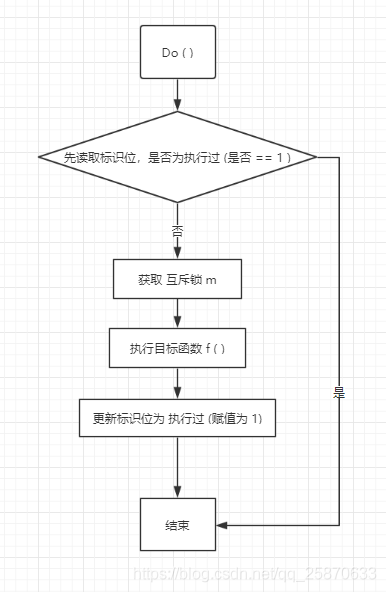
sync.Once.Do(f func())是一个挺有趣的东西,能保证once只执行一次,无论你是否更换once.Do(xx)这里的方法,这个sync.Once块只会执行一次。
package sync import ( "sync/atomic" ) // Once is an object that will perform exactly one action. type Once struct { // done indicates whether the action has been performed. // It is first in the struct because it is used in the hot path. // The hot path is inlined at every call site. // Placing done first allows more compact instructions on some architectures (amd64/x86), // and fewer instructions (to calculate offset) on other architectures. done uint32 // 初始值为0表示还未执行过,1表示已经执行过 m Mutex } // Do calls the function f if and only if Do is being called for the // first time for this instance of Once. In other words, given // var once Once // if once.Do(f) is called multiple times, only the first call will invoke f, // even if f has a different value in each invocation. A new instance of // Once is required for each function to execute. // // Do is intended for initialization that must be run exactly once. Since f // is niladic, it may be necessary to use a function literal to capture the // arguments to a function to be invoked by Do: // config.once.Do(func() { config.init(filename) }) // // Because no call to Do returns until the one call to f returns, if f causes // Do to be called, it will deadlock. // // If f panics, Do considers it to have returned; future calls of Do return // without calling f. // func (o *Once) Do(f func()) { // Note: Here is an incorrect implementation of Do: // // if atomic.CompareAndSwapUint32(&o.done, 0, 1) { // f() // } // // Do guarantees that when it returns, f has finished. // This implementation would not implement that guarantee: // given two simultaneous calls, the winner of the cas would // call f, and the second would return immediately, without // waiting for the first's call to f to complete. // This is why the slow path falls back to a mutex, and why // the atomic.StoreUint32 must be delayed until after f returns. // 每次一进来先读标识位 0 标识没有被执行过,1 标识已经被执行过 if atomic.LoadUint32(&o.done) == 0 { // Outlined slow-path to allow inlining of the fast-path. o.doSlow(f) } } func (o *Once) doSlow(f func()) { o.m.Lock() // 施加互斥锁 defer o.m.Unlock() if o.done == 0 { defer atomic.StoreUint32(&o.done, 1) f() } }
从上面我们可以看出,once只有一个 Do 方法;once的结构体中只定义了两个字段:一个mutex的m,一个代表标识位的done。
下面我们来看看Do方法的流程:
WaitGroup用于等待一组线程的结束。父线程调用Add 方法来设定应等待的线程数量。每个被等待的线程在结束时应调用Done方法。同时,主线程里可以调用wait方法阻塞至所有线程结束。 注意:Add和创建协程的数量一定要匹配,否则会产出panic
主要函数:
func (wg *WaitGroup) Add(delta int):等待协程的数量。
func (wg *WaitGroup) Done(): 减少waitgroup线程等待线程数量的值,一般在协程完成之后执行。
