第十章 早期(编译期)优化
1、Javac的源码与调试
编译期的分类:
- 前端编译期:把*.java文件转换为*.class文件的过程。例如sun的javac、eclipseJDT中的增量编译器。
- JIT编译期:后端运行期编译器,把字节码转换成机器骂的过程。例如 HotSpot VM的C1、C2编译器。
- AOT编译器:静态提前编译器,直接拔Java文件编译成本地机器代码的过程,例如GCJ。
Javac的编译过程:
- 解析与填充符号表的过程。
- 插入式注解处理器的注解过程。
- 分析与字节码生成的过程。
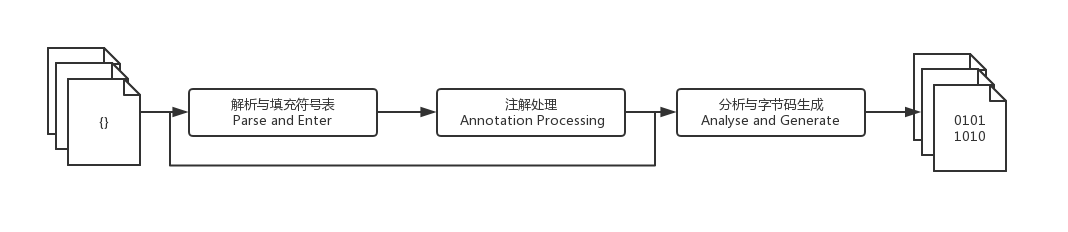
- Javac编译动作的入口是com.sun.tools.javac.main.JavaCompiler类,上述3个过程的代码逻辑集中在这个类的compile()和compile2()方法中,其中主体代码如图所示,整个编译最关键的处理就由图中标注的8个方法来完成,下面我们具体看一下这8个方法实现了什么功能。

解析与填充符号表的过程:
- 词法分析,是将源代码的字符流转变为标记(Token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,关键字、变量名、字面量、运算符都可以成为标记。
- 语法分析,是根据Token序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个阶段都代表着程序代码中的一个语法结构(Construct),例如包、类型、修饰符、运算符、接口、返回值甚至代码注释等都可以是一个语法结构。
- 填充符号表,符号表是由一组符号地址和符号信息构成的表格。符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否一致)和产生中间代码。在目标代码生成阶段,当对符号名进行地质分配时,符号表是地址分配的依据。填充符号表的过程由com.sun.tools.javac.comp.Enter类实现,此过程的出口是一个待处理列表(To Do List),包含了每一个编译单元的抽象语法树的顶级节点,以及package-info.java(如果存在的话)的顶级节点
注解处理器:
- 在JDK1.6中实现了JSR-269规范,提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止。
- 插入式注解处理器的初始化过程是在initPorcessAnnotations()方法中完成的,而它的执行过程则是在processAnnotations()方法中完成的。
- 实现注解处理器的代码需要继承抽象类javax.annotation.processing.AbstractProcessor,这个抽象类中只有一个必须覆盖的abstract方法:“process()”,除了process()方法的传入参数之外,还有一个很常用的实例变量“processingEnv”,它是AbstractProcessor中的一个protected变量,在注解处理器初始化的时候(init()方法执行的时候)创建,继承了AbstractProcessor的注解处理器代码可以直接访问到它。它代表了注解处理器框架提供的一个上下文环境,要创建新的代码、向编译器输出信息、获取其他工具类等都需要用到这个实例变量。注解处理器除了process()方法及其参数之外,还有两个可以配合使用的Annotations:@SupportedAnnotationTypes和@SupportedSourceVersion,前者代表了这个注解处理器对哪些注解感兴趣,可以使用星号“*”作为通配符代表对所有的注解都感兴趣,后者指出这个注解处理器可以处理哪些版本的Java代码。每一个注解处理器在运行的时候都是单例的,如果不需要改变或生成语法树的内容,process()方法就可以返回一个值为false的布尔值,通知编译器这个Round中的代码未发生变化,无须构造新的JavaCompiler实例,在这次实战的注解处理器中只对程序命名进行检查,不需要改变语法树的内容,因此process()方法的返回值都是false。

package com.ecut.javac; import java.util.EnumSet; import java.util.Set; import javax.annotation.processing.AbstractProcessor; import javax.annotation.processing.Messager; import javax.annotation.processing.ProcessingEnvironment; import javax.annotation.processing.RoundEnvironment; import javax.annotation.processing.SupportedAnnotationTypes; import javax.annotation.processing.SupportedSourceVersion; import javax.lang.model.SourceVersion; import javax.lang.model.element.Element; import javax.lang.model.element.ElementKind; import javax.lang.model.element.ExecutableElement; import javax.lang.model.element.Name; import javax.lang.model.element.TypeElement; import javax.lang.model.element.VariableElement; import javax.lang.model.util.ElementScanner7; import javax.tools.Diagnostic.Kind; //这个注解处理器对那些注解感兴趣,使用*表示支持所有的Annotations @SupportedAnnotationTypes(value = "*") //这个注解处理器可以处理那些Java版本的代码,只支持Java1.8的代码 @SupportedSourceVersion(value = SourceVersion.RELEASE_8) public class NameCheckProcessor extends AbstractProcessor { private NameCheck nameCheck; /** * 初始化检查插件 * 继承了AbstractProcessor的注解处理器可以直接访问继承了processingEnv,它代表上下文环境,要穿件新的代码、向编译器输出信息、获取其他工具类都需要用到这个实例 * * @param processingEnv ProcessingEnvironment */ @Override public synchronized void init(ProcessingEnvironment processingEnv) { super.init(processingEnv); this.nameCheck = new NameCheck(processingEnv); } /** * 