周旭龙前辈的Hadoop学习笔记—网站日志分析项目案例简明、经典,业已成为高校大数据相关专业的实验项目。上周博主也完成了这个实验,不同于周前辈使用特殊符号切割字符串得到数据的做法,博主使用了正则表达式来匹配数据。在此将我的思路及代码张贴出来,以供后来者学习借鉴。
一、数据情况分析
1.1、数据格式概览
本次实验数据来自于国内某论坛,数据以行为单位,每行记录由5部分组成,访问者IP、访问时间、访问资源、访问状态、访问流量。

1.2、所需的数据
按照实验教程,我们只需要IP、时间、uri即可,不过本着既能完成实验,又能锻炼锻炼的想法,我把发个文状态以及访问流量也提取了出来。
1.3、上传数据至HDFS
本次试验到手的数据大小为60MB,约60万行。数据量较小,因此直接使用shell命令上传至HDFS。


注:欲知更详细的项目背景,请点击Hadoop学习笔记—网站日志分析项目案例(一)项目介绍__周旭龙_博客园
二、数据清洗准备
2.1、日志解析类
将解析日志信息的功能抽象成为一个日志解析类,分别解析各字段信息。
2.1.1 各字段的正则表达式
IP位于行的开头,因此定位到行起始位置,向右读取字符,直到遇到空格。又因为一个有效的IP最少为四个数字+三个符号,7位;最大为3*4+3,15位。所以行起始处7~15位为IP。表达式为:'^S{7,15}'
时间位于一个方括号内,直接提取方括号内的数据即可:'[.*?]'
URI及其相关数据与时间数据位置类似,都在成对符号之内,因此可用相同的解法将其提取出来,再做下一步分析:'".*?"'
状态码只有三位数,且两边都是空格,可以吧两边的空格也提出来,再去掉:' d{3} '
流量在行尾,也都是数字:'d{1,6}$'
2.1.2 函数
除了一个parse函数以及五个分别处理字段的函数外,正则表达式匹配也抽象成了一个函数。需要注意的是匹配是否为空,以及匹配uri并将其分割为数组后下标取值是否越界。
-
public class parseLine {
-
-
public String[] parse(String line)
-
{
-
String ip = parseIP(line);
-
String time = parseTime(line);
-
String url = parseURL(line);
-
String status = parseStatus(line);
-
String traffic = parseTraffic(line);
-
-
return new String[] {ip,time,url,status,traffic};
-
}
-
-
private String parseReg(String reg,String str)
-
{
-
Pattern pat = Pattern.compile(reg);
-
Matcher matcher = pat.matcher(str);
-
boolean rs = matcher.find();
-
if(rs)
-
return matcher.group(0);
-
else
-
return "null";
-
}
-
-
private String[] splitUrl(String str)
-
{
-
String []urlInfo = str.substring(1, str.length()-1).split(" ");
-
return urlInfo;
-
}
-
-
private String parseTraffic(String line) {
-
String reg_ip = "\d{1,6}$";
-
return parseReg(reg_ip,line);
-
}
-
-
private String parseStatus(String line) {
-
String reg_ip = " \d{3} ";
-
return parseReg(reg_ip,line).trim();
-
}
-
-
private String parseURL(String line) {
-
String reg_ip = "".*?"";
-
String str = parseReg(reg_ip,line);
-
String[] urlInfo = splitUrl(str);
-
-
return urlInfo[1];
-
}
-
-
private String parseTime(String line) {
-
String reg_ip = "\[.*?\]";
-
String str = parseReg(reg_ip,line);
-
SimpleDateFormat in=new SimpleDateFormat("[dd/MMM/yyyy:HH:mm:ss ZZZZZ]",Locale.US);
-
SimpleDateFormat out=new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
