pyspark读取csv文本保存至MySQL案例
我们在使用spark处理完数据时,经常要将处理好的结果数据保存的如
mysql等关系型数据库中,下面我们通过一个示例说明如何将spark处理好的数据保存到mysql中
- csv文件如下
文件
student.csv
id,name,age
1,张三,23
2,李四,24
- 代码如下
from pyspark.sql.session import SparkSession as spark
sc = spark.builder.master('local[*]').appName('pysparktest').getOrCreate()
stuDF = sc.read.csv('C:\UsersAdministratorDesktopstudent.csv',header=True)
stuDF.show()
prop = {}
prop['user'] = 'root'
prop['password'] = 'root'
prop['driver'] = 'com.mysql.jdbc.Driver'
stuDF.write.jdbc('jdbc:mysql://localhost:3306/pyspark?characterEncoding=UTF-8','student','append',prop)
sc.stop()
问题及坑:
- 1、报错找不到mysql驱动
该解决方案是基于
windows环境配置的pyspark
解决方案:
-
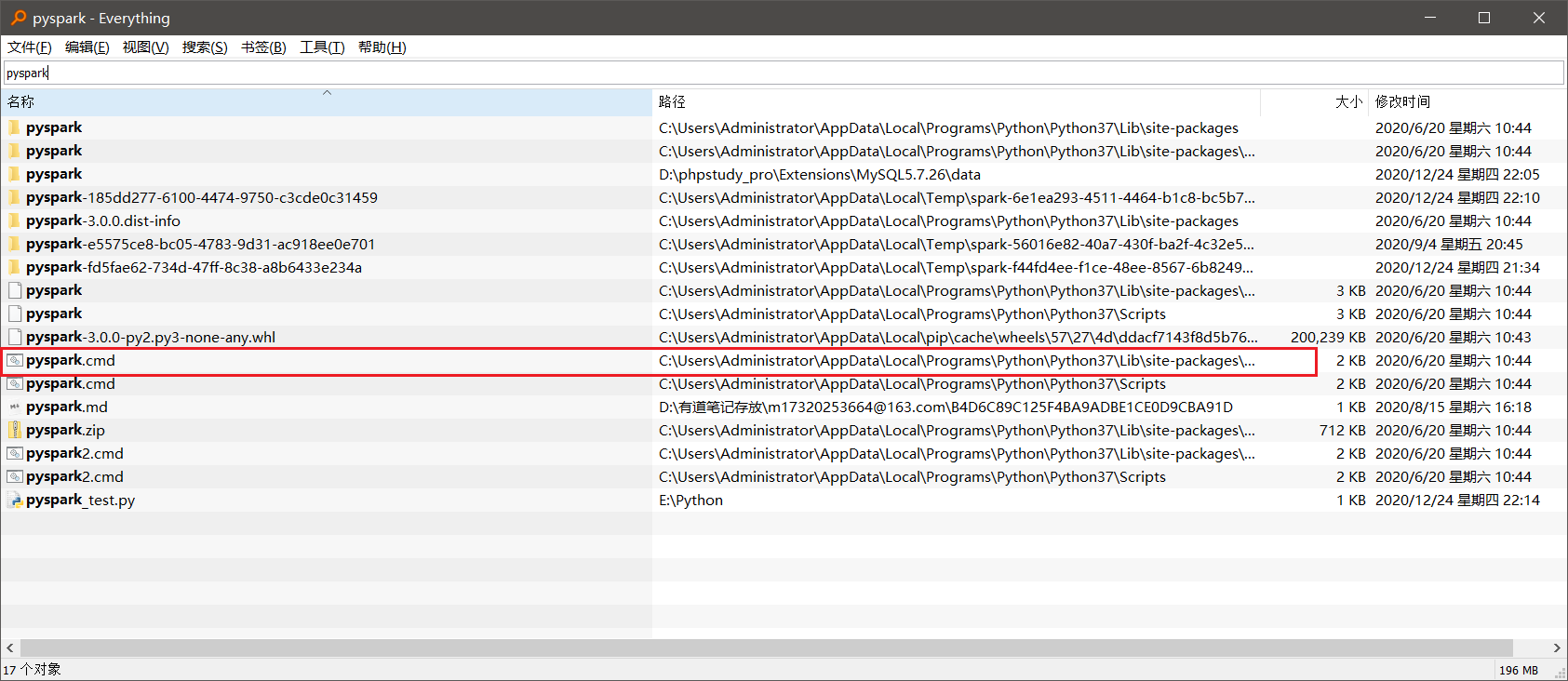
首先找到pyspark的安装路径,如果使用的是
pip的安装的一般在C盘下。
如果找不到可通过全盘检索工具 Everythin搜索pyspark找到spypark.cmd所在的文件夹的上一层就是pyspark的安装路径
如我的安装目录就在下面
-
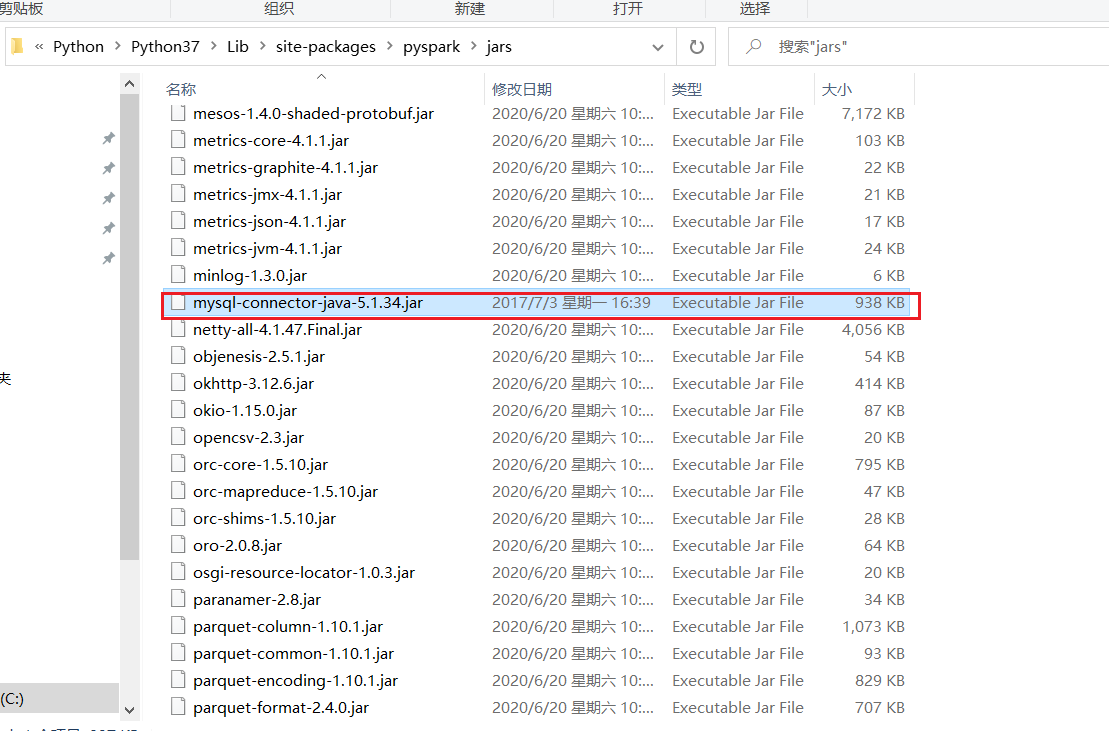
然后将mysql的驱动拷贝到
pyspark安装路径下的jars文件夹中
-
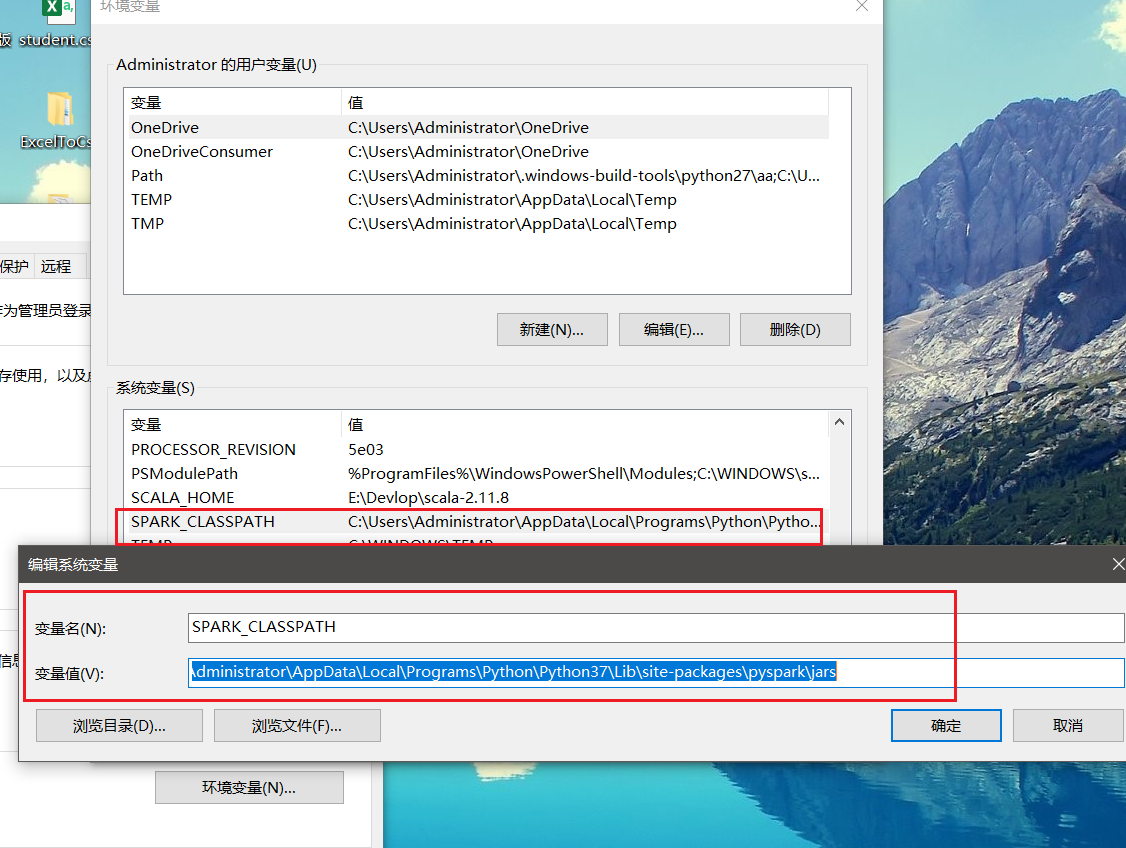
然后在系统环境变量中配置
SPARK_CLASSPATH环境变量
上面的步骤操作完后,愉快的执行代码,发现成功了!!!