func (wg *WaitGroup) Wait():wait方法一般在主线程调用,阻塞直到group计数减少为0。
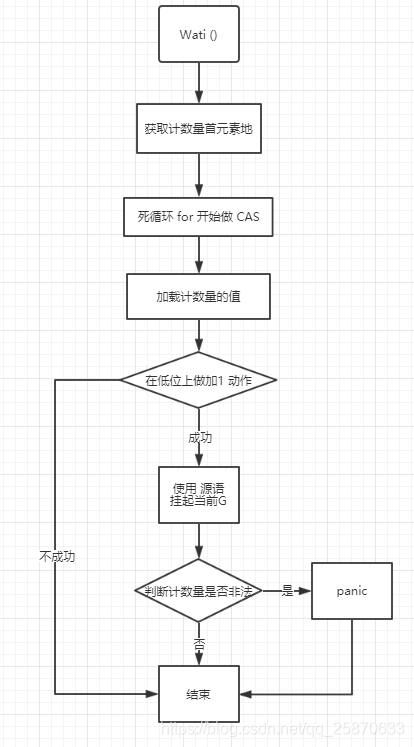
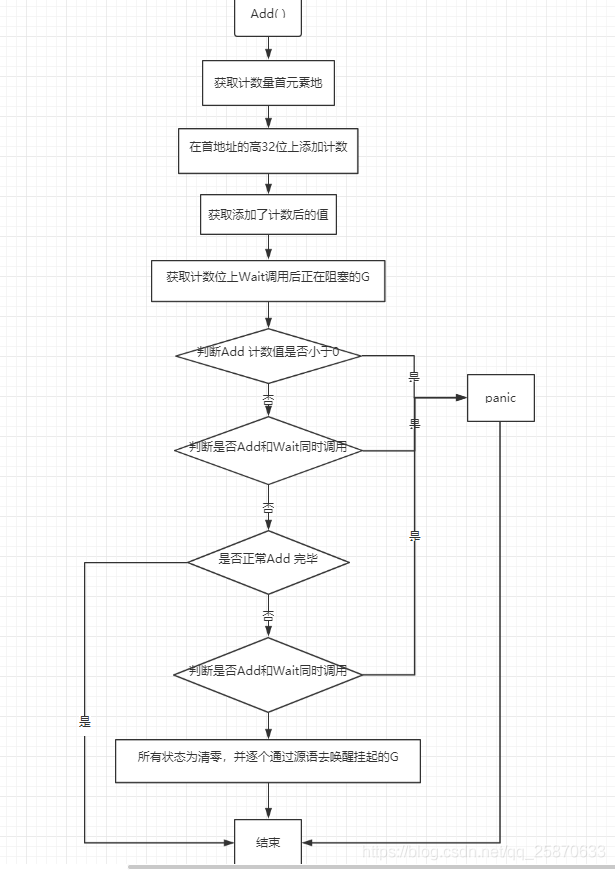
package sync import ( "internal/race" "sync/atomic" "unsafe" ) // A WaitGroup waits for a collection of goroutines to finish. // The main goroutine calls Add to set the number of // goroutines to wait for. Then each of the goroutines // runs and calls Done when finished. At the same time, // Wait can be used to block until all goroutines have finished. // // A WaitGroup must not be copied after first use. type WaitGroup struct { noCopy noCopy // noCopy可以嵌入到结构中,在第一次使用后不可复制 // 64-bit value: high 32 bits are counter, low 32 bits are waiter count. // 64-bit atomic operations require 64-bit alignment, but 32-bit // compilers do not ensure it. So we allocate 12 bytes and then use // the aligned 8 bytes in them as state, and the other 4 as storage // for the sema. // 64 bit:高32 bit是计数器,低32位是 阻塞的goroutine计数。 // 64位的原子操作需要64位的对齐,但是32位。 // 编译器不能确保它,所以分配了12个byte对齐的8个byte作为状态。其他4个作为信号量 state1 [3]uint32 } // uintptr和unsafe.Pointer的区别就是:unsafe.Pointer只是单纯的通用指针类型,用于转换不同类型指针,它不可以参与指针运算; // 而uintptr是用于指针运算的,GC 不把 uintptr 当指针,也就是说 uintptr 无法持有对象,uintptr类型的目标会被回收。 // state()函数可以获取到wg.state1数组中元素组成的二进制对应的十进制的值 和信号量 // 根据编译器位数,获得标志位和等待次数的数据域 // state returns pointers to the state and sema fields stored within wg.state1. func (wg *WaitGroup) state() (statep *uint64, semap *uint32) { if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 { // 是否是 64位机器:因为64位机器站高8位 信号量在后面 return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2] } else { // 如果是 32位机器,型号量在最前面 return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0] } } // Add adds delta, which may be negative, to the WaitGroup counter. // If the counter becomes zero, all goroutines blocked on Wait are released. // If the counter goes negative, Add panics. // // Note that calls with a positive delta that occur when the counter is zero // must happen before a Wait. Calls with a negative delta, or calls with a // positive delta that start when the counter is greater than zero, may happen // at any time. // Typically this means the calls to Add should execute before the statement // creating the goroutine or other event to be waited for. // If a WaitGroup is reused to wait for several independent sets of events, // new Add calls must happen after all previous Wait calls have returned. // See the WaitGroup example. func (wg *WaitGroup) Add(delta int) { // 获取到wg.state1数组中元素组成的二进制对应的十进制的值的指针 和信号量 statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early if delta < 0 { // Synchronize decrements with Wait. race.ReleaseMerge(unsafe.Pointer(wg)) } race.Disable() defer