Xpath在w3cschool有教程,传送门。Xpath是使用路径表达式来选去xml或者html的节点。常用的路径表达式如下:
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
保存着个表格,以便忘记的时候有这个地方可以查阅。在浏览器也可以装个插件叫做xpath-helper用来辅助xpath语法。
本文中所有的案例都会用到etree和parsel库,用来对比xpath语法,当然解析xpath的还有bs4,不过据说这个库6年没更新了,暂时先抛弃它。
第一个案例,爬取58同城二手房信息。
1 """ 2 几个简单的爬虫,巩固xpath 3 """ 4 import os.path 5 from lxml import etree 6 import requests 7 import parsel 8 import csv 9 10 class xpathSpider(): 11 headers = { 12 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36', 13 } 14 url = 'https://xm.58.com/ershoufang/' 15 def __init__(self, url, headers=headers): 16 self.url = url 17 self.headers = headers 18 19 def get_html(self): 20 response = requests.get(url=self.url, headers=self.headers) 21 # 返回原始的html文本 22 return response.text 23 24 def get_html_by_xpath_through_etree(self): 25 """ 26 利用lxml的etree解析html 27 """ 28 html_data = etree.HTML(self.get_html()) 29 # 接下来用xpath解析 30 results = html_data.xpath('//section[@class="list"]/div') # 用xpath解析找到所有的结果 31 for item in results: 32 # 标题 33 title = item.xpath('.//div[@class="property-content-title"]/h3/text()')[0].strip() # 其中括号中的点表示从当前节点开始选取,当前节点就是item节点,它是results节点的子节点 34 # 商圈或者说开发商 35 kaifashang = item.xpath('.//div[@class="property-content-info property-content-info-comm"]/p[1]/text()')[0].strip() 36 # 几室几厅 37 room = ''.join(item.xpath('.//p[@class="property-content-info-text property-content-info-attribute"]/*/text()')) # p标签下一级包括很多span标签,用*号取回所有文本 38 # 面积 39 area = item.xpath('.//section/div/p[2]/text()')[0].strip() # 选中面积,里面的p[2]是room里的p[1]是同级节点 40 # 总价格 41 totalPrice = ''.join(item.xpath('.//div[@class="property-price"]/p[1]/*/text()')) 42 # 单价 43 perPrice = item.xpath('.//div[@class="property-price"]/p[2]/text()')[0].strip() 44 # 地址 45 address = '-'.join(item.xpath('.//section/div[@class="property-content-info property-content-info-comm"]/p/*/text()')) 46 self.saveToCsv(title, kaifashang, room, area, totalPrice, perPrice, address) 47 48 def get_html_by_xpath_through_pasel(self): 49 """ 50 方法不止一种,再用parsel库来解析一下,有对比才有伤害,与etree不同的是,parsel库支持直接提取文本 51 """ 52 html_data = self.get_html() 53 # 开始解析 54 selector = parsel.Selector(html_data) 55 # 获取到结果 56 results = selector.xpath('//section[@class="list"]/div') 57 for item in results: 58 # 标题 59 title = item.xpath('.