关于子查询:
in,exists,not in,not exists
exists:对外表用loop逐条查询,每次查询都会查看exists的条件语句,当内表能返回结果集则为true,不能返回结果则为false
select * from user where exists(select 1);
因为select 1永远为true,所以这条select 等价于:select * from user;
select * from user where exists (select * from user where userId = 0);
因为找不到userId=0的结果,所以结果集一定返回空集
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询
select * from user where userId in (1, 2, 3);
等价于
select from user where userId =1 or userId=2 or or userId=3;
in和exists比较:
1: select * from A where exists (select * from B where B.id = A.id);
2: select * from A where A.id in (select id from B);
可以看到exists主要用到了B表的索引,A表如何对查询的效率影响不大,
而in主要用到了A表的索引,B表如何对查询的效率影响不大
所以不一定是exists的效率就比in高,关键看表
not in 和exists比较
由于not in 内外表都进行全表扫描,没有用到索引,而not exists的子查询依然能用到表上的索引,所以not exists的效率一般比not in的高
关于事务的四大属性(ACID)和隔离级别:
四大属性:
Atomicity:原子性,要么都做,要么都不做,开启事务后,只有事务中所有的数据库操作完成后,整个事务的执行才能成功。
Consitency:一致性,事务将数据库从一种状态变为另一种状态,在事务开始之前和事务结束之后数据库的完整性约束没有被破坏,比如在表中有一个字段为姓名,它是一个唯一约束,但是当事务提交或事务回滚后,表中的数据姓名变得非唯一了,那么就是破坏了事务的唯一性了,因此事务是一致性的单位,如果事务的某个动作失败了,系统可以自动地撤销事务使其恢复到原始状态。
Isolaiton:隔离性,每个读写事务的对象与其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,通常使用锁来实现
Durability:持久性,事务一旦提交,其结果就是永久性的。即使发生宕机等故障,数据库也能将数据恢复。
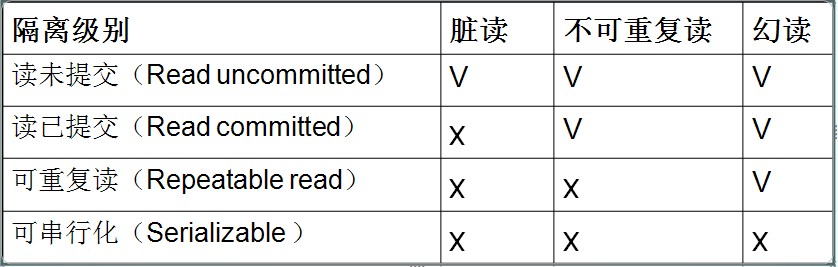
隔离级别:
Read Uncommitted,Read Committed,Repeatable Read,Serializable
设置级别:set tx_isolation='Repeatable Read';
查看级别:select @@tx_isolation;
第一级别:Read Uncommitted:所有事务都可以看到其他未提交事务的执行结果,会引起脏读问题
#事务A:启动一个事务 start transaction; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +------+------+
#事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交 start transaction; update tx set num=10 where id=1; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | | 2 | 2 | | 3 | 3 | +------+------+
#事务A:那么这时候事务A能看到这个更新了的数据吗? select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据 | 2 | 2 | | 3 | 3 | +------+------+
#事务B:事务B回滚,仍然未提交 rollback; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +------+------+
#事务A:在事务A里面看到的也是B没有提交的数据 select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到! | 2 | 2 | | 3 | 3 | +------+------
第二级别:Read Committed(读取提交内容):这是大多数数据库系统的默认隔离级别,但是会带来不可重复读的问题,不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果
#事务A:启动一个事务 start transaction; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +------+------+
#事务B:也启动一个事务(那么两个事务交叉了)
在这事务中更新数据,且未提交 start transaction; update tx set num=10 where id=1; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | | 2 | 2 | | 3 | 3 | +------+------+
#事务A:这个时候我们在事务A中能看到数据的变化吗? select * from tx; ---------------> +------+------+ | | id | num | | +------+------+ | | 1 | 1 |--->并不能看到! | | 2 | 2 | | | 3 | 3 | | +------+------+ |——>相同的select语句,结果却不一样 | #事务B:如果提交了事务B呢? | commit; | | #事务A: | select * from tx; ---------------> +------+------+ | id | num | +------+------+ | 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化 | 2 | 2 | | 3 | 3 | +------+------+
第三级别:Repeatable Read(可重读):
这是InnoDB引擎默认的事务隔离级别,可以解决不可重复读的问题,但是会引起幻读的问题,当用户读取某一范围的数据行时,另一个事务又在该范围插入了新的一条数据,当用户再读取改范围的数据行时,会发现有新的“幻影”行
#事务A:启动一个事务 start transaction; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +------+------+ #事务B:开启一个新事务(那么这两个事务交叉了)
在事务B中更新数据,并提交 start transaction; update tx set num=10 where id=1; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | | 2 | 2 | | 3 | 3 | +------+------+ commit; #事务A:这时候即使事务B已经提交了,但A能不能看到数据变化? select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题) | 2 | 2 | | 3 | 3 | +------+------+ #事务A:只有当事务A也提交了,它才能够看到数据变化,就会发现提交前和提交后的数据不一致,就出现了幻读
第四级别:Serializable(可串行化):最高的隔离级别,在每个读的数据行上加上共享锁,可能导致大量的超时现象和锁竞争
#事务A:开启一个新事务
start transaction;
#事务B:在A没有commit之前,这个交叉事务是不能更改数据的
start transaction;
insert tx values('4','4');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
update tx set num=10 where id=1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
总结: