1、什么是算法?
算法(Algorithm):一个计算过程,解决问题的方法
2、复习:递归
递归的两个特点:(1) 调用自身 (2)结束条件


def func1(x): print(x) func1(x-1) def func2(x): if x>0: print(x) func2(x+1) def func3(x): if x>0: print(x) func3(x-1) def func4(x): if x>0: func4(x-1) print(x)
func1和func2不是递归
func3和func4是递归,但是结果不一样,func3(5)打印的是5,4,3,2,1 而func4(5)结果是1,2,3,4,5
3、时间复杂度
时间复杂度:用来评估算法运行效率的一个东西


小结:
时间复杂度是用来估计算法运行时间的一个式子(单位)。
一般来说,时间复杂度高的算法比复杂度低的算法快。
常见的时间复杂度(按效率排序)
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(nlogn)<O(n^3)
不常见的时间复杂度(看看就好)
O(n!) O(2n) O(nn) …
如何一眼判断时间复杂度?
循环减半的过程O(logn)
几次循环就是n的几次方的复杂度
4、空间复杂度
空间复杂度:用来评估算法内存占用大小的一个式子
5、列表查找
列表查找:从列表中查找指定元素
输入:列表、待查找元素
输出:元素下标或未查找到元素
6、顺序查找
从列表第一个元素开始,顺序进行搜索,直到找到为止。
7、二分查找
从有序列表的候选区data[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。
def bin_search(data_set,val): ''' mid:下标 low:每次循环的列表最左边下标 high:每次循环的列表最右边下标 :param data_set:列表 :param val: 要找的值 :return: ''' low = 0 high = len(data_set)-1 while low <= high: mid = (low+high)//2 if data_set[mid] == val: return mid elif data_set[mid] > val: high = mid - 1 else: low = mid + 1 return
8、列表排序
将无序列表变为有序列表
应用场景: 各种榜单 各种表格 给二分查找用 给其他算法用
输入:无序列表
输出:有序列表
9、排序中比较慢的三种: 冒泡排序 选择排序 插入排序
快速排序
排序NB二人组: 堆排序 归并排序
没什么人用的排序: 基数排序 希尔排序 桶排序
算法关键点: 有序区 无序区
10、冒泡排序
首先,列表每两个相邻的数,如果前边的比后边的大,那么交换这两个数
n = len(list),循环了i趟(i=n-1),第i趟循环比较了(j = n-i-1 )次,j是每趟循环比较的次数
import random,time #装饰器 def cal_time(func): def wrapper(*args,**kwargs): t1 = time.time() ret = func(*args,**kwargs) t2 = time.time() print('time cost: %s func from %s'%(t2-t1,func.__name__)) return func return wrapper @cal_time def bubble_sort(li): for i in range(len(li) - 1): for j in range(len(li) - i - 1): #升续 if li[j] > li[j+1]: li[j],li[j+1]=li[j+1],li[j] #降续 # if li[j] < li[j+1]: # li[j],li[j+1]=li[j+1],li[j] data = list(range(1000)) random.shuffle(data) print(data) bubble_sort(data) print(data)
优化后的冒泡排序:
如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。
import random,time #装饰器 def cal_time(func): def wrapper(*args,**kwargs): t1 = time.time() ret = func(*args,**kwargs) t2 = time.time() print('time cost: %s func from %s'%(t2-t1,func.__name__)) return func return wrapper @cal_time def bubble_sort(li): for i in range(len(li) - 1): exchange = False for j in range(len(li) - i - 1): #升续 if li[j] > li[j+1]: li[j],li[j+1]=li[j+1],li[j] exchange = True #降续 # if li[j] < li[j+1]: # li[j],li[j+1]=li[j+1],li[j] # exchange = True #这里是指上一趟,值之间没有发生交换,就退出循环 if not exchange: break data = list(range(1000)) random.shuffle(data) print(data) bubble_sort(data) print(data)
11、选择排序
一趟遍历记录最小的数,放到第一个位置; 再一趟遍历记录剩余列表中最小的数,继续放置;
import random,time #装饰器 def cal_time(func): def wrapper(*args,**kwargs): t1 = time.time() ret = func(*args,**kwargs) t2 = time.time() print('time cost: %s --> func from %s'%(t2-t1,func.__name__)) return func return wrapper @cal_time def select_sort(li): for i in range(len(li)-1): min_loc = i for j in range(i+1,len(li)): if li[j] < li[min_loc]: min_loc = j li[i],li[min_loc] = li[min_loc],li[i]
12、插入排序
def insert_sort(li): for i in range(1,len(li)): tmp = li[i] j = i - 1 while j >= 0 and tmp < li[j]: li[j + 1] = li[j] j -= 1 li[j + 1] = tmp
13、练习 用冒泡法把打乱的带ID的信息表排序
