一、网页分析
1.1 关键字页面(url入口)
首先在前程无忧网站上检索关键词"大数据":
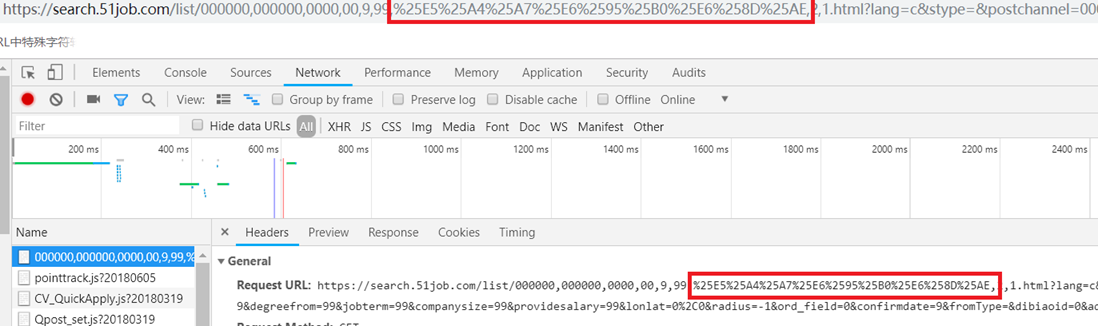
跳转到如下url: https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
在这个url中,'%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE'很明显为某种编码格式,我们知道'大数据'的UTF-8为'E5A4A7 E695B0 E68DAE',加上'%'变为16进制编码,即'%E5%A4%A7%E6%95%B0%E6%8D%AE',这'25'又是什么鬼?百度得到到关键词'二次编码',%25的url编码即为符号'%',所以'%25E5'即为'%E5'。不过我好奇的是,既然'%'已经是URI中的特殊转义字符,为啥还要多此一举地进行二次编码呢。再查,发现'%'在URI中可能会引起程序解析的歧义,百分号本身就用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码。
做一个实验,我们将该url截取下来,用'销售'中文的utf-8编码代替其中的编码,看看发生了什么。

再回过头去看在网站入口搜索框进去的'大数据'页面:
这是二次编码过的,再在url里改成中文名:

好吧,二次编码与否并不影响效果。
接下来来比较不同页数URL之间的联系。提取'大数据'关键词前三页url:
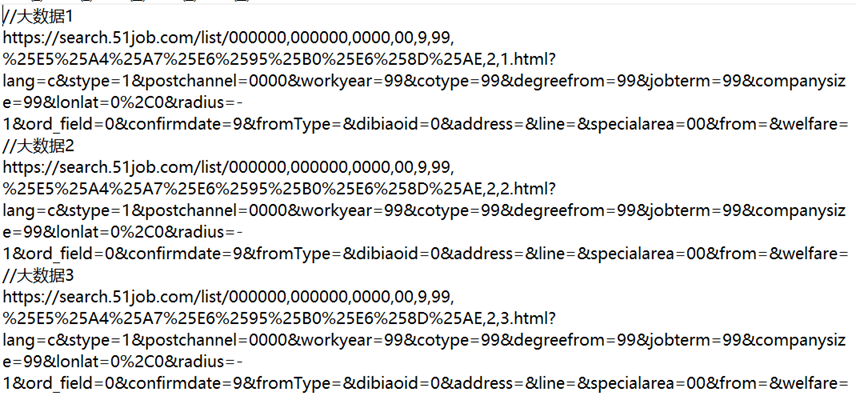
将前两页进行对比:

只有一个符号不同,再比较二、三页:

也是一个数字的差异,改数字即为页码。所以对于页数url我们可以得出如下结论:
'https://search.51job.com/list/000000,000000,0000,00,9,99,关键词 ,2,页数.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
因此入口url模块代码如下:
-
if __name__ == '__main__':
-
key = '销售'
-
urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,'+ key + ',2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(i) for i in range(1,50)]
-
for url in urls:
-
getUrl(url)
1.2 岗位详情url
由于我们需要的是岗位详情页面的信息,所以我们要找出页面所有岗位的url。
打开开发者工具,找到岗位名称所在标签,在属性里发现了该页面的url:

