本文仅用于学习与交流,不具有任何商业价值,如有问题,请与我联系,我将即时处理。
爬下某东数据,基于selenium。上代码:
1 """ 2 爬取某东数据并保存到csv 3 """ 4 import random 5 import time 6 7 from selenium import webdriver 8 import csv 9 10 keyWord = input('请输入你要搜索的内容:') 11 f = open(f'{keyWord}.csv', mode='a', encoding='utf-8-sig', newline='') 12 csvWriter = csv.writer(f) # 写入器 13 csvWriter.writerow(['标题','价格','评论数','店铺名','详情页']) # 写入表头 14 15 def dropDown(): 16 """ 17 网页页面下滑函数 18 :return: 19 """ 20 for x in range(1, 12, 2): # 步长为2进行计算 21 time.sleep(random.uniform(2, 5)) # 随机休眠 22 y = x / 9 # 23 # document.documentElement.scrollTop # 指定滚动条的位置 24 # document.documentElement.scrollHeight # 获取浏览器页面的最大高度 25 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % (y) 26 driver.execute_script(js) # 运行js语句 27 28 url = 'https://www.jx.com/' 29 # 定义浏览器 30 driver = webdriver.Chrome() 31 driver.maximize_window() # 最大化窗口 32 driver.implicitly_wait(10) # 隐式等待,等待页面加载完成 33 # 请求网址 34 driver.get(url=url) 35 # 找到搜索框并发送数据 36 driver.find_element_by_css_selector('#key').clear() # 找到搜索框并清楚搜索框内容 37 driver.find_element_by_css_selector('#key').send_keys(f'{keyWord}') # 找到搜索框并填入内容 38 driver.find_element_by_css_selector('#search > div > div.form > button').click() # 点击搜索按钮 39 # 搜索完后开始下滑页面加载当前页面所有数据 40 dropDown() 41 # 加载完后开始获取商品列表 42 lis = driver.find_elements_by_css_selector('.gl-item') # 找到商品列表iterable 43 for li in lis: 44 price = li.find_element_by_css_selector('.gl-i-wrap .p-price strong i').text # 价格 45 title = li.find_element_by_css_selector('.gl-item .p-name em').text # 标题 46 comment = li.find_element_by_css_selector('.p-commit strong a').text # 评论 47 shopName = li.find_element_by_css_selector('.p-shop span a').get_attribute('title') # 商家 48 detailPage = li.find_element_by_css_selector('.p-name a').get_attribute('href') # 详情页 49 50 print(title, price, comment, shopName, detailPage, sep=" | ") 51 # 保存到csv 52 csvWriter.writerow([title, price, comment, shopName, detailPage]) 53 54 f.close() # 关闭文档
没有翻页,太晚了,懒得翻页懒得等。
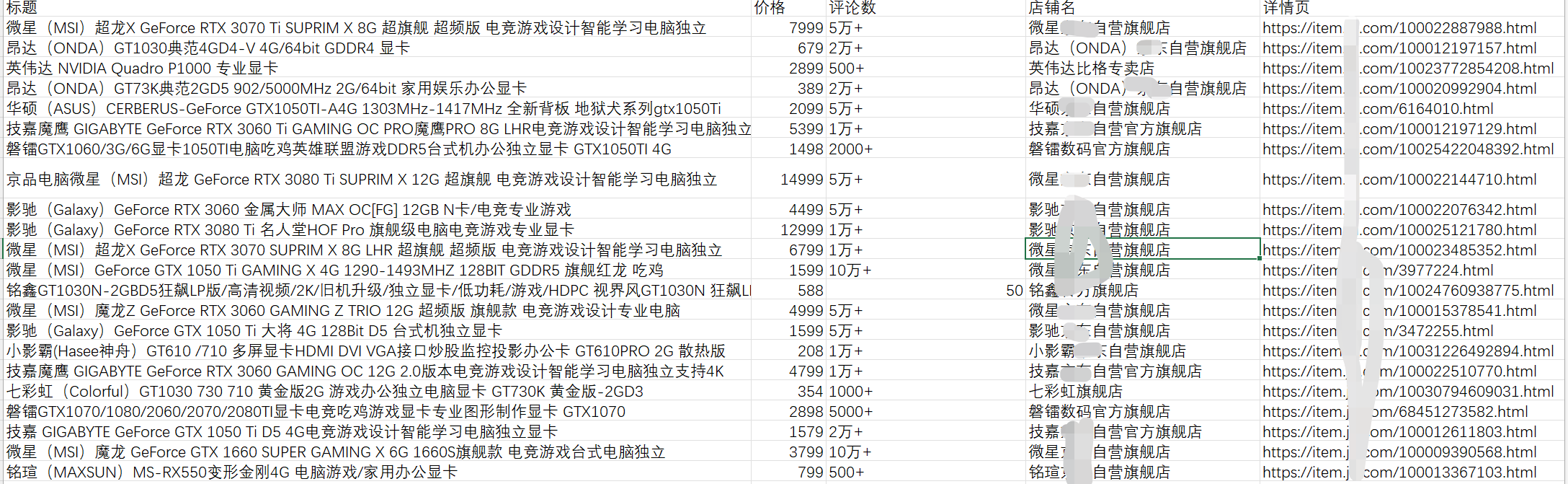
程序运行后结果截图: