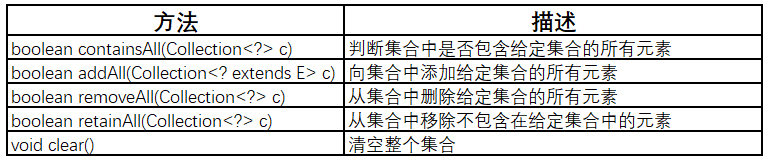
Collection接口中还包含了一些操作整个集合的方法:
还有两个将集合转为数组的方法:

这两个方法都可以将集合转换为数组。不过,toArray()方法只能将集合转换为Object数组,而Object数组又无法直接强制转换为其他类型的数组,因此这个方法的实用性就要差一些。而toArray(T[] a)方法则可以直接将集合转换为T类型的数组,如果参数a的长度小于集合中元素的个数,该函数会返回一个包含集合中所有元素的新的数组;如果参数a的长度大于等于集合中元素的个数,该函数就会使用数组a来返回,并且在a[size]放置一个null,size表示集合中元素的个数,这样toArray(T[] t)方法的调用者就可以知道null后面已经没有集合元素了。不过,一般我们传递的数组只是为了传递数组的类型,因此我们会传递一个空的数组进去。例如,假设现在有一个存放字符串的集合,要将它转换为字符串数组,可以像下面这样写:
String[] y = x.toArray(new String[0]);
从Java8之后,Collection接口中增加了两个与流(Stream)相关的方法,Stream
遍历Collection
有三种遍历Collection的操作:(1)增强型for循环;(2)迭代器;(3)聚合操作。
(1)增强型for循环
我们早在流程控制一文中已经提到了增强型for循环。增强型for循环可以用来遍历数组或实现了Iterable接口的类。从上面的Collection接口的声明可以看到,Collection接口继承了Iterable接口,这意味着所有的集合都可以使用增强型for循环来遍历。例如:
public void traverseWithFor(Collection<String> collection) {
for(String str : collection) {
System.out.println(str);
}
}
(2)迭代器
迭代器(也称作游标)是一种可以访问容器中的元素的对象。由于各种容器的内部结构不同,它们的遍历方式也就不尽相同。为了使对容器内元素的遍历方式更加简单和统一,Java引入了迭代器模式。迭代器模式提供了一种方法顺序访问一个聚合对象中的各种元素,但又不暴露该对象的内部表示。Java中定义的迭代器接口是Iterator
boolean hasNext();
E next();
void remove();
}
hasNext方法用于判断迭代器所在的位置后面是否存在元素,而next方法则会返回迭代器所在位置后面的元素并移动迭代器,如果没有下一个元素,这个方法会抛出NoSuchElementException。remove方法会移除上一个由next返回的元素,但是这个方法只能在每次调用next后调用一次。
如何获取迭代器呢?或者说什么样的对象才能获取迭代器呢?实际上,如果要从一个对象上获取迭代器,那么这个对象必须是可迭代的,也就是说这个类必须实现Iterable接口,通过Iterable的iterator方法可以获取到迭代器。Collection接口继承了Iterable接口,也就是说所有的集合都是可迭代的,因此可以从所有的集合对象上获取迭代器,并使用迭代器对集合进行遍历。例如:
public void traverseWithIterator(Collection<String> collection) {
Iterator <String> it = collection.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
如果要在遍历的过程中删除元素,那么使用迭代器的remove方法是最安全的做法,调用Collection中定义的remove方法可能会引起错误。例如:
public void removeSomething(Collection<String> collection, String something) {
for(int i = 0;i < collection.size(); ++i){
if(collection.get(i).equals(something)) {
collection.remove(i);
}
}
}
这种方式的问题在于,删除某个元素后,集合内元素的索引发生变化,而我们的索引也在变化,所以会导致你在遍历的时候漏掉某些元素。而且,如果在删除元素时引起了集合的收缩(当集合中的元素个数小于集合的容量且达到一定程度后,集合会自动进行缩容操作),那么我们的最后几次循环可能会造成索引越界。所以,更安全的做法是:
public void removeSomething(Collection<String> collection, String something) {
Iterator <String> it = collection.iterator();
while(it.hasNext()) {
if(it.next().equals(something)) {
it.remove();
}
}
}
(3)聚合操作
在Java8及更高版本中,迭代集合的首选方法是获取流并对其执行聚合操作。聚合操作通常与lambda表达式结合使用,以使用较少的代码使程序更具表现力。以下代码按顺序遍历一个形状集合并打印出红色的形状:
myShapesCollection.stream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
同样,您可以轻松地请求并行流,如果集合足够大并且您的CPU具有足够的核心,这可能是有意义的:
myShapesCollection.parallelStream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
使用此API操作集合元素的方法有很多种。例如,您可能希望将一个Collection的元素转换为String对象,然后将它们连接起来,用逗号分隔:
String joined = elements.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
或者对所有员工的工资进行求和:
int total = employees.stream()
.collect(Collectors.summingInt(Employee::getSalary)));
这里只是简单的对集合的聚合操作进行一个简单的展示,稍后我们将会详细地介绍聚合操作。
批量操作
批量操作对于整个集合进行操作。下面是Collection中的批量操作:
- containsAll(Collection<?> c):如果集合中包含指定集合的所有元素,则返回true。
- addAll(Collection<? extends E> c):将指定集合的所有元素添加到当前集合。
- removeAll(Collection<?> c):从集合中删除指定集合中的所有元素。
- retainAll(Collection<?> c):从当前集合中删除指定集合中不存在的元素,相当于求交集操作。
- clear():从集合中删除所有元素。
如果集合发生了变化,那么addAll,removeAll和retainAll将会返回true。
为了展示批量操作的效率,下面的例子从集合c中删除指定元素e:
c.removeAll(Collections.singleton(e));
或者说,要从集合中删除所有null元素:
c.removeAll(Collections.singleton(null));
Collections.singleton是一个静态工厂方法,它返回一个只包含一个元素的Set。Collections类提供了大量操作集合的方法,我们会在下面逐一进行介绍。
2.Set接口
Set是Collection接口的子接口,它表示不能含有重复元素的集合,这一点和数学中的集合相同。Set接口包含了继承自Collection接口中的方法并添加了禁止重复元素的限制。
下面是一个简单但实用的使用Set的例子。假设现在有一个集合,我们希望创建另一个包含相同元素但删除了所有重复元素的集合:
Collection<Type> noDups = new HashSet<>(c);
Set最大的特点就是不包含重复项,因此在构造过程中会自动去除重复的元素,而无需我们关心。上面使用的HashSet是Set接口的一个实现,我们会在稍后介绍各接口的常用实现。
由于Set接口继承自Collection接口,因此大部分方法都和Collection接口中的方法相同,这里不再赘述。此外,从Java 9之后,Set接口还提供了of和copyOf两个用于快速创建集合的静态方法,不过需要注意的是,它们创建的都是不可变的Set,也就是说集合一经创建就不能再添加或删除元素。其中of方法接受0个或多个参数,并返回包含这些元素的不可变集合,而copyOf则根据指定的集合来创建包含该集合中元素的不可变集合。下面是使用这两个方法的例子:
Set<Integer> set1 = Set.of(1, 2);
Set<Integer> set2 = Set.copyOf(set1);
此外,对于Set来说,只要两个集合的元素都是相等的,那么我们就认为这两个集合是相等的。这与Object类默认的equals方法不同,因此在实现Set接口时,我们还需要重新定义equals和hashcode方法。
3.List接口
List也是Collection接口的子接口,它表示有序集合,并且它可以包含重复元素,有时也将其称之为列表。除了继承自Collection的方法外,它还支持以下操作:
- 位置访问:根据在列表中的位置来操作元素,例如get、set、add、addAll和remove等方法。
- 查找:查找指定的对象并返回其在列表中的位置,查找方法包括indexOf和lastIndexOf。
- 迭代:除了继承自Collection接口的iterator方法,List接口还提供了listIterator方法来获取利用列表的顺序性对列表进行遍历的迭代器。
- 视图操作:subList方法获取一个子列表的视图,对它进行操作实际上就是对原列表进行操作。
- 排序:按照指定的比较规则对列表中的元素进行排序。
- 替换:按照指定的规则对列表中的元素进行替换。
由于List接口继承自Collection接口,因此Collection中的方法不再介绍。此外,List接口中也包含of和copyOf静态方法,除了它返回的是不可变的List之外,其他都和上面Set接口中的这两个方法一致。下面对List接口中特有的方法进行介绍。
位置访问
下面是List接口中与位置有关的操作:
- add(int index, E element):将指定元素插入到指定位置上。
- addAll(int index, Collection<? extends E> c):将指定集合中的元素插入到指定位置上。
- get(int index):获取指定位置上的元素。
- remove(int index):移除指定位置上的元素。
- set(int index, E element):使用指定元素替换指定位置上的元素。
这些方法的使用都比较简单,这里不再一一举例。
搜索
List接口中提供了indexOf和lastIndexOf两个方法来对指定元素进行查找,它们与contains最大的区别就是如果找到元素,就可以返回元素在列表中的位置。如果没有找到,这两个方法将会返回-1。由于列表允许重复的元素,因此indexOf会返回从前向后查找时该元素第一次出现的位置,而lastIndexOf会返回从后向前查找时该元素第一次出现的位置。例如:
List<Integer> intList = List.of(0, 1, 2, 1, 0);
System.out.println(intList.indexOf(1));
System.out.println(intList.lastIndexOf(1));
上面的例子将会输出:
1
3
迭代器
除了继承自Collection接口的iterator方法,List接口还提供了listIterator方法,使用这个方法可以获取一个ListIterator类型的迭代器。使用这种迭代器可以以任一方向对列表进行遍历,在遍历期间修改列表(不只是删除,还可以插入和替换),或者是获取迭代器的当前位置。
ListIterator接口是Iterator接口的子接口,除了继承自Iterator接口的三个方法外(hasNext、next和remove),它还新增了六个方法。下面是这九个方法的简介:
- hasNext():判断迭代器所在的位置后面是否有元素。
- next():返回迭代器所在位置后面的元素并向后移动迭代器。
- hasPrevious():判断迭代器所在的位置前面是否有元素。
- previous():返回迭代器所在位置前面的元素并向前移动迭代器。
- previousIndex():返回迭代器所在位置的前一个元素的索引。
- nextIndex():返回迭代器所在位置的后一个元素的索引。
- add(E e):将指定元素插入到迭代器所在的位置前面。
- set(E e):使用指定元素替换上一次next或previous操作返回的元素。
- remove():移除上一次next或previous操作返回的元素。
这里有必要解释一下ListIterator的位置的概念。对于一个ListIterator来说,它的游标并不指向某个元素,而是位于两个元素之间。如果一个列表有n个元素,那么ListIterator的游标的位置就有n+1个,例如:
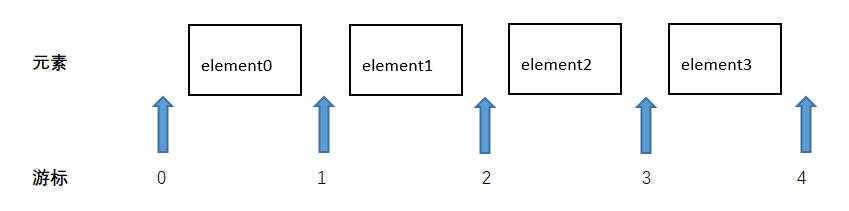
上图中的列表共有4个元素,那么游标可能出现的位置就有5个,分别是0,1,2,3,4。
List接口的listIterator方法有两种形式。listIterator()返回一个游标在0处的迭代器,listIterator(int index)返回一个指定位置的迭代器,例如上图中,list.listIterator(4)就会返回最后一个位置的迭代器。通过这两个方法和ListIterator,就可以从任意位置,任意方向去遍历列表。
需要注意的是,remove和set方法并没有涉及到迭代器的位置,它们操作的是上一次next或previous操作返回的元素。除此之外,在调用next或previous之后,调用remove之前,这中间不能调用add方法;而在调用next或previous之后,调用set之前,这中间不能调用add或remove方法。这是由于如果在set或remove之前进行了其他操作,列表会发生变化,此时再调用这两个方法有可能产生歧义,因此为了避免这种情况,这两个方法将会抛出IllegalArgumentException。
视图操作
subList(int fromIndex, int toIndex)是一个视图操作,它返回一个子列表,这个子列表包含了原列表中索引在fromIndex到toIndex(不包括toIndex)之间的元素。之所以说subList是一个视图操作,是因为它返回的子列表的元素都是原列表中的元素,而不是它们的拷贝。对子列表的操作也会影响到原列表。
例如,下面的例子从列表中移除子列表视图中的元素:
list.subList(fromIndex, toIndex).clear();
这比我们使用迭代器去删除这些元素简洁不少。下面的例子在指定的范围中查找元素:
int i = list.subList(fromIndex, toIndex).indexOf(o);
int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
注意,上面的例子中返回的是元素在子列表中的索引,而不是在原列表中的索引。
尽管subList操作非常强大,但在使用时必须小心。在修改了原列表后,不要再使用之前的subList,否则可能会出现异常,例如:
List<String> list = new ArrayList<>();
list.add("0");
list.add("1");
list.add("2");
list.add("3");
List<String> subList = list.subList(0,2);
list.remove(1);
System.out.println(subList);
上面的程序中,subList是索引为0和1的两个元素的视图,从原集合中删除索引为1的元素,视图也会随着改变。但是对于我们来说,如果这个操作在其他的方法中,那么我们无法感知视图的变化,程序也有可能会抛出异常。为了避免这种情况,建议在修改原始列表后,不要再使用之前的视图,而是应该重新获取。
排序
List接口提供了一个默认方法sort(Comparator<? super E> c),它接受一个Comparator类型的对象作为参数,然后根据该对象中定义的比较规则对列表进行排序。Comparator定义了某种类型的比较规则,它只有一个抽象方法compare(T o1, T o2),因此它是一个函数式接口,也就是说可以向sort方法传递lambda表达式。当o1大于o2时,compare方法返回正数;当o1小于o2时,compare方法返回负数;当o1等于o2时,compare方法返回0。
现在假设我们有一个Apple类,这个类有weight以及其他的属性。当一个Apple的weight大于另一个Apple的weight时,我们就认为这个Apple是“大于”另一个Apple的。根据这个定义,我们来编写用于排序Apple列表的Comparator:
public class AppleComparator implements Comparator<Apple> {
public int compare(Apple a1, Apple a2) {
return a1.getWeight() - a2.getWeight();
}
}
现在就可以对Apple列表appleList进行排序了:
appliList.sort(new AppleComparator());
当然,可以使用更加简洁的lambda表达式,这样就无需编写AppleComparator类了,只需要像下面这样:
appleList.sort((a1, a2) -> a1.getWeight() - a2.getWeight());
sort方法首先将列表转换为数组,然后使用归并排序对数组进行排序,最后再将数组中的元素放回列表中。该sort方法提供了快速、稳定的排序(排序算法的稳定性是排序前后相等元素的相对顺序不发生改变)。
替换
List接口提供了一个默认方法replaceAll(UnaryOperator
利用这个方法可以对满足条件的元素执行替换操作。例如,现在有一个存放字符的集合charList,我们需要找到其中的小写字母并将其转换为大写字母:
charList.replaceAll(c -> {
if (Character.isLowerCase(c)) {
return Character.toUpperCase(c);
}
return c;
});
列表算法
除了List接口中声明的这些方法以外,Collections类还提供了许多操作List的方法。下面对这些方法进行简要地介绍:
- sort——对指定的列表进行排序,本质上只是调用了List自身的sort方法。
- shuffle——随机打乱列表中元素的顺序。
- reverse——反转列表。
- rotate——将列表按照指定的距离进行旋转。
- swap——交换两个指定索引处的元素。
- replaceAll——使用指定的新元素替换指定的旧元素。
