1 IO多路复用的概念
原生socket客户端在与服务端建立连接时,即服务端调用accept方法时是阻塞的,同时服务端和客户端在收发数据(调用recv、send、sendall)时也是阻塞的。原生socket服务端在同一时刻只能处理一个客户端请求,即服务端不能同时与多个客户端进行通信,实现并发,导致服务端资源闲置(此时服务端只占据 I/O,CPU空闲)。
现在的需求是:我们要让多个客户端连接至服务器端,而且服务器端需要处理来自多个客户端请求。很明显,原生socket实现不了这种需求,此时我们该采用什么方式来处理呢?
解决方法:采用I/O多路复用机制。在python网络编程中,I/O多路复用机制就是用来解决多个客户端连接请求服务器端,而服务器端能正常处理并响应给客户端的一种机制。书面上来说,就是通过1种机制:可以同时监听多个文件描述符,一旦描述符就绪,能够通知程序进行相应的读写操作。
I/O多路复用是指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
1.1 linux中的IO多路复用
|
(1)select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。 select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。 select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。 另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大 量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。 (2)poll poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。 poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。 另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候 将 再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。 (3)epoll 直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。 epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。 epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描 述符数量的 值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在 系统调用时复制的开销。 另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll 中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某 个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。 |
1.2 python中的IO多路复用
|
Python中有一个select模块,其中提供了:select、poll、epoll三个方法,分别调用系统的 select,poll,epoll从而实现IO多路复用。 Windows Python:提供: select Mac Python:提供: select Linux Python:提供: select、poll、epoll |
2 python中的IO多路复用
IO多路复用有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select /epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
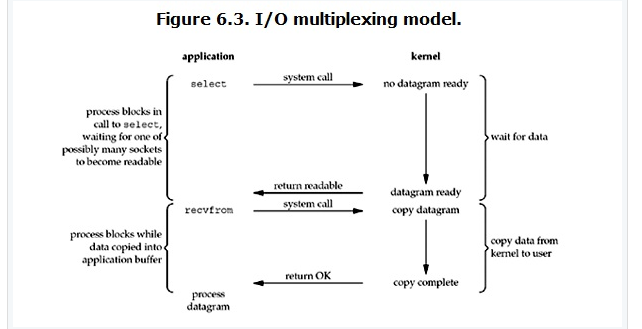
注意:网络操作、文件操作、终端操作等均属于IO操作,对于windows只支持Socket操作,其他系统支持其他IO操作,但是无法检测普通文件操作,自动检测文件是否已经变化。普通文件操作,所有系统都是完成不了的,普通文件是属于I/O操作!但是对于python来说文件变更,python是监控不了的,所以我们能用的只有是“终端的输入输出,Socket的输入输出”
2.1 select方法
select 的中文含义是”选择“,select机制也如其名,监听一些 server 关心的套接字、文件等对象,关注他们是否可读、可写、发生异常等事件。一旦出现某个 select 关注的事件,select 会对相应的套接字或文件进行特定的处理,这就是 select 机制最主要的功能。
select 机制可以只使用一个进程/线程来处理多个socket或其他对象,因此又被称为I/O复用。
关于select机制的进程阻塞形式,与普通的套接字略有不同。socket对象可能阻塞在accept(),recvfrom()等方法上,以recvfrom()方法为例,当执行到socket.recvfrom()这一句时,就会调用一个系统调用询问内核:client/server发来的数据包准备好了没?此时从进程空间切換到内核地址空间,内核可能需要等数据包完全到达,然后将数据复制到程序的地址空间后,recvfrom()才会返回,接下来进程继续执行,对读取到的数据进行必要的处理。
而使用select函数编程时,同样针对上面的recvfrom()方法,进程会阻塞在select()调用上,等待出现一个或多个套接字对象满足可读事件,当内核将数据准备好后,select()返回某个套接字对象可读这一条件,随后再调用recvfrom()将数据包从内核复制到进程地址空间。
所以可见,如果仅仅从单个套接字的处理来看,select()反倒性能更低,因为select机制使用两个系统调用。但select机制的优势就在于它可以同时等待多个fd就绪,而当某个fd发生满足我们关心的事件时,就对它执行特定的操作。
句柄列表11, 句柄列表22, 句柄列表33 = select.select(句柄列表1, 句柄列表2, 句柄列表3, 超时时间)
参数: 可接受四个参数(前三个必须)
返回值:三个列表
select方法用来监视文件句柄,如果句柄发生变化,则获取该句柄。
1、当 参数1 序列中的句柄发生可读时(accetp和read),则获取发生变化的句柄并添加到 返回值1 序列中
2、当 参数2 序列中含有句柄时,则将该序列中所有的句柄添加到 返回值2 序列中
3、当 参数3 序列中的句柄发生错误时,则将该发生错误的句柄添加到 返回值3 序列中
4、当 超时时间未设置,则select会一直阻塞,直到监听的句柄发生变化
5、当 超时时间=1时,那么如果监听的句柄均无任何变化,则select会阻塞1秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
|
由于select()接口可以同时对多个句柄进行读状态、写状态和错误状态的探测,所以可以很容易构建为多个客户端提供独立问答服务的服务器系统。这里需要指出的是,客户端的一个connect()操作,将在服务器端激发一个“可读事件”,所以 select() 也能探测来自客户端的connect()行为。
上述模型中,最关键的地方是如何动态维护select()的三个参数。程序员需要检查对应的返回值列表,以确定到底哪些句柄发生了事件。所以如果select()发现某句柄捕捉到了“可读事件”,服务器程序应及时做recv()操作,并根据接收到的数据准备好待发送数据,并将对应的句柄值加入句柄序列1,准备下一次的“可写事件”的select()探测。同样,如果select()发现某句柄捕捉到“可写事件”,则程序应及时做send()操作,并准备好下一次的“可读事件”探测准备。


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import select 5 import sys 6 7 while True: 8 readable, writeable, error = select.select([sys.stdin,],[],[],1) 9 '''select.select([sys.stdin,],[],[],1)用到I/O多路复用,第一个参数是列表,sys.stdin是系统标准输入的文件描述符, 就是打开标准输入终端返回的文件描述符,一旦终端有输入操作,select就感知sys.stdin描述符的变化,那么会将变化的描述符sys.stdin添加到返回值readable中;如果终端一直没有输入,那么readable他就是一个空列表 10 ''' 11 if sys.stdin in readable: 12 print 'select get stdin',sys.stdin.readline() 13 ''' 14 注: 15 1、[sys.stdin,]以后不管是列表还是元组,在最后一个元素的后面建议增加一个逗号,(1,) | (1) 这两个有区别吗?是不是第二个更像方法的调用或者函数的调用,加个,是不是更容易分清楚。还有就是在以后写django的配置文件的时候,他是必须要加的。 16 2、select的第一个参数就是要监听的文件句柄,只要监听的文件句柄有变化,那么就会将其加入到返回值readable列表中。 17 3、select最后一个参数1是超时时间,当执行select时,如果监听的文件句柄没有变化,则会阻塞1秒,然后向下继续执行;默认timeout=None,就是会一直阻塞,直到感知到变化 18 ''' 19 ''' 20 when runing the program get error : 21 Traceback (most recent call last): 22 File "E:/study/GitHub/homework/tianshuai/share_3_select_socket.py", line 8, in <module> 23 readable, writeable, error = select.select([sys