-
Date d = new Date();
-
try
-
{
-
d=in.parse(str);
-
}
-
catch (ParseException e)
-
{
-
e.printStackTrace();
-
}
-
return out.format(d).trim();
-
}
-
-
private String parseIP(String line) {
-
String reg_ip = "^\S{7,15}";
-
return parseReg(reg_ip,line);
-
}
-
}
2.2、Mapper类
map阶段的输入为<偏移量,一行文本>,输出为<偏移量,处理后的数据>。再这个类中,对数据的有效性判断也在这儿,博主只过滤了静态数据。
-
public class logMap extends Mapper<LongWritable,Text,LongWritable,Text>{
-
static parseInfo parseLine = new parseInfo();
-
protected void map(LongWritable key1,Text value1,Context context) throws IOException,InterruptedException
-
{
-
String str1 = value1.toString();
-
Text output = new Text();
-
-
final String[] info = parseLine.parse(str1);
-
-
if(info[2].startsWith("/static") || info[2].startsWith("/uc_server"))
-
return ;
-
-
StringBuilder result = new StringBuilder();
-
for(String x:info)
-
result.append(x).append(" ");
-
-
output.set(result.toString());
-
context.write(key1, output);
-
}
-
}
2.3、Reducer类
reduce阶段的输入与map的输出有关,为<偏移量,处理后数据的集合>,输出则为<处理后的数据,空>。
-
public class logReducer extends Reducer<LongWritable,Text,Text,NullWritable>{
-
protected void reduce(LongWritable k3,Iterable<Text> v3,Context context) throws IOException,InterruptedException{
-
for(Text v3s : v3)
-
context.write(v3s, NullWritable.get());
-
}
-
}
2.4、主函数
-
public class logMain {
-
-
public static void main(String[] args) throws Exception{
-
Job job = Job.getInstance(new Configuration());
-
job.setJarByClass(logMain.class);
-
-
job.setMapperClass(logMap.class);
-
job.setMapOutputKeyClass(LongWritable.class);
-
job.setMapOutputValueClass(Text.class);
-
-
job.setReducerClass(logReducer.class);
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(NullWritable.class);
-
-
FileInputFormat.setInputPaths(job, new Path(args[0]));
-
FileOutputFormat.setOutputPath(job, new Path(args[1]));
-
-
job.waitForCompletion(true);
-
}
-
-
}
三、数据清洗
将编写好的MR到处导出为jar包后,在hadoop中用小规模的测试用例试运行,成功后再用实验数据。
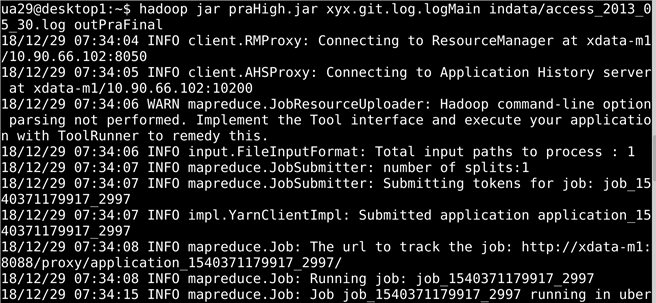
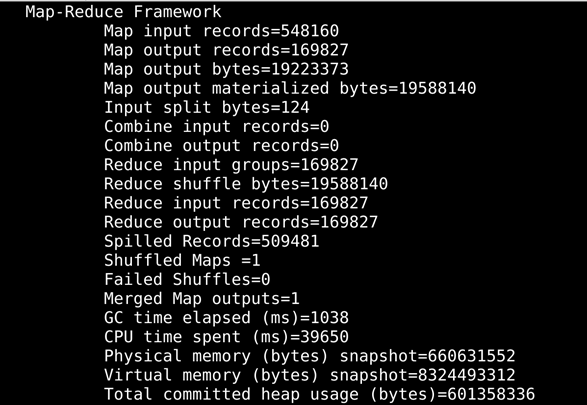
结果如下:
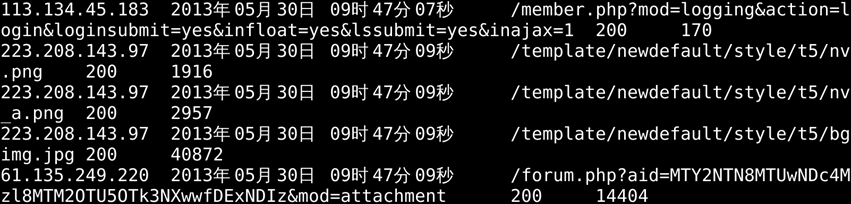
注:完整项目
Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