race.Enable() } // 将标记为加delta 因为高32位是计数器 所以把 delta的值左移32位,并从数组的首元素处开始赋值 state := atomic.AddUint64(statep, uint64(delta)<<32) v := int32(state >> 32) // 获取计数器的值:转int32 //获得调用 wait()等待次数:转uint32 w := uint32(state) if race.Enabled && delta > 0 && v == int32(delta) { // The first increment must be synchronized with Wait. // Need to model this as a read, because there can be // several concurrent wg.counter transitions from 0. race.Read(unsafe.Pointer(semap)) } // 计数器为负数,报panic //标记位不能小于0(done过多或者Add()负值太多) if v < 0 { panic("sync: negative WaitGroup counter") } // 不能Add 与Wait 同时调用 if w != 0 && delta > 0 && v == int32(delta) { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // Add 完毕 if v > 0 || w == 0 { return } // This goroutine has set counter to 0 when waiters > 0. // Now there can't be concurrent mutations of state: // - Adds must not happen concurrently with Wait, // - Wait does not increment waiters if it sees counter == 0. // Still do a cheap sanity check to detect WaitGroup misuse. // 当等待计数器> 0时,而goroutine将设置为0。 // 此时不可能有同时发生的状态突变: // - Add()不能与 Wait() 同时发生, // - 如果计数器counter == 0,不再增加等待计数器 // 不能Add 与Wait 同时调用 if *statep != state { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // Reset waiters count to 0. *statep = 0 // 所有状态位清零 for ; w != 0; w-- { // 目的是作为一个简单的wakeup原语,以供同步使用。true为唤醒排在等待队列的第一个goroutine runtime_Semrelease(semap, false, 0) } } // Done decrements the WaitGroup counter by one. // Done方法其实就是Add(-1) func (wg *WaitGroup) Done() { wg.Add(-1) } // Wait blocks until the WaitGroup counter is zero. // Wait 会一直阻塞到 计数器值为0为止 func (wg *WaitGroup) Wait() { statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early race.Disable() } //循环检查计数器V啥时候等于0 for { state := atomic.LoadUint64(statep) v := int32(state >> 32) w := uint32(state) if v == 0 { // Counter is 0, no need to wait. if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } // Increment waiters count. // 尚有未执行完的go程,等待标志位+1(直接在低位处理,无需移位) // 增加等待goroution计数,对低32位加1,不需要移位 if atomic.CompareAndSwapUint64(statep, state, state+1) { if race.Enabled && w == 0 { // Wait must be synchronized with the first Add. // Need to model this is as a write to race with the read in Add. // As a consequence, can do the write only for the first waiter, // otherwise concurrent Waits will race with each other. race.Write(unsafe.Pointer(semap)) } // 目的是作为一个简单的sleep原语,以供同步使用 runtime_Semacquire(semap) // 在上一次Wait返回之前重新使用WaitGroup,即在之前的Done 中没有清空 计数量就会有问题 if *statep != 0 { panic("sync: WaitGroup is reused before previous Wait has returned") } if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } } }
Add:
Wait: