一、环境搭建
1.1、上传spark安装包
创建文件夹用于存放spark安装文件
命令:mkdir spark
1.2、解压spark安装包
命令:tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C /home/bi/spark
1.3、修改环境变量
命令:vi /etc/profile
修改内容:
export SPARK_HOME=/home/bi/spark/spark-2.1.0-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${SPARK_HOME}/bin
命令:source /etc/profile
1.4、修改相应配置
进入目录conf下:
命令:cp spark-env.sh.template spark-env.sh
命令:vi spark-env.sh
修改内容:
export JAVA_HOME=/home/bi/java/jdk1.8.0_121
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/bi/hadoop/hadoop-2.7.3/etc/hadoop
命令:cp slaves.template slaves
命令:vi slaves
修改内容:(删除localhost)
slave1
slave2
1.5、将spark文件夹复制到slave节点下,并配置环境变量
命令:
scp -r spark bi@slave1:/home/bi/
scp -r spark bi@slave2:/home/bi/
1.6、启动spark
命令:sbin目录
sbin/start-all.sh
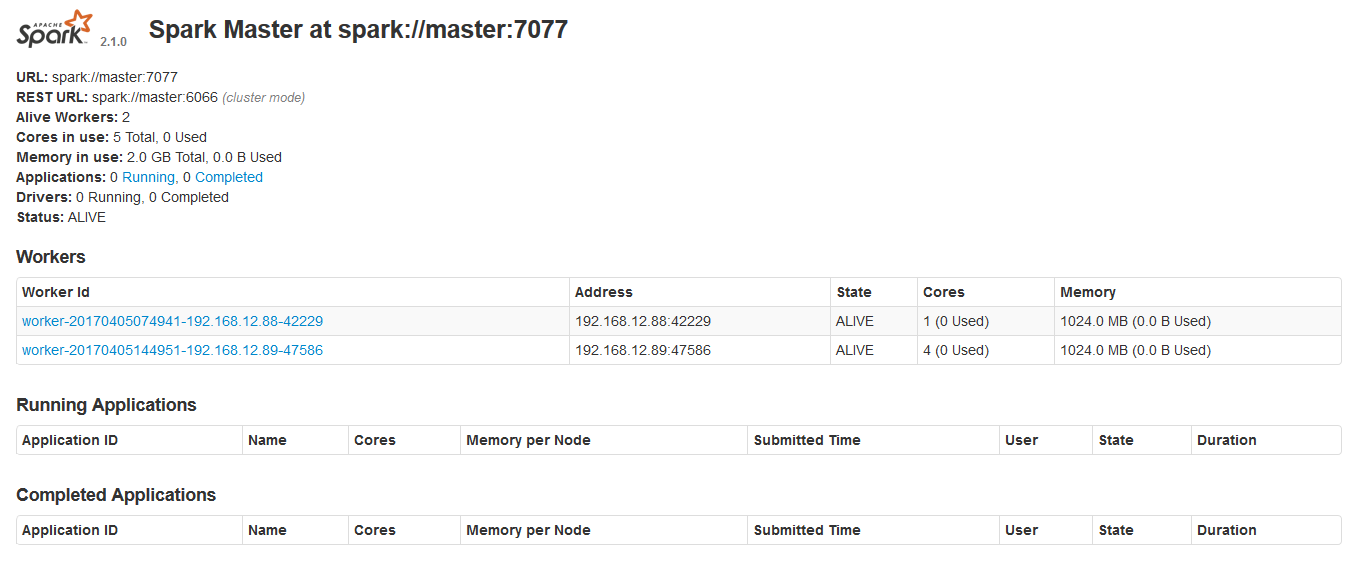
二、查看启动结果
命令:jps(master节点)
命令:jps(slave节点)
也可以打开界面:192.168.12.80:8080查看节点状态