import random def random_list(n): ids = range(1000,1000+n) result = [] a1 = ["王","陈","李","赵","钱","孙","武"] a2 = ["丹","泽","","","晶","杰","金"] a3 = ["强","华","国","富","宇","齐","星"] for i in range(n): age = random.randint(16,38) id = ids[i] name = '%s%s%s'%(random.choice(a1),random.choice(a2),random.choice(a3)) dic = {} dic['id'] = id dic['姓名'] = name dic['年龄'] = age result.append(dic) return result def bubble_sort(li): for i in range(len(li)-1): for j in range(len(li)-i-1): if li[j]['id'] > li[j+1]['id']: li[j],li[j+1] = li[j+1],li[j] data1 = random_list(100) random.shuffle(data1) print(data1) bubble_sort(data1) print(data1)
14、快速排序:快
好写的排序算法里最快的
快的排序算法里最好写的
快排思路:
取一个元素p(第一个元素),使元素p归位;
列表被p分成两部分,左边都比p小,右边都比p大;
递归完成排序。
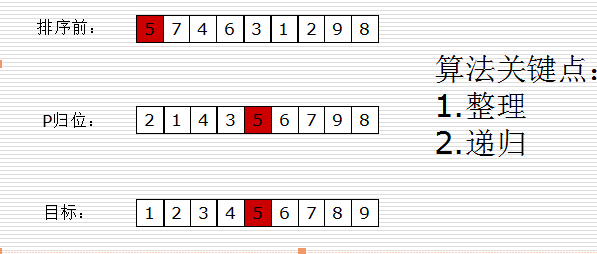
#快排的复杂度是O(nlog(n)),这是一个特殊情况
#口诀 右手左手一个慢动作,右手左手慢动作重播(递归)
import time,random,copy def cal_time(func): def wrapper(*args,**kwargs): t1 = time.time() ret = func(*args,**kwargs) t2 = time.time() print('time cost: %s from %s'%(t2-t1,func.__name__)) return func return wrapper def quick_sort_x(data,left,right): #这里的left和right是定义列表data,最少有两个元素 if left<right: #partition分割函数,mid是放好的元素的下标 mid = partition(data,left,right) #以下类似二分 quick_sort_x(data,left,mid-1) quick_sort_x(data,mid+1,right) #快排的复杂度是O(nlog(n)),这是一个特殊情况 def partition(data,left,right): #获取左边的第一个元素,这里写left不能写零,因为后面需要递归 tmp = data[left] #终止条件为当left和right碰上时,所以左小于右时为while循环的条件(left和right是下标) while left < right: #循环条件是右边比tmp大,直到找到右边比tmp小的数,停止循环 while left < right and data[right] >= tmp: right -= 1 #把找到的右边比tmp小的数移到左边空出来的位置 data[left] = data[right] #循环条件是左边比tmp小,继续循环,直到找到左边比tmp大的数,结束循环 while left < right and data[left] <= tmp: left += 1 #把左边找到的大于tmp的数移到右边空出来的位置 data[right] = data[left] #当左右相等时,就把tmp放到left和right碰到的位置 data[left] = tmp #mid的值和lef或right值相同,return哪个都可以 #mid = left # return mid return left #对递归函数的装饰,需要再封装一层 @cal_time def quik_sort(data): #0及是left,len(data)-1为right return quick_sort_x(data,0,len(data)-1)
import time,random,copy def cal_time(func): def wrapper(*args,**kwargs): t1 = time.time() ret = func(*args,**kwargs) t2 = time.time() print('time cost: %s from %s'%(t2-t1,func.__name__)) return func return wrapper def quick_sort_x(data,left,right): #这里的left和right是定义列表data,最少有两个元素 if left<right: #partition分割函数,mid是放好的元素的下标 mid = partition(data,left,right) #以下类似二分 quick_sort_x(data,left,mid-1) quick_sort_x(data,mid+1,right) #快排的复杂度是O(nlog(n)),这是一个特殊情况 def partition(data,left,right): #获取左边的第一个元素,这里写left不能写零,因为后面需要递归 tmp = data[left] #终止条件为当left和right碰上时,所以左小于右时为while循环的条件(left和right是下标) while left < right: #循环条件是右边比tmp大,直到找到右边比tmp小的数,停止循环 while left < right and data[right] >= tmp: right -= 1 #把找到的右边比tmp小的数移到左边空出来的位置 data[left] = data[right] #循环条件是左边比tmp小,继续循环,直到找到左边比tmp大的数,结束循环 while left < right and data[left] <= tmp: left += 1 #把左边找到的大于tmp的数移到右边空出来的位置 data[right] = data[left] #当左右相等时,就把tmp放到left和right碰到的位置 data[left] = tmp #mid的值和lef或right值相同,return哪个都可以 #mid = left # return mid return left #对递归函数的装饰,需要再封装一层 @cal_time def quik_sort(data): #0及是left,len(data)-1为right return quick_sort_x(data,0,len(data)-1) #冒泡排序 @cal_time def bubble_sort(li): for i in range(len(li) - 1): exchange = False for j in range(len(li) - i - 1): #升续 if li[j] > li[j+1]: li[j],li[j+1]=li[j+1],li[j] exchange = True #降续 # if li[j] < li[j+1]: # li[j],li[j+1]=li[j+1],li[j] # exchange = True #这里是指上一趟,值之间没有发生交换,就退出循环 if not exchange: break data = list(range(5000)) random.shuffle(data) #深度拷贝 data1 = copy.deepcopy(data) data2 = copy.deepcopy(data) #快排和冒泡的比较 quik_sort(data1) bubble_sort(data2) print(data1)
升续:

降续:

排序速度的定义:

一般情况下快排比冒泡快,快排有递归深度的问题,如果深度高的话,需要调整。
15、堆排序
(1)树与二叉树简介
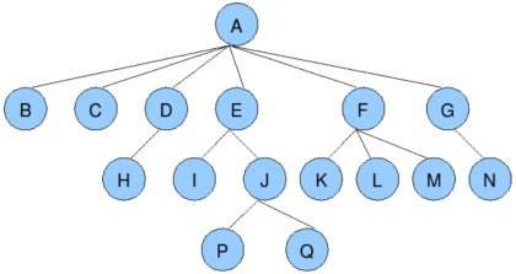
树是一种数据结构 比如:目录结构
树是一种可以递归定义的数据结构
树是由n个节点组成的集合:
如果n=0,那这是一棵空树;
如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树。
一些概念
根节点、叶子节点
树的深度(高度)
树的度
孩子节点/父节点 子树
(2)二叉树
二叉树:度不超过2的树(节点最多有两个叉)

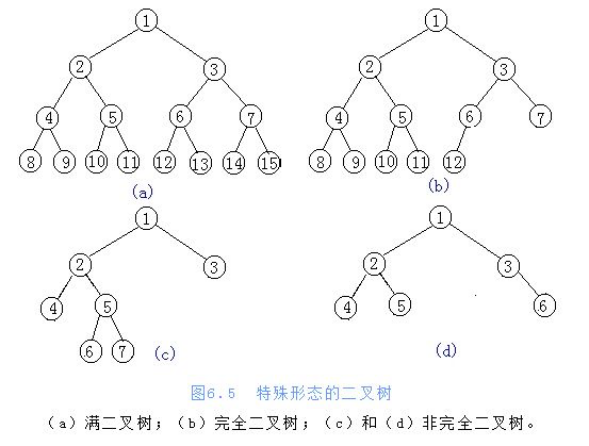
(3)满二叉树,完全二叉树
(4)二叉树的存储方式
链式存储方式
顺序存储方式(列表)
父节点和左孩子节点的编号下标有什么关系?
0-1 1-3 2-5 3-7 4-9
i ~ 2i+1
父节点和右孩子节点的编号下标有什么关系?
0-2 1-4 2-6 3-8 4-10
i ~ 2i+2
(5)小结
二叉树是度不超过2的树
满二叉树与完全二叉树
(完全)二叉树可以用列表来存储,通过规律可以从父亲找到孩子或从孩子找到父亲
(6)堆排序
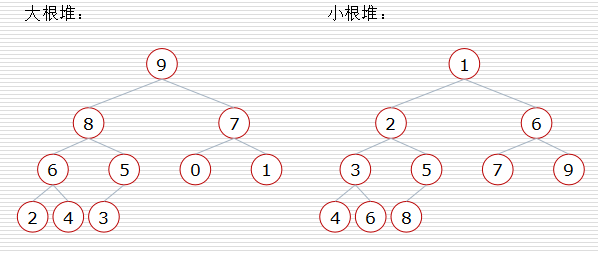
大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大
小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小
(7)堆排序过程
a、建立堆
b、得到堆顶元素,为最大元素
c、去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序。
d、堆顶元素为第二大元素。
e、 重复步骤3,直到堆变空。