//div[@class="property-content-title"]/h3/text()').get().strip() # 其中括号中的点表示从当前节点开始选取,当前节点就是item节点,它是results节点的子节点 60 # 商圈或者说开发商 61 kaifashang = item.xpath('.//div[@class="property-content-info property-content-info-comm"]/p[1]/text()').get() 62 # 几室几厅 63 room = ''.join(item.xpath('.//p[@class="property-content-info-text property-content-info-attribute"]/*/text()').getall()) # p标签下一级包括很多span标签,用*号取回所有文本 64 # 面积 65 area = item.xpath('.//section/div/p[2]/text()').get().strip() # 选中面积,里面的p[2]是room里的p[1]是同级节点 66 # 总价格 67 totalPrice = ''.join(item.xpath('.//div[@class="property-price"]/p[1]/*/text()').getall()) 68 # 单价 69 perPrice = item.xpath('.//div[@class="property-price"]/p[2]/text()').get().strip() 70 # 地址 71 address = '-'.join( 72 item.xpath('.//section/div[@class="property-content-info property-content-info-comm"]/p/*/text()').get()) 73 print(title, kaifashang, room, area, totalPrice, perPrice, address, sep=" | ") 74 75 def create_csv(self): 76 """ 77 创建一个csv文档 78 """ 79 csvFile = open('58同城二手房etree-xpath.csv', mode='w+', encoding='utf-8-sig', newline='') 80 csvWriter = csv.writer(csvFile) 81 csvWriter.writerow(['标题', '开发商', '厅室', '面积', '总价', '单价', '地址']) # 表头只要写一次 82 csvFile.close() 83 84 def saveToCsv(self, title, kaifashang, room, area, totalPrice, perPrice, address): 85 # 如果要实现翻页爬取,必须用a+模式, 86 with open('58同城二手房etree-xpath.csv', mode='a+', encoding='utf-8-sig', newline='') as f: 87 csvWriter = csv.writer(f) 88 csvWriter.writerow([title, kaifashang, room, area, totalPrice, perPrice, address]) 89 90 def run(self): 91 self.get_html_by_xpath_through_etree() # 因为把保存的程序写到这个下面了,直接调用运行 92 93 if __name__ == "__main__": 94 for page in range(1, 10): 95 url = f'https://xm.58.com/ershoufang/p{page}/' 96 app = xpathSpider(url=url) 97 # 这里判定文件存在不存在,如果不存在,就调用方法运行一次,如果多页爬取的时候,每次都调用的话,每次都会创建文件,这不是需要的 98 if not os.path.exists('58同城二手房etree-xpath.csv'): 99 app.create_csv() 100 app.run()