- fill——使用指定元素替换列表中的所有元素。
- copy——将源List中的元素拷贝到目标List。
- binarySearch——使用二分查找算法在列表中查找元素,前提是列表必须是排好序的(升序)。
- indexOfSubList——从前向后查找子列表在指定列表中出现的位置,若未找到则返回-1。
- lastIndexOfSubList——从后向前查找子列表在指定列表中出现的位置,若未找到则返回-1。
4.Queue接口
队列是在处理之前保存元素的集合。除了基本的集合操作外,Queue接口还新增了以下方法:
E element();
boolean offer(E e);
E peek();
E poll();
E remove();
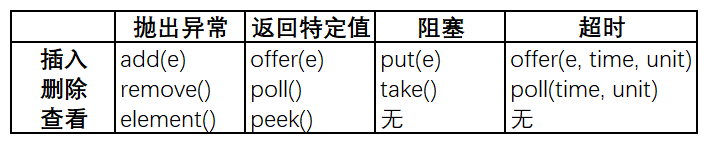
Queue的每种方法都存在两种形式:一种是在操作失败的时候抛出异常,另一种在操作失败的时候返回特定值(null或false,取决于操作类型)。下表列出了这些方法:
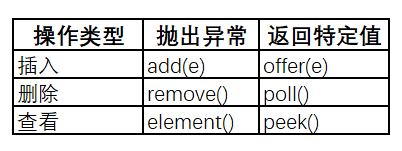
队列通常(但不一定)是按照先进先出(FIFO,first in first out)的方式来保存元素。优先级队列除外,它们根据元素的值对元素进行排序。无论使用什么顺序,队列头部的元素都是通过调用remove或poll方法将会被删除的那个元素。在FIFO队列中,所有的新元素都被插入队列的尾部。其他类型的队列可能使用不同的排列规则。每个Queue接口的实现都必须指定其排序特性。
有些类型的队列会限制元素的个数,这样的队列被认为是有界的。java.util.concurrent包中的某些Queue的实现是有界的,而java.util包中的Queue的实现则不是。
Queue接口中的add方法继承自Collection接口,它向队列中插入一个元素。如果元素的个数超出容量限制,这个方法会抛出一个IllegalStateException异常。另一个向队列中插入元素的方法是offer方法,当插入失败时,这个方法将会返回false。当使用有界队列时,更推荐使用这个方法。
remove和poll方法都返回并移除队列头部的元素。当队列为空时,remove抛出NoSuchElementException异常,而poll则返回null。
element和peek方法返回但不移除队列头部的元素。当队列为空时,element抛出NoSuchElementException异常,而peek则返回null。
Queue的实现类通常来说不允许插入null元素。但LinkedList类是个例外,它也是Queue的实现类,但是它允许插入null。在使用LinkedList时应该避免插入null元素,因为null被peek和poll方法作为特殊的返回值。
下面的例子将队列用作一个倒计时器:
public void countdown(int seconds) throws InterruptedException {
int time = Integer.parseInt(seconds);
Queue<Integer> queue = new LinkedList<Integer>();
for (int i = time; i >= 0; i--)
queue.add(i);
while (!queue.isEmpty()) {
System.out.println(queue.remove());
Thread.sleep(1000);
}
}
该程序将会每秒输出一个数字,这个数字代表倒计时所剩的秒数。由于我们入队时是按照从大到小的顺序,而出队时也是从大到小的顺序,这正好证明了队列的先进先出的特性。
5.Deque接口
Deque是Queue的子接口,它表示双端队列。双端队列是支持在两端进行插入和删除操作的队列。正是由于双端队列支持在两端进行操作,它既可以被用作后进先出的栈,也可以被用作先进先出的队列。
由于Deque支持在两端进行插入、删除和查看操作,再加上每种操作都有抛出异常和返回特殊值两种形式,因此Deque接口中共定义了以下12个访问元素的方法:
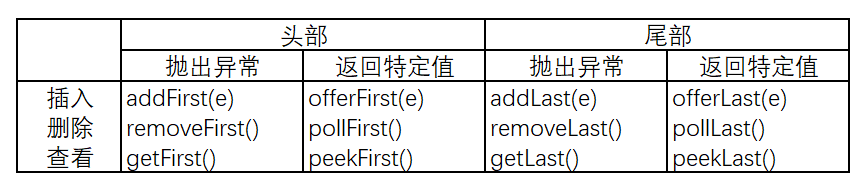
以上这些方法与除了操作的位置不同外,其余与Queue中的方法完全相同,这里不再赘述。除此之外,Deque还提供了removeFirstOccurence和removeLastOccurence两个方法,这两个方法分别删除指定元素在Deque中第一次和最后一次出现的位置。
6.Map接口
Map接口表示映射结构,它是对数学概念中的映射的抽象,可以将它理解为存储键值对的集合。但实际上它并不是集合,它是Java集合框架中映射结构的顶级接口。通过给定的键可以很快地从Map中找到对应的值。Map中不能包含重复的键,如果向Map中插入键相同的键值对,那么Map中这个键对应的值将会被新的值覆盖。
下面是Map接口中定义的基本方法:
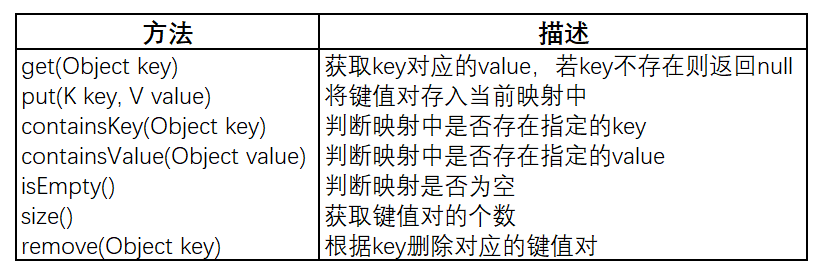
需要注意的是,某些Map实现支持null值,而有些则不支持。因此,当使用get方法获取value时,若返回null,则需要根据对应的实现类来进行判断是key不存在还是key对应的value是null。当然,为了保险起见,可以先调用containsKey来判断指定的key是否存在。
除了操作单个元素的基本操作外,Map中还定义了两个批量操作映射的方法:

Map中定义了一个内部接口Entry,它用来表示Map中的一个键值对。Entry接口提供了getKey和getValue方法,可以分别获得键值对的键和值。Map接口还提供了一个静态方法entry(K key,V value),这个方法将会根据指定的key和value生成一个不可变的Entry类型的对象。
Map接口提供了针对键、值和键值对的集合视图:
- keySet——返回包含Map中所有键的Set。
- values——返回包含Map中所有值的Collection。这个Collection不会是Set,因为多个键可能对应相同的值。
- entrySet——返回包含Map中所有键值对的Set。
Map接口中还提供了几个可以直接返回Map实例的方法:
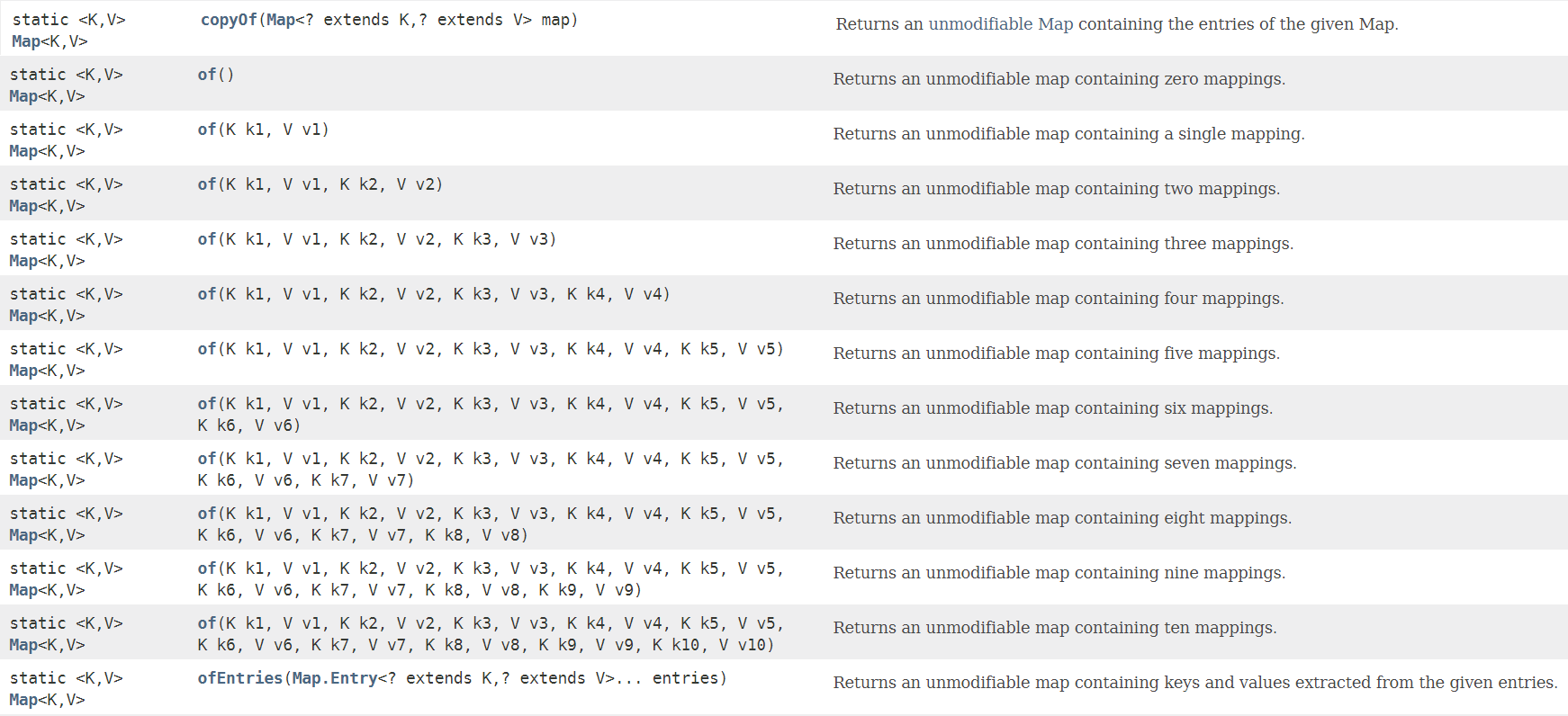
copyOf相当于是对原Map的拷贝,of方法根据指定的若干对键和值来创建Map,ofEntries接受的是可变参数,它根据指定的若干个键值对来创建Map。需要注意的是,这些方法返回的都是不可变的Map,对其调用任何可能会改变映射内容的方法都会抛出异常。
此外,Map接口中还提供了一些实用的默认方法,下面对这些方法做一个简单的介绍,具体的使用方法可以参考官方的API:

7.SortedSet接口
SortedSet是Set接口的子接口,它实际上是Set的排序版本。它对内部的元素按照自然顺序或者在构建SortedSet的实例时指定的Comparator来对元素进行排序。我们上面提到的TreeSet就实现了SortedSet接口。除了继承自Set接口的方法外,SortedSet还提供了以下操作:
- 范围视图:获取任意范围内的元素的视图。
- 访问双端元素:返回第一个或最后一个元素。
- 获取比较器:返回排序使用的比较器(如果有)。
自然顺序是指在比较一个对象和另外一个对象时,先将该对象强转为Comparable类型。若类型转换失败,则抛出ClassCastException,这表示该类没有实现Comparable接口,即没有提供默认的比较方法;若转换成功,则通过compartTo方法的返回值来对两个对象进行比较。
SortedSet中定义了以下方法:
public interface SortedSet<E> extends Set<E> {
// Range-view
SortedSet<E> subSet(E fromElement, E toElement);
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
// Endpoints
E first();
E last();
// Comparator access
Comparator<? super E> comparator();
}
SortedSet的视图操作共有三个方法:
- subSet(E fromElement, E toElement):返回包含范围在fromElement(包含)到toElement(不包含)之间的元素的集合。
- headSet(E toElement):返回小于toElement的元素的集合。
- tailSet(E fromElement):返回大于fromElement的元素的集合。
与List的视图不同,即使修改了原集合,SortedSet的视图仍然有效。List的视图是原集合中的特定元素,当原集合发生结构性的变化后,视图无法继续保持原来的特定元素;而SortedSet的视图则是原集合中特定范围内的元素,只与范围有关,因此在修改了原集合之后,视图仍然有效。
访问双端元素的方法是first()和last(),它们分别返回SortedSet中的第一个元素和最后一个元素。
通过comparator()方法可以获取SortedSet在排序时使用的比较器。如果集合内元素是按照自然顺序排序的,这个方法将会返回null。
8.SortedMap接口
SortedMap是Map接口的子接口,它实际上是Map的排序版本。它按照自然顺序或者在构建SortedMap的实例时指定的Comparator来对键进行排序。与SortedSet类似,它也提供了以下操作:
- 范围视图:获取键在指定范围内的子映射的视图。
- 访问双端键:返回第一个或最后一个键。
- 获取比较器:返回排序使用的比较器(如果有)。
SortedMap中定义了以下方法:
public interface SortedMap<K, V> extends Map<K, V>{
// Range-view
SortedMap<K, V> subMap(K fromKey, K toKey);
SortedMap<K, V> headMap(K toKey);
SortedMap<K, V> tailMap(K fromKey);
// Endpoints
K firstKey();
K lastKey();
// Comparator access
Comparator<? super K> comparator();
}
这些方法与SortedSet中定义的方法基本类似,可以类比参照上一小节中对这些方法的介绍,这里不再进行过多描述。
三.实现
在讲完了Java集合框架中的基本接口后,现在我们来学习这些接口的实现。本文描述了以下几种实现:
- 通用实现——最常用的实现,专为日常使用而设计。
- 专用实现——专门为一些特殊场景设计,性能、限制或行为可能与通用实现不同。
- 并发实现——旨在支持高并发性。
- 包装实现——包装其他类型的实现(通常是通用实现),以增加或限制功能。
- 便捷实现——通常是通过静态工厂方法提供的迷你实现,为特殊集合(例如单例集)的实现提供方便、有效的替代方案。
- 抽象实现——可以理解为骨架实现,有助于方便、快速地构建自定义实现。
下面将依次对第二节中提到的接口的实现进行介绍。在介绍实现时,由于之前已经对各接口中定义的方法做了说明,因此不再重复阐述,只是描述各实现类的特点和注意事项。
1.Set实现
通用实现
Java平台中提供的Set接口的通用实现是HashSet、TreeSet和LinkedHashSet。HashSet将元素存在一个哈希表中,是性能最佳的实现,但是它不能保证迭代的顺序。TreeSet将元素存储在一个红黑树中,根据元素的值来进行排序,它比HashSet慢得多。LinkedHashSet同时具备了链表和哈希表的特点,使用链表来保存插入顺序,使用哈希表来快速定位元素,也就是说它的遍历顺序和插入顺序是一致的,但同时它的成本也是最高的。在实际使用过程中,可以灵活选择这几种Set。如果对遍历的顺序没有要求或者不需要遍历,可以选择HashSet;如果在遍历时需要按照元素的值进行排序,可以选择TreeSet;如果需要按照插入顺序遍历,可以选择LinkedHashSet。
实际上,有关这些实现类还有很多实现细节没有介绍。由于本系列是基础教程,因此不再过多深入。后续会推出阅读Java源码的系列,届时将会对Java中部分常用的类的源码进行详细介绍,敬请期待。
专用实现
Java提供了两个Set接口的专用实现——EnumSet和CopyOnWriteArraySet。
EnumSet是为枚举类型提供的高性能实现。EnumSet的所有成员必须具有相同的枚举类型。下面是EnumSet类中提供的构造EnumSet的工厂方法:
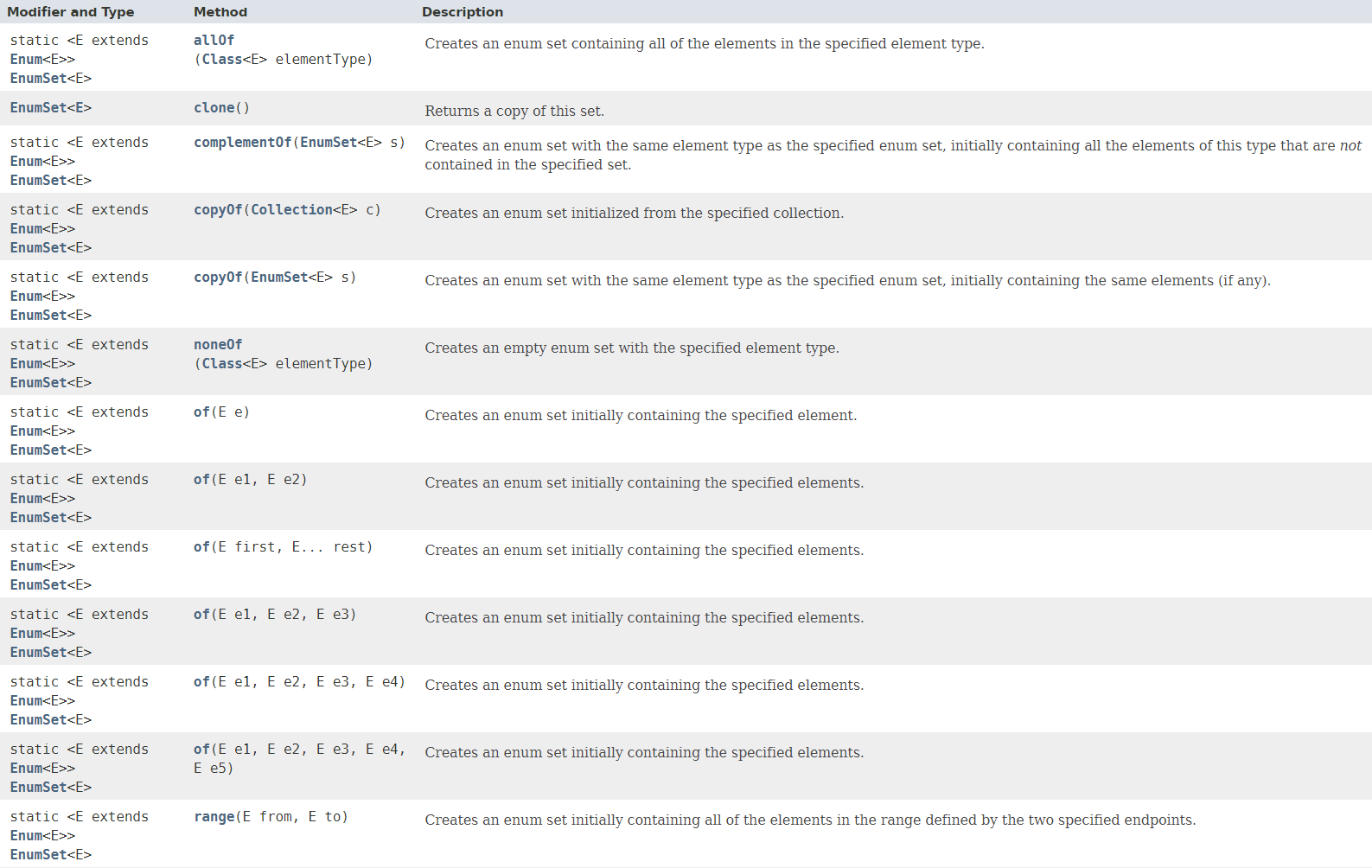
EnumSet内部维护了一个存储该枚举类型所有成员的数组,还有一个表示每个枚举成员是否存在于集合内的“位向量”,这个“位向量”可能是long也可能是long数组。因为每个枚举对象都有一个序号,因此位向量使用序号对应的位上的0或1来表示该对象是否存在于集合中。例如,现在我们有一个关于星期的枚举类型:
