性能监控是性能测试过程中非常重要的一个环节,当在压测过程中出现性能瓶颈时,需要综合详细的监控数据对问题进行分析。整个系统架构中的每一个环节都需要做监控(压力机、网络、各中间件、各服务器硬件资源等)。性能监控做好了,就能帮助你快速的定位问题,找到系统的性能瓶颈。
操作系统级别监控
cpu监控
Top命令:
Top命令是Linux下一个实时的、交互式的,对操作系统整体监控的命令,可以对CPU、内存、进程监控。 是Linux下最常用的监控命令。
起一个项目,给点压力,看看效果

一个并发,永远跑,看一下

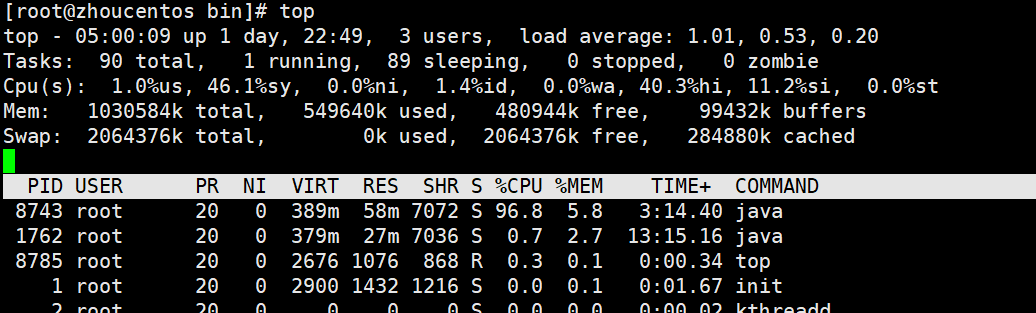
load average:过去某段时间内CPU平均的负载情况,(排队要执行的的进程数)
第一个值所在的位置:过去一分钟的
第二个值所在的位置:过去五分钟的
第三个值所在的位置:过去十五分钟的
一般来说,排队的数量最好不要超过cpu的核数,比如4核,但是数字大于4,则代表有进程在排队,等待执行
Task:当前有多少个任务
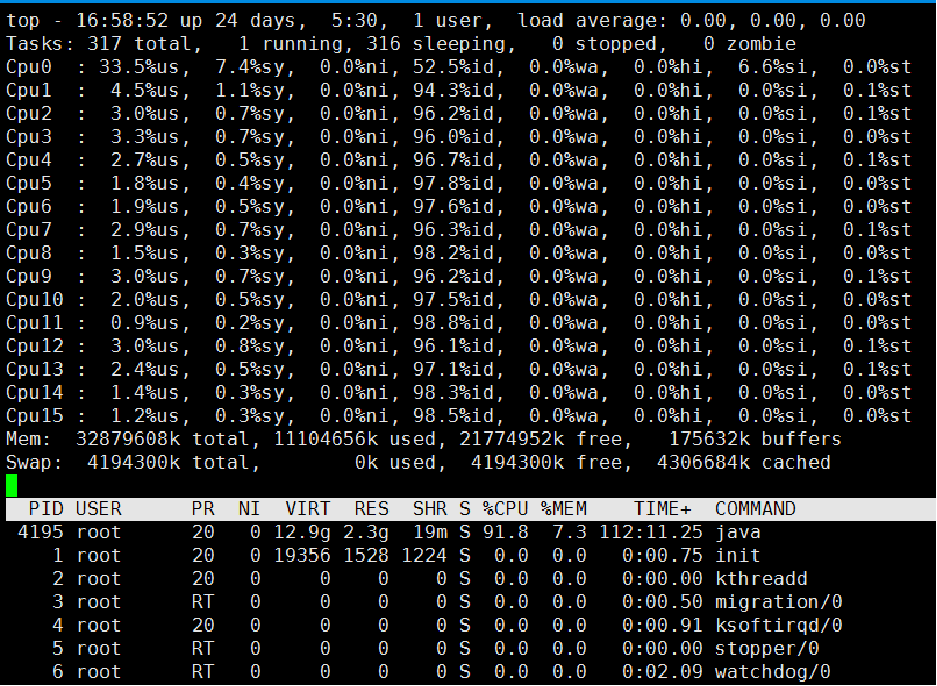
Cpu(s):反映cpu的一些数据:
us:用户使用(用户进程,如myslq、tomcat、qq)的cpu的百分比
sy:系统使用的cpu的百分比
ni:指进程的优先级,一般都是0,不用管
id:idle,空闲的:=1-us-sy
wa:wait,因为有些任务是需要些磁盘的(如tomcat需要写日志),而CPU的速度比磁盘写入的速度更快,所以有了这个等待写入数据的状态,如果这个值比较大的话,说明磁盘写入速度比较慢,压力比较大,磁盘那块很可能就有问题
hi、si、st:跟中断相关的,不用关注
按1会展示每个核的具体情况,由于我的是单核,所以按了1也只有这一个

以下截图为16核的
Mem:memory,内存,一般如果是要看内存不使用top命令,下面有一个专门看内存的命令
Swap:交换分区,磁盘上的一块区域,当内存满时,可以充当临时内存,但是速度还是比真实的内存满很多,比如,系统一直运行中,到某个时候,内存已经满了,这个时候还想启动一个程序,cpu会检测,有哪些程序已经长时间没活动了,但是还占用着内存,这个时候,会把这些程序占用的内存,转移到swap空间中,腾出一些空间保证用户能继续启动程序(如WPS启动着最小化过一段时间不用,再切换回来的时候,会很卡),所以说这个指标反映出内存是否足够的情况,若used数据一直在涨,则说明内存不足
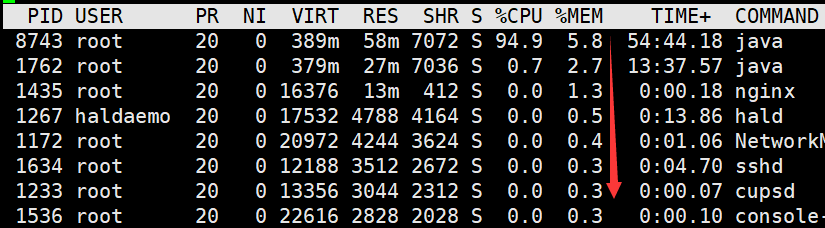
RES:当前进程所占的真实内存的大小
%CPU:指当前进程占cpu使用的比例,为所有核占用之和,比如8核,这里有可能统计出来是800
%MEM:当前进程占用内存的百分比
top命令默认是以占用cpu的比例降序排列的,若想以占用内存的比例来排序,按M即可,按P切回cpu
内存监控
free命令可以查看当前系统内存的使用情况

free -m 以MB为单位显示系统内存的使用情况,同理,也可以使用-k、-g等其他的单位显示,此处换算单位精度的问题,检测为1006M,实际为1G

free命令从两个维度统计了内存的使用情况
第一行Mem:

从操作系统角度统计内存的total(总共)、used(已使用)、free(剩余)、buffers(往内存写内容的时候的缓存)、cached(读内存的时候的缓存,类似于Redis和Mysql的关系)
所以,实际剩余内存=free+buffer+cached
第二行-/+buffers:
从应用程序角度统计内存的total、used、free、buffers、cached

buffer和cache
两者都是Linux下的缓存机制,其中buffer为写操作的缓存,cache为读操作的缓存
swap
交换空间,磁盘上的一块空间,当系统内存不足时,会使用交换空间
磁盘监控
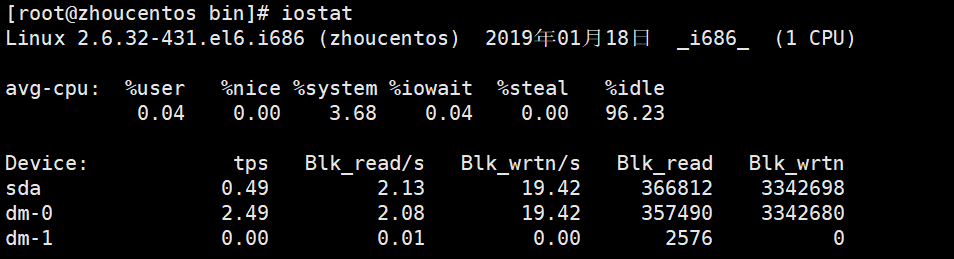
iostat命令可以查看当前机器磁盘io的数据
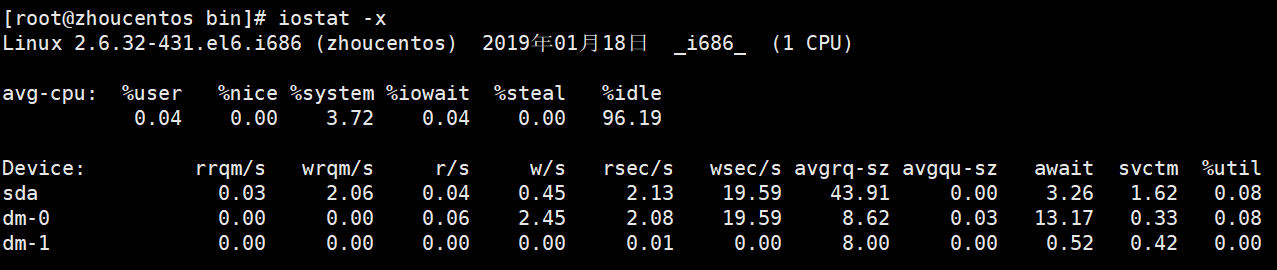
命令:iostat -x -k 1
-x:展示磁盘的扩展信息
-k:以k为单位展示磁盘数据
1:每1秒刷新一次
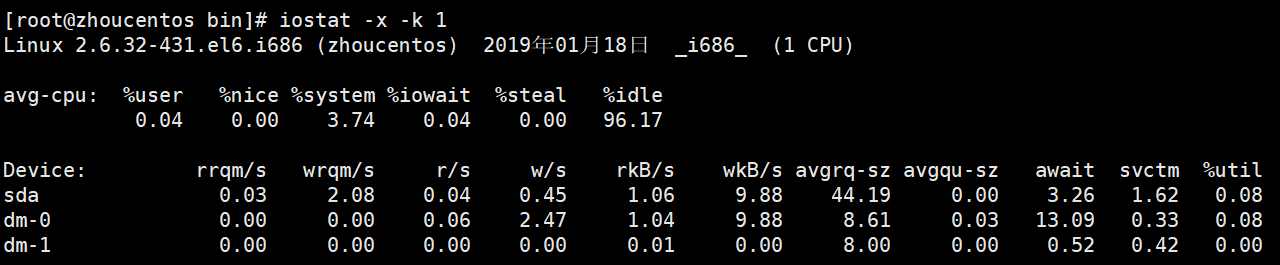
avg-cpu:监控cpu的指标
Device:真正监控磁盘的数据,一般数据库服务器消耗磁盘比较多,应用程序一般消耗磁盘不多,消耗cpu比较多
展示结果
util:磁盘IO使用率,单位%,反映磁盘的繁忙程度,上限100%,一般达到90%就代表磁盘压力非常大了,已经达到瓶颈了, 当看到util比较大 的时候,看看rkb和wkb的情况,看看是那个造成的
r/s:每秒读请求数
w/s:每秒写请求数
rkb/s:每秒读磁盘字节数
wkb/s:每秒写磁盘字节数
df命令可以查看当前系统磁盘空间的使用情况
命令:df -h

磁盘速度测试,如果磁盘读写的性能极差,那么压测出来的结果极有可能不准,比如我的2.7M,肯定太小了,一般至少是50多MB/秒
命令:dd if=/dev/zero of=/export/ddtest bs=8k count=1000000 oflag=direct
过几秒钟后Ctrl+c结束