第二个案例,爬取图片进行保存。
1 """ 2 第二个图片案例 3 """ 4 import os.path 5 import time 6 import requests 7 from lxml import etree 8 import parsel 9 10 class picXpathSpider(): 11 headers = { 12 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36', 13 } 14 def __init__(self, url, headers=headers): 15 self.url = url 16 self.headers = headers 17 18 def get_html(self): 19 response = requests.get(url=self.url, headers=self.headers) 20 response.encoding = response.apparent_encoding 21 response.encoding = 'gbk' 22 return response.text 23 24 def get_content_by_xpath(self): 25 picnames = [] 26 picurls = [] 27 html_data = self.get_html() 28 selector = etree.HTML(html_data) 29 pictures = selector.xpath('//div[@class="slist"]/ul/li') 30 for item in pictures: 31 picname = item.xpath('.//a/b/text()')[0] # 取第一项 32 picnames.append(picname) 33 imgurl = item.xpath('.//a/img/@src')[0] # 取第一项 34 imgurl = 'https://pic.netbian.com/' + str(imgurl) 35 picurls.append(imgurl) 36 # print(picname, imgurl, sep=' | ') 37 return zip(picnames, picurls) 38 39 def get_content_by_parsel(self): 40 picnames = [] 41 picurls = [] 42 html_data = self.get_html() 43 selector = parsel.Selector(html_data) 44 results = selector.xpath('//div[@class="slist"]/ul/li') # 选中需要的结果 45 for item in results: 46 picname = item.xpath('.//a/b/text()').get() # 取第一项 47 picnames.append(picname) 48 imgurl = item.xpath('.//a/img/@src').get() # 取第一项 49 imgurl = 'https://pic.netbian.com/' + str(imgurl) 50 picurls.append(imgurl) 51 print(picname, imgurl, sep=' | ') 52 return zip(picnames, picurls) 53 54 def saveImg(self): 55 imginfo = self.get_content_by_xpath() 56 for picname, picurl in imginfo: 57 with open('images\\' + picname + '.' + picurl.split('.')[-1], mode='wb') as f: 58 f.write(requests.get(url=picurl, headers=self.headers).content) 59 print(picname + f'在-----{time.strftime("%H:%M:%S", time.localtime())}---------保存完毕!') 60 61 if __name__ == "__main__": 62 if not os.path.exists('images\\'): 63 os.mkdir('images\\') 64 for page in range(1, 10+1): 65 if page == 1: 66 url = 'https://pic.netbian.com/4kmeinv/' 67 else: 68 url = f'https://pic.netbian.com/4kmeinv/index_{page}.html' 69 print(f'******************正在爬取----第{page}页数据----!******************') 70 app = picXpathSpider(url=url) 71 app.saveImg()
程序运行截图:

程序运行完毕保存的图片截图:
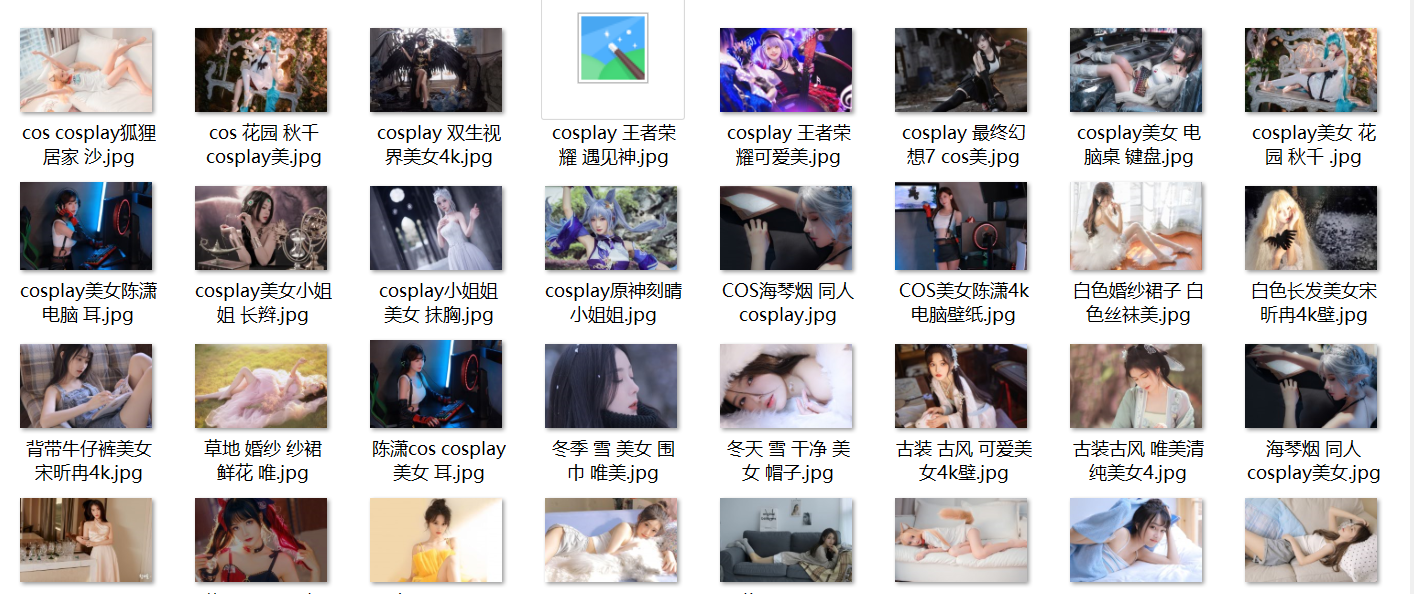
第三个案例:爬取某网站的所有城市名。
要爬取的网页截图如下:
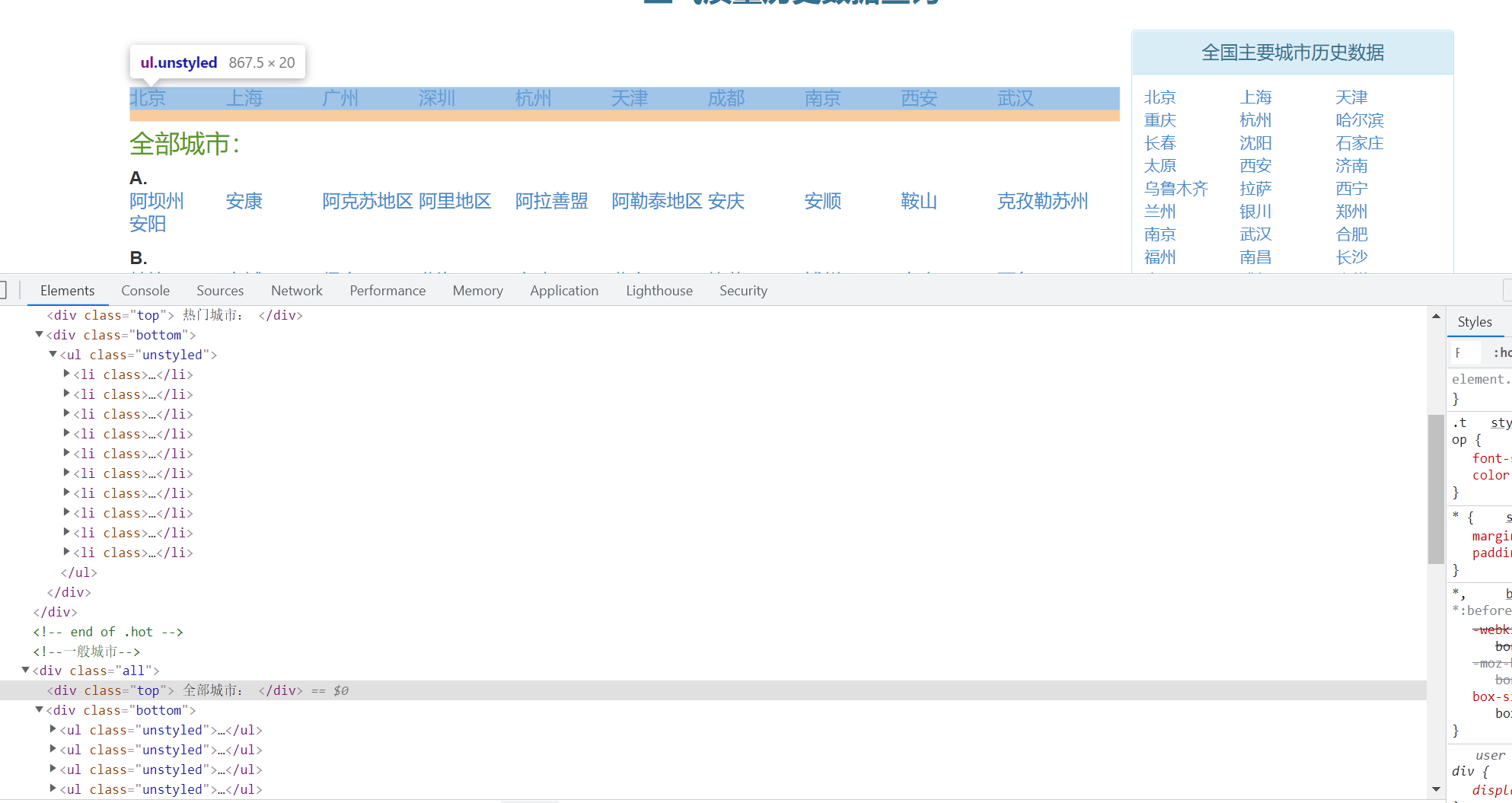
也就是要爬取热门城市和全部城市下的所有城市名,他们分别属于不同的div标签,可以分开爬取,也可以一次性爬取。用到xpath的运算符"|"。如果//book | //cd, 表示返回所有用book元素和cd元素的集合。
1 """ 2 第三个案例,爬取某网站的热门城市 3 """ 4 import parsel 5 import requests 6 from lxml import etree 7 8 class cityNameSpider(): 9 headers = { 10 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36', 11 } 12 13 def __init__(self, url, headers=headers): 14 self.url = url 15 self.headers = headers 16 17 def get_html(self): 18 response = requests.get(url=self.url, headers=self.headers) 19 if response.status_code == 200: 20 return response.text 21 else: 22 print('请求失败!') 23 24 # 第一种方法使用lxml的etree进行解析 25 def parse_html_by_etree1(self): 26 # 一股脑儿全部爬取 27 cityNamesAll = [] 28 html_text = self.get_html() 29 selector = etree.HTML(html_text) 30 # 热门城市 //div[@class="bottom"]/ul/li 31 # 所有城市 //div[@class="bottom"]/ul/div[2]/li 32 lis = selector.xpath('//div[@class="bottom"]/ul/li | //div[@class="bottom"]/ul/div[2]/li') 33 for li in lis: 34 cityName = li.xpath('.//a/text()')[0] 35 cityNamesAll.append(cityName) 36 # print(cityName) 37 # print(len(cityNamesAll)) # 399 38 return cityNamesAll 39 40 def parse_html_by_etree2(self): 41 # 分开爬取热门城市名和所有城市名 42 cityNamesSep = [] 43 html_text = self.get_html() 44 selector = etree.HTML(html_text) 45 hotcitylis = selector.xpath('//div[@class="bottom"]/ul/li') 46 for hotcity in hotcitylis: 47 cityName = hotcity.xpath('.//a/text()')[0] 48 cityNamesSep.append(cityName) 49 allcities = selector.xpath('//div[@class="bottom"]/ul/div[2]/li') 50 for othercity in allcities: 51 otherCityName = othercity.xpath('.//a/text()')[0] 52 cityNamesSep.append(otherCityName) 53 # print(len(cityNamesSep)) # 399 54 return cityNamesSep 55 56 # 第二种方式使用parsel库进行解析 57 def parse_html_by_parsel1(self): 58 cityNamesAll = [] 59 html_text = self.get_html() 60 selector = parsel.Selector(html_text) 61 lis = selector.xpath('//div[@class="bottom"]/ul/li | //div[@class="bottom"]/ul/div[2]/li') 62 for li in lis: 63 cityName = li.xpath('.//a/text()').get() 64 cityNamesAll.append(cityName) 65 # print(cityNamesAll) 66 return cityNamesAll 67 68 def parse_html_by_parsel2(self): 69 cityNamesSep = [] 70 html_text = self.get_html() 71 selector = parsel.Selector(html_text) 72 hotCitylis = selector.xpath('//div[@class="bottom"]/ul/li') 73 for hotcity in hotCitylis: 74 hotCity = hotcity.xpath('.//a/text()').get() # 获取文本 75 cityNamesSep.append(hotCity) 76 otherCityLis = selector.xpath('//div[@class="bottom"]/ul/div[2]/li') 77 for othercity in otherCityLis: 78 otherCity = othercity.xpath('.//a/text()').get() 79 cityNamesSep.append(otherCity) 80 # print(cityNamesSep) 81 return cityNamesSep 82 83 def saveTotxt(self): 84 f = open('城市名.txt', mode='w+', encoding='utf-8') 85 # 保存到txt文档,随便上面哪一种方法 86 cityNames = self.parse_html_by_etree1() 87 count = 0 88 for cityname in cityNames: 89 f.write(cityname + ', ') 90 count += 1 91 if count == 10: 92 count = 0 # 循环内从头开始计数 93 f.write('\n') # 每10个写一个换行符 94 print('保存完毕!') 95 96 def run(self): 97 self.saveTotxt() 98 99 if __name__ == "__main__": 100 url = 'https://www.aqistudy.cn/historydata/' 101 app = cityNameSpider(url=url) 102 # print(app.parse_html_by_etree1() == app.parse_html_by_etree2()) # True 103 # print(app.parse_html_by_parsel1() == app.parse_html_by_parsel2()) # True 104 app.saveTotxt()
程序运行完截图:
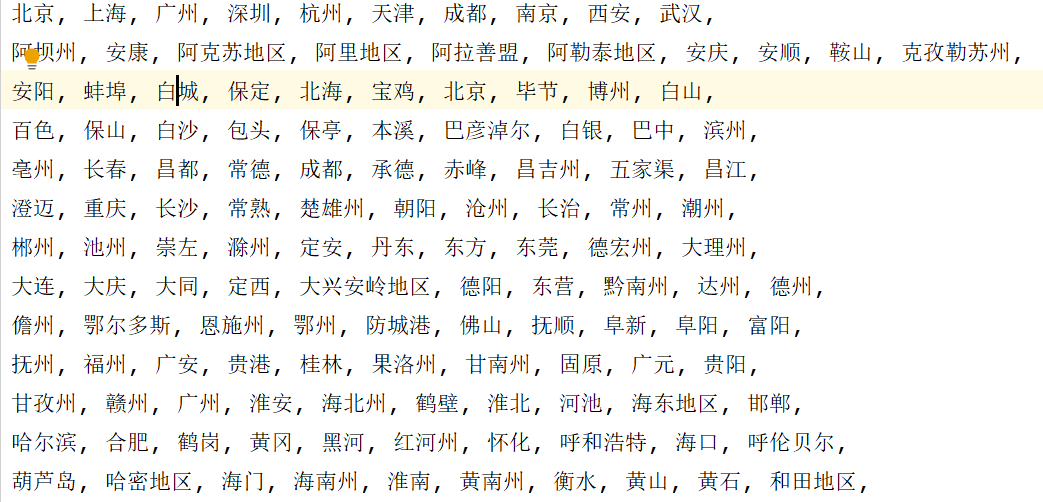
第四个案例,来个虎牙小姐姐的视频爬取。
1 """ 2 虎牙小姐姐视频爬取 3 """ 4 import os.path 5 import pprint 6 import random 7 import re 8 import time 9 import requests 10 from lxml import etree 11 import parsel 12 13 def change_tilte(title): 14 # 一个函数,可以替换特殊字符 15 pattern = re.compile(r'[\/\\\:\*\?\"\<\>\|]') 16 new_title = re.sub(pattern, '', title) 17 return new_title 18 19 class huyaVideoSpider(): 20 headers = { 21 'cookie': '', 22 'referer': 'https://v.huya.com/g/Dance?set_id=31', 23 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36', 24 } 25 def __init__(self, url, headers=headers): 26 self.url = url 27 self.headers = headers 28 29 def get_html(self): 30 response = requests.get(url=self.url, headers=self.headers) # 请求 31 # print(response.text) 32 return response.text # 返回值 33 34 def parse_html_by_etree(self): 35 videoIds = [] 36 html_text = self.get_html() 37 selector = etree.HTML(html_text) 38 results = selector.xpath('//section/ul[2]/li') 39 # print(results) 40 for item in results: 41 videoPlayUrl = item.xpath('./a/@href')[0] # 取到第一项 42 videoId = re.findall('\d+', videoPlayUrl)[0] # 取到第一项 43 videoIds.append(videoId) 44 return videoIds 45 46 def parse_html_by_parsel(self): 47 videoIds = [] 48 html_text = self.get_html() 49 selector = parsel.Selector(html_text) 50 results = selector.xpath('//section/ul[2]/li') 51 for item in results: 52 # 这里只需要提取到id就可以了 53 videoPlayUrl = item.xpath('.//a/@href').get() 54 videoId = re.findall('\d+', videoPlayUrl) # 从播放地址把id提取出来 55 videoIds.append(videoId) 56 return videoIds 57 58 def request_content_url(self): 59 videoTitles = [] 60 videoQualities = [] 61 downLoadUrls = [] 62 videoIds = self.parse_html_by_etree() 63 for videoId in videoIds: 64 json_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={videoId}&_=1641628611850' 65 # 请求json_url 66 res = requests.get(url=json_url, headers=self.headers) 67 needResults = res.json()['data']['moment']['videoInfo']['definitions'] # list 68 title = res.json()['data']['moment']['title'] # 视频标题 69 videoTitles.append(title) # 添加到列表 70 downLoadUrl = needResults[0]['url'] 71 downLoadUrls.append(downLoadUrl) # 将url添加到列表 72 videoQuality = needResults[0]['defName'] # 画质 73 videoQualities.append(videoQuality) 74 return zip(videoTitles, videoQualities, downLoadUrls) 75 76 # def make_dir(self): 77 # dirForSave = 'huyaVideo\\' 78 # if not os.path.exists(dirForSave): 79 # os.mkdir(dirForSave) 80 81 def download_video(self): 82 # 开始下载视频 83 videoInfos = self.request_content_url() 84 for videoTitle, videoQuality, videoUrl in videoInfos: 85 videoTitle = change_tilte(videoTitle) # 以防万一,替换一些特殊字符,windows有些特殊字符是不能出现在标题里的 86 with open('huyaVideo\\' + videoTitle + '--' + videoQuality + '.mp4', mode='wb') as f: 87 f.write(requests.get(url=videoUrl, headers=self.headers).content) 88 print(videoTitle + f'-----于----->{time.strftime("%H:%M:%S", time.localtime())}---保存完毕!') 89 90 def run(self): 91 self.download_video() 92 93 if __name__ == "__main__": 94 filePath = 'huyaVideo\\' 95 if not os.path.exists(filePath): 96 os.mkdir(filePath) 97 for page in range(1, 10 + 1): 98 # 爬10页吧,没多线程,视频爬不动 99 if page == 1: 100 url = 'https://v.huya.com/g/Dance_most_31' 101 else: 102 url = f'https://v.huya.com/g/Dance?set_id=31&order=mostplay&page={page}' 103 print(f'----------------------正在爬取{page}页内容,请稍后。。。。。。。。。。。。。。。。。。') 104 time.sleep(random.uniform(2, 5)) 105 app = huyaVideoSpider(url=url) 106 app.run()
程序运行截图:

保存的视频截图:
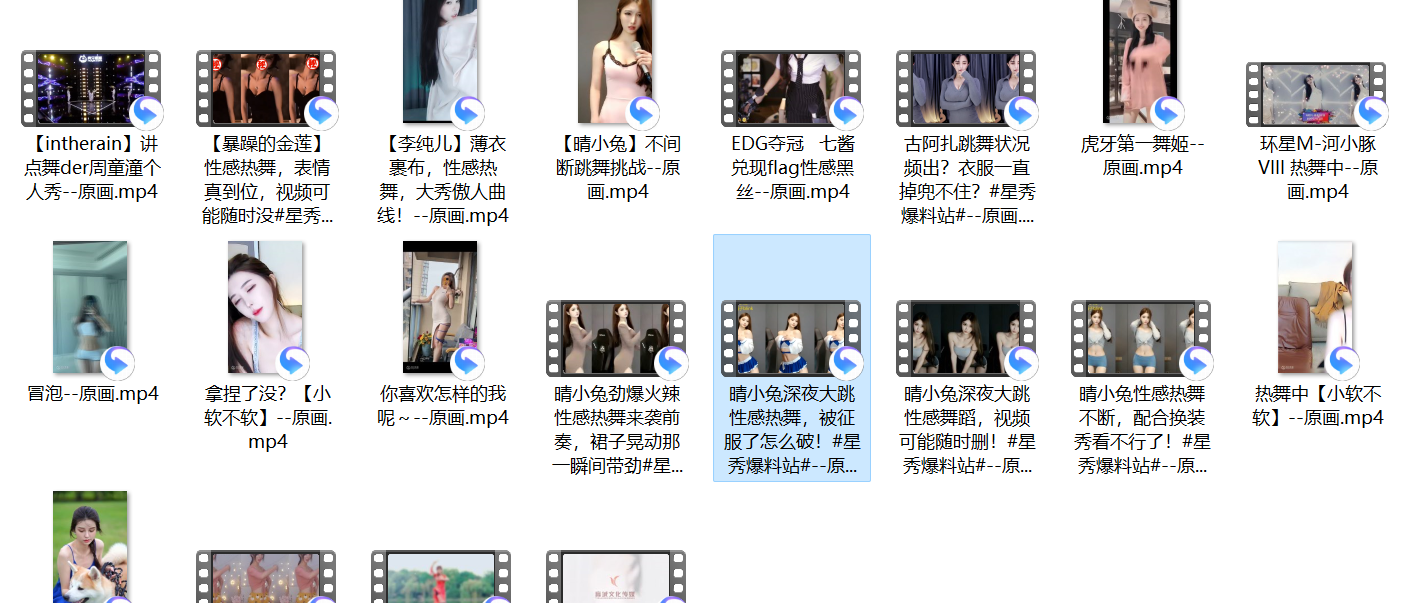
爬完后发现哎呀妈呀,这么多卖肉的女主播,建议小孩子不要去看女的直播,又他瞄的是美颜啊,又他瞄的露这露那,去做J的不是更好?真的是恶心。毁三观。。
第五个案例, 爬取酷狗的榜单和歌曲单。
1 """ 2 酷狗音乐 3 """ 4 import requests 5 from lxml import etree 6 import parsel 7 8 9 class kugouMusicSpider(): 10 """ 11 一个类,抓两个页面的xpath,一个是榜单,一个是榜单歌曲 12 """ 13 headers = { 14 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36', 15 } 16 17 def __init__(self, url, headers=headers): 18 self.url = url 19 self.headers = headers 20 21 def get_html(self): 22 response = requests.get(url=self.url, headers=self.headers) 23 response.raise_for_status() 24 response.encoding = response.apparent_encoding 25 response.encoding = 'utf-8' 26 return response.text 27 28 # 解析榜单页面的xpath 29 def parse_rank_list_by_etree(self): 30 # 通过etree获取榜单名和榜单地址 31 rankListTitles = [] 32 rankListUrls = [] 33 html_data = self.get_html() 34 selector = etree.HTML(html_data) 35 # 这里的div标签的class属性是class="pc_rank_sidebar pc_rank_sidebar_first",选取一部分 36 rankList = selector.xpath('//div[contains(@class, "pc_rank_sidebar")]/ul/li') 37 # 如果是不包含的话就是//div[not(contains(@class, "pc_rank_sidebar"))] 38 for item in rankList: 39 rankListTitle = item.xpath('.