又发现每一条招聘信息都在<div class="el">…</div>里:
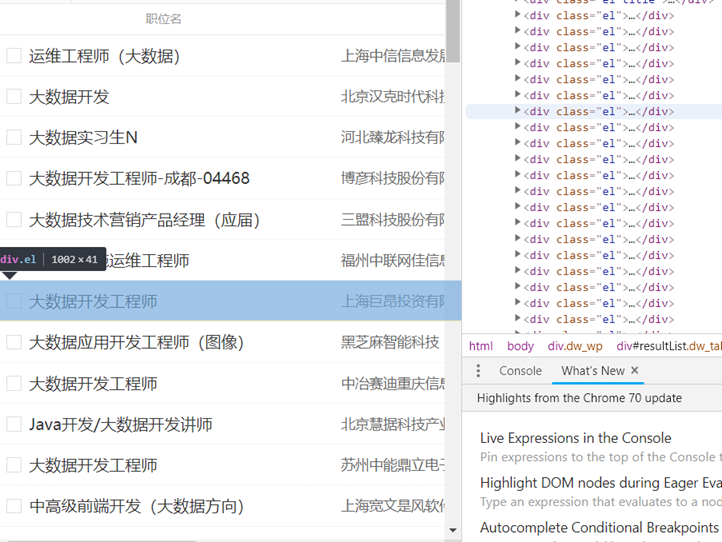
所以通过如下xpath将url提取出来:
-
//*[@id="resultList"]/div/p/span/a/@href
1.3 岗位信息提取
进入某一岗位具体信息url,打开开发者选项,在信息所在标签上右击,提取所需信息的xpath。
-
title = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()')
-
salary = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()')
-
company = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/text()')
-
place = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[1]')
-
exp = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[2]')
-
edu = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[3]')
-
num = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[4]')
-
time = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[5]')
-
comment = selector.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()')
-
url = res.url
跑一遍看看,

咦,怎么岗位要求这么多null?点一个进去看看
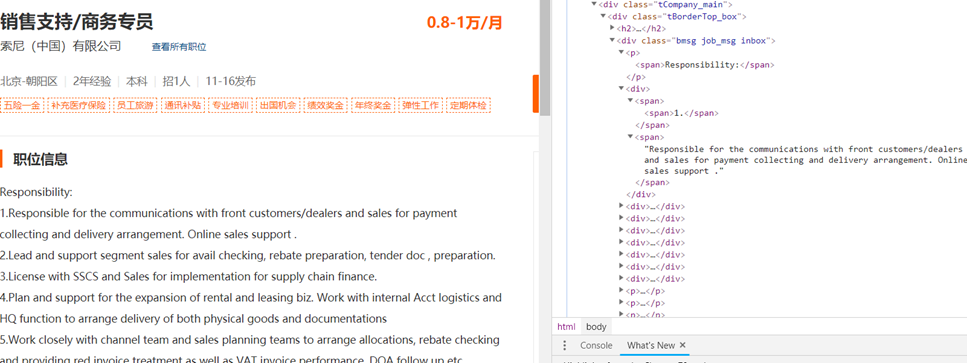
嗯,<div>标签下咋又出现了<div>,真是乱来(笑)。看来得换个法子了,把这个父<div>标签下的中文全部带走。这儿需要用到xpath的steing()函数。将上述方法改造,得到新的xpath:
-
string(/html/body/div[3]/div[2]/div[3]/div[1]/div)
又能跑起来了,不过把该<div>里一些其他信息也带进来了,比如岗位分类等。
二、一些细节
2.1 编码问题
虽然没有系统的学过编码,但是在与不同网页、不同的操作系统打交道的过程中也略知一二了。与前些天爬过的智联招聘不同,前程无忧网页用的是GBK编码,所以需要注意编码格式。而且还有一个小问题:

对,报错了,'ufffd'无法被转码。从网上找来的解释称:
在通过GBK从字符串获取字节数组时,由于一个Unicode转换成两个byte,如果此时用ISO-8859-1或用UTF-8构造字符串就会出现两个问号。
若是通过ISO-8859-1构造可以再通过上面所说的错上加错恢复(即再通过从ISO-8859-1解析,用GBK构造);
若是通过UTF-8构造则会产生Unicode字符"uFFFD",不能恢复,若再通过String-UTF-8〉ByteArray-GBK〉String,则会出现杂码,如a锟斤拷锟斤拷
而在Unicode中,uFFFD为占位符,当从某语言向Unicode转化时,如果在某语言中没有该字符,得到的将是Unicode的代码"uffffd"。
针对这种情况,在打开文件时可设置一个参数——errors:设置不同错误的处理方案,默认为 'strict',意为编码错误引起一个UnicodeError。所以我们需要为该参数换一个值:ignore,当遇到编码问题市直接无视。
-
fp = open('51job.csv','wt',newline='',encoding='GBK',errors='ignore')
-
writer = csv.writer(fp)
-
'''''title,salary,company,place,exp,edu,num,time,comment,url'''
-
writer.writerow(('职位','薪水','公司','地区','经验','学历','数量','时间','要求','url'))
2.2 网页结构问题
电脑端的结构太多了…数据抓取率也低,代码还得改改,还是移动适配又好看又好爬。

三、源代码
因为在写这篇博客的时候,发现了一些之前没发现的问题,并且有了优化的想法,所以就不把代码贴过来了,就留github 吧,这些天再把这个项目改进一下。
源代码地址:51job源代码地址
相关:智联招聘源代码讲解