对语法树的各个节点今夕名称检查 * java编译器在执行注解处理器代码时要调用的过程 * * @param annotations * @param roundEnv * @return */ @Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) { if (!roundEnv.processingOver()) { for (Element element : roundEnv.getRootElements()) { nameCheck.check(element); } } return false; } /** * 程序名称规范的编译期插件 * 程序名称规范的编译器插件 如果程序命名不合规范,将会输出一个编译器的Warning信息 * * @author kevin */ public static class NameCheck { Messager messager = null; public NameCheckScanner nameCheckScanner; private NameCheck(ProcessingEnvironment processingEnv) { messager = processingEnv.getMessager(); nameCheckScanner = new NameCheckScanner(processingEnv); } /** * 对Java程序明明进行检查,根据《Java语言规范(第3版)》6.8节的要求,Java程序命名应当符合下列格式: * <ul> * <li>类或接口:符合驼式命名法,首字母大写。 * <li>方法:符合驼式命名法,首字母小写。 * <li>字段: * <ul> * <li>类,实例变量:符合驼式命名法,首字母小写。 * <li>常量:要求全部大写 * </ul> * </ul> * * @param element */ public void check(Element element) { nameCheckScanner.scan(element); } /** * 名称检查器实现类,继承了1.6中新提供的ElementScanner6<br> * 将会以Visitor模式访问抽象语法数中得元素 * * @author kevin */ public static class NameCheckScanner extends ElementScanner7<Void, Void> { Messager messager = null; public NameCheckScanner(ProcessingEnvironment processingEnv) { this.messager = processingEnv.getMessager(); } /** * 此方法用于检查Java类 */ @Override public Void visitType(TypeElement e, Void p) { scan(e.getTypeParameters(), p); checkCamelCase(e, true); super.visitType(e, p); return null; } /** * 检查方法命名是否合法 */ @Override public Void visitExecutable(ExecutableElement e, Void p) { if (e.getKind() == ElementKind.METHOD) { Name name = e.getSimpleName(); if (name.contentEquals(e.getEnclosingElement().getSimpleName())) { messager.printMessage(Kind.WARNING, "一个普通方法:" + name + " 不应当与类名重复,避免与构造函数产生混淆", e); checkCamelCase(e, false); } } super.visitExecutable(e, p); return null; } /** * 检查变量是否合法 */ @Override public Void visitVariable(VariableElement e, Void p) { /* 如果这个Variable是枚举或常量,则按大写命名检查,否则按照驼式命名法规则检查 */ if (e.getKind() == ElementKind.ENUM_CONSTANT || e.getConstantValue() != null || heuristicallyConstant(e)) { checkAllCaps(e); } else { checkCamelCase(e, false); } super.visitVariable(e, p); return null; } /** * 判断一个变量是否是常量 * * @param e * @return */ private boolean heuristicallyConstant(VariableElement e) { if (e.getEnclosingElement().getKind() == ElementKind.INTERFACE) { return true; } else if (e.getKind() == ElementKind.FIELD && e.getModifiers().containsAll(EnumSet.of(javax.lang.model.element.Modifier.FINAL, javax.lang.model.element.Modifier.STATIC, javax.lang.model.element.Modifier.PUBLIC))) { return true; } return false; } /** * 检查传入的Element是否符合驼式命名法,如果不符合,则输出警告信息 * * @param e * @param initialCaps */ private void checkCamelCase(Element e, boolean initialCaps) { String name = e.getSimpleName().toString(); boolean previousUpper = false; boolean conventional = true; int firstCodePoint = name.codePointAt(0); if (Character.isUpperCase(firstCodePoint)) { previousUpper = true; if (!initialCaps) { messager.printMessage(Kind.WARNING, "名称:" + name + " 应当已小写字符开头", e); return; } } else if (Character.isLowerCase(firstCodePoint)) { if (initialCaps) { messager.printMessage(Kind.WARNING, "名称:" + name + " 应当已大写字母开否", e); return; } } else { conventional =