public enum Day {
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
}
我们使用of方法来创建一个EnumSet实例:
Set<Day> days = EnumSet.of(Day.TUESDAY, Day.FRIDAY);
那么对于这个EnumSet来说,它的位向量是下面这样的:

实际上,EnumSet是一个抽象类。java.util包中提供了它的两个子类,分别是RegularEnumSet和JumboEnumSet,RegularEnumSet使用一个long变量来表示位向量,而JumboEnumSet则使用long数组来表示位向量。在使用EnumSet的工厂方法构建实例时,它会自己选择使用哪个子类,而无需我们关心。
现在来看另外一个专用实现——CopyOnWriteArraySet。在介绍这个类之前,首先我们要了解一下CopyOnWrite的概念。这个术语的字面意思是在写的时候复制,实际上也是这么做的。在修改某个数据时,我们先拷贝一份副本,在副本上进行写操作,然后再替换之前的数据。这样可以避免在写数据时,因为加锁而造成其他读线程等待的情况。CopyOnWriteArraySet内部使用数组来保存元素,当对集合进行修改操作时(例如add、set或remove等),它会先将数组拷贝出一个副本,然后对这个副本进行操作,最后再将对原数组的引用指向新的数组。实际上,CopyOnWriteArraySet内部使用了下文中List接口的实现类CopyOnWriteArrayList来保存元素,而CopyOnWriteArrayList才是真正使用数组来实现的。
正是由于这个机制,CopyOnWriteArraySet具有以下特点:
- 它适用于读操作远远多于写操作的场景,因为写操作代价较高,它通常意味着复制整个底层数组;
- 它是线程安全的;
- 迭代器不支持remove操作;
- 读进程有可能读到的是过时的数据;
- 读写进程之间没有竞争,但是写进程之间还是需要加锁。
2.List实现
通用实现
Java集合框架中提供了两个List集合的通用实现——ArrayList和LinkedList。ArrayList内部使用数组实现,因此它的访问速度非常快。但正是由于它内部使用数组,因此在指定位置处添加或删除元素时需要移动后面所有的元素。需要注意的是,它并不是线程安全的。不过,可以使用Collections类的synchronizedList方法来将一个ArrayList转换为线程安全的对象。
如果需要频繁地在List的开头添加或删除元素并且元素的个数非常多时,则应考虑使用LinkedList。它是使用链表来实现的,因此它的添加和删除元素操作非常快。但正是由于链式结构,因此它的访问速度则需要花费线性时间。此外,LinkedList还实现了Deque,因此它支持Deque接口中定义的操作。
在使用List时,要充分考量程序的性能,来选择使用ArrayList还是LinkedList。一般来说,ArrayList更快。
专用实现
Java提供了两个List接口的专用实现——Vector和CopyOnWriteArrayList。
Vector是线程安全的List,并且它比经过Collections.synchronizedList处理过的ArrayList还要快一点。但是Vector中含有大量的遗留代码,毕竟它从Java1.0就开始存在了,当时还没有集合框架。从Java1.2开始,这个类被改进以实现List接口,使其成为Java集合框架的一员。因此,在使用Vector时,应该尽量使用List接口去操作。
CopyOnWriteArrayList的原理在上文中对CopyOnWriteArraySet的介绍中已经做了说明,这里不再赘述。
3.Map实现
通用实现
Map接口的三个通用实现分别是HashMap、TreeMap和LinkedHashMap。如果你想要最快的速度而不关心迭代顺序,请使用HashMap。如果需要SortMap操作或按键排序的迭代顺序,请使用TreeMap。如果需要接近HashMap的速度和按插入顺序迭代,请使用LinkedHashMap。这三个实现和Set接口中的三个通用实现非常类似。
虽然LinkedHashMap默认是按照插入顺序来排序,但是可以在构造LinkedHashMap实例时指定另外一种排序规则。这种规则按照最近对每个键值对的访问次数来排序,通过这种Map可以很方便地构建LRU缓存(Least Recently Used,一种缓存策略)。LinkedHashMap还提供了removeEldestEntry方法,通过覆盖该方法,可以定义何时删除旧缓存。例如,假如我们的缓存最多只允许100个元素,在缓存中的元素个数达到100个之后,每次添加新元素时都要清除旧元素,从而保持100个元素的稳定状态,可以像下面这样:
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
实际上,还有一个Map接口的通用实现——Hashtable(注意小写)。它也是从Java1.0开始就存在的一个“元老”。从Java1.2开始,它被改进以实现Map接口。它是线程安全的,但是由于效率较低,单线程时可以使用HashMap来代替,多线程时又可以使用下文中的ConcurrentHashMap来代替,因此这个类现在已经不再推荐使用。
专用实现
Java提供了三个Map接口的专用实现——EnumMap,WeakHashMap和IdentityHashMap。
EnumMap用在那些需要将枚举元素作为键的映射中,它的底层是使用数组来实现的。EnumMap是一个Map与枚举键一起使用的高性能实现。该实现将Map接口的丰富性和安全性与数组的速度相结合。如果要将枚举映射到值,则应始优先考虑EnumMap。
WeakHashMap只存储对其键的弱引用。JVM提供了四种类型的引用,分别是强引用、弱引用、软引用和虚引用,可以让程序员来决定某些对象的生命周期,有利于JVM进行垃圾回收。在进行垃圾回收时,若某个对象只具有弱引用,它一定会被回收。因此,当WeakHashMap中的键不再被外部引用时,JVM将会对它进行回收,该键值对也会消失。
IdentityHashMap在比较键时使用引用相等性代替对象相等性。在正常的Map实现中,当key1.equals(key2)返回true时,我们就认为这两个key是相等的;而在IdentityHashMap中,只有当key1==key2时,才认为这两个key是相等的。
并发实现
ConcurrentHashMap时Java提供的一个高并发、高性能的Map实现,它位于java.util.concurrent包中。这个实现在执行读操作时不需要加锁。因为这个类旨在作为Hashtable的替代品,因此,除了实现ConcurrentMap接口外(为线程安全Map定义的接口),它还保留了大量Hashtable中的遗留代码。因此,在使用ConcurrentHashMap时,应该尽量使用ConcurrentMap或Map接口去操作。
4.Queue实现
通用实现
Queue接口的通用实现包括LinkedList和PriorityQueue。
我们已经在List实现中介绍了LinkedList,为什么还要在Queue实现中再次提到它呢?这是因为LinkedList同时实现了List接口和Deque接口,而Deque接口又是Queue的子接口。因此,LinkedList可以算是List、Queue和Deque的实现。当我们使用不同的接口去引用LinkedList实例时,它就会表现出不同的行为。
PriorityQueue用来表示基于堆结构的优先级队列。它使用指定的排序规则来对元素进行排序,而不是按照队列默认的先进先出的顺序。在对PriorityQueue进行遍历时,迭代器不保证以任何特定顺序遍历优先级队列的元素。如果需要有序遍历,可以使用Arrays.sort(pq.toArray())。
并发实现
java.util.concurrent包中提供了一组Queue实现类,这些类都是线程安全的,因此可以在多线程中使用。这些类根据是否会阻塞线程可以分为两类:一类是非阻塞的,这里指的是ConcurrentLinkedQueue,它是使用链表实现的线程安全的队列;另一类是阻塞的,它们都实现了BlockingQueue接口,这个接口继承了Queue接口并且增加了一些额外的操作,支持当获取队列元素但是队列为空时,会阻塞等待队列中有元素再返回或超时返回;也支持添加元素时,如果队列已满,那么等到队列可以放入新元素时再放入或超时返回。
下表是BlockingQueue接口中操作元素的方法,除了继承自Queue接口的抛出异常和返回特定值的形式外,又增加了阻塞和超时两种形式:
下面是BlockingQueue接口的实现类:
- LinkedBlockingQueue——由链式节点实现的有界FIFO阻塞队列。
- ArrayBlockingQueue——由数组实现的有界FIFO阻塞队列。
- PriorityBlockingQueue——由堆实现的无界阻塞优先级队列。
- DelayQueue——支持延时获取元素的无界阻塞队列。
- SynchronousQueue——同步阻塞队列,无容量,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然。
此外,java.util.concurrent包中还定义了TransferQueue接口,它是BlockingQueue的子接口。在添加元素时,除了BlockingQueue中定义的方法,TransferQueue还定义了transfer和tryTransfer方法。transfer方法在传递元素时,若存在消费者,则立即将元素传递给消费者,否则将元素插入到队列尾部;tryTransfer方法在传递元素时,若存在消费者,则立即将元素传递给消费者,否则将元素插入到队列尾部,若在指定的时间内元素没有被消费者获取,则将该元素从队列中移除并返回false。TransferQueue接口有一个基于链式节点的无界实现——LinkedTransferQueue。
5.Deque实现
通用实现
Deque接口的通用实现包括LinkedList和ArrayDeque。ArrayDeque使用可调整大小的数组实现,而 LinkedList则是链表实现。
LinkedList允许null元素,而ArrayDeque则不允许。在效率方面,ArrayDeque比LinkedList两端的添加和删除操作更高效。LinkedList的最佳使用方式是在迭代期间删除元素。不过LinkedList并不是迭代的理想结构,并且它比ArrayDeque占用更多的内存。此外,无论是LinkedList还是ArrayDeque均不支持多个线程的并发访问。
并发实现
LinkedBlockingDeque类是Deque接口的并发实现。和BlockingQueue相同,它在获取双端队列元素但是队列为空时,会阻塞等待队列中有元素再返回或超时返回;也支持在双端添加元素时,如果队列已满,那么等到队列可以放入新元素时再放入或超时返回。
上面的LinkedBlockingDeque类是阻塞的,java.util.concurrent包中还定义了一个非阻塞的Deque接口实现类——ConcurrentLinkedDeque,它是使用链表实现的线程安全的双端队列。
6.包装实现
位于java.utils包中的Collections也是Java集合框架的一员,但它不是任意一种集合,而是一个包装类。它包含各种有关集合操作的静态方法,这个类不能实例化。它就像一个工具类,服务于集合框架。
这个类提供了很多的静态工厂方法,通过这些方法,可以提供具有某些特性的集合(例如空集合,同步集合,不可变集合等),或者包装指定的集合,使之具有某些特性。下面对这个类中的一些方法进行介绍。
同步包装器
同步包装器将自动同步(线程安全)特性添加到任意集合上。Collection,Set,List,Map,SortedSet和 SortedMap接口都有一个静态工厂方法。
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <T> List<T> synchronizedList(List<T> list);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s);
public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m);
每一个方法都会返回指定集合的包装对象,这个集合是线程安全的。所有对于集合的操作都应该通过这个集合来完成,保证这一点最简单的方法就是不再保留对原集合的引用。
面对并发访问,用户必须在迭代时手动同步返回的集合。这是因为迭代是通过对集合的多次访问来完成的,而返回的集合虽然是同步的,但是它只能保证每一次对集合的操作都是线程安全的,而不能保证对于几个的多次操作也是安全的,因此这些操作必须组成一个单独的原子操作。以下是迭代通过包装器返回的同步集合的习惯用法:
Collection<Type> c = Collections.synchronizedCollection(myCollection);
synchronized(c) {
for (Type e : c)
foo(e);
}
有关synchronized关键字和多线程的内容会在之后的文章中进行介绍。
不可变包装器
不可变包装器可以使集合变为不可变集合,从而具有只读属性,任何会对集合进行改变的操作都会抛出一个UnsupportedOperationException。与同步包装器一样,六个核心接口中的每一个都有一个静态工厂方法:
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c);
public static <T> Set<T> unmodifiableSet(Set<? extends T> s);
public static <T> List<T> unmodifiableList(List<? extends T> list);
public static <K,V> Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m);
public static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<? extends T> s);
public static <K,V> SortedMap<K, V> unmodifiableSortedMap(SortedMap<K, ? extends V> m);
为了保证集合的绝对不变性,应该在获取集合的不可变包装后,不再保留对原集合的引用。
7.便捷实现
本节描述了几种便捷实现,当您不需要集合的全部功能时,它们比通用实现更方便,更高效。本节中的所有实现都是通过静态工厂方法提供的。
数组的列表视图
Arrays.asList方法可以接受一个数组并返回该数组的列表视图。对于集合的改变会应用在数组上,反之亦然。集合的大小就是数组的大小且不能更改,如果再集合视图上调用可能会修改集合大小的方法将会抛出一个UnsupportedOperationException。
这个实现的一般用途是作为数组和集合之间的桥梁。它允许我们将数组传递给需要Collection或List的方法。这种实现还有一个用途,如果我们需要固定大小的List,它比任何通用实现都要高效:
List<String> list = Arrays.asList(new String[size]);
指定元素的集合
下面的方法可以根据指定的元素来创建集合:
- Arrays.asList(T... a)——返回包含指定的若干个元素的不可变List。
- Collections.nCopies(int n, T o)——返回包含n个指定元素o的不可变List(这些元素都是o的引用)。
- Collections.singleton(T o)——返回只包含该对象的不可变Set。
空集合或空映射
Collections类提供了返回空Set、List和Map的方法,它们分别是emptySet()、emptyList()和emptyMap()。
四.算法
本节中所有的算法都来自Collections类,这些算法绝大多数都以List实例作为参数,也有少部分是以Collection实例作为参数的。下面是这些算法:
- sort(List
list)——按照自然顺序对List进行排序。 - sort(List
list, Comparator<? super T> c)——根据指定的比较器对List进行排序。 - shuffle(List<?> list)——使用默认随机源打乱List元素顺序。
- shuffle(List<?> list, Random rnd)——使用指定随机源打乱List元素顺序。
- reverse(List<?> list)——反转List中的元素顺序。
- fill(List<? super T> list, T obj)——使用指定元素替换List中的所有元素。
- copy(List<? super T> dest, List<? extends T> src)——将src中的元素拷贝到dest中。dest的size要大于等于src的size。
- swap(List<?> list, int i, int j)——交换指定位置的元素。
- addAll(Collection<? super T> c, T... elements)——将若干元素添加到指定的Collection中。
- binarySearch(List<? extends Comparable<? super T>> list, T key)——使用二分搜索算法在List中查找指定元素。该List必须是按照升序排列,且使用自然顺序排序。
- binarySearch(List<? extends T> list, T key, Comparator<? super T> c)——使用二分搜索算法在List中查找指定元素。该List必须是按照升序排列。调用者需要提供比较器以用于在查找过程中进行比较。
- frequency(Collection<?> c, Object o)——返回指定元素在Collection中出现的次数。
- disjoint(Collection c1, Collection c2)——如果两个集合没有交集,返回true,否则返回false。
- min(Collection<? extends T> coll)或max(Collection<? extends T> coll)——返回根据自然顺序排列的最小值或最大值。
- min(Collection<? extends T> coll, Comparator<? super T> comp)或max(Collection<? extends T> coll, Comparator<? super T> comp)——返回根据指定比较器排列的最小值或最大值。
五.总结
到这里为止,关于Java集合框架的介绍就告一段落了。我们从接口、实现和算法三个层面了解了Java为我们提供的优秀的集合框架。考虑到本系列是基础教程,因此对于部分实现类的数据结构和实现细节没有进行过多地阐述。感兴趣的读者可以查阅其他资料或者尝试阅读源码,我之后也会在其他的系列中对部分重要的类的源码进行讲解,敬请期待。