//a/@title')[0] # 取第一项 40 rankListTitles.append(rankListTitle) 41 rankListUrl = item.xpath('.//a/@href')[0] # 这个url用来抓取歌曲的xpath 42 rankListUrls.append(rankListUrl) 43 # print(rankListTitle) 44 return zip(rankListTitles, rankListUrls) 45 def parse_rank_list_by_parsel(self): 46 # 通过parsel获取榜单名和榜单地址 47 rankListTitles = [] 48 rankListUrls = [] 49 html_data = self.get_html() 50 selector = parsel.Selector(html_data) 51 rankList = selector.xpath('//div[contains(@class, "pc_rank_sidebar")]/ul/li') 52 for item in rankList: 53 rankListTitle = item.xpath('./a/@title').get() # 榜单标题 54 rankListUrl = item.xpath('./a/@href').get() # 榜单url 55 rankListTitles.append(rankListTitle) 56 rankListUrls.append(rankListUrl) 57 return zip(rankListTitles, rankListUrls) 58 59 # 开始解析歌曲页面的xpath,获取歌曲名和播放页面地址 60 def parse_music_page_by_etree(self): 61 # 通过etree获取歌曲页面的歌曲标题和歌曲播放地址 62 info = self.parse_rank_list_by_etree() 63 for rankListTitle, rankListUrl in info: 64 response = requests.get(url=rankListUrl, headers=self.headers) 65 selector = etree.HTML(response.text) 66 musciLis = selector.xpath('//div[contains(@class, "pc_temp_songlist")]/ul/li') 67 for item in musciLis: 68 musicName = item.xpath('.//a/@title')[0] 69 musicUrl = item.xpath('.//a/@href')[0] 70 print(musicName, musicUrl, sep=" | ") 71 break 72 def parse_musci_page_by_parsel(self): 73 # 通过parsel获取歌曲页面的歌曲标题和歌曲播放地址 74 info = self.parse_rank_list_by_parsel() 75 for rankListTitle, rankListUrl in info: 76 response = requests.get(url=rankListUrl, headers=self.headers) 77 selector = parsel.Selector(response.text) 78 musicLis = selector.xpath('//div[contains(@class, "pc_temp_songlist")]/ul/li') 79 for item in musicLis: 80 musicName = item.xpath('.//a/@title').get() 81 musicUrl = item.xpath('.//a/@href').get() 82 print(musicName, musicUrl, sep=' | ') 83 84 if __name__ == "__main__": 85 url = 'https://www.kugou.com/yy/html/rank.html' 86 app = kugouMusicSpider(url=url) 87 app.parse_musci_page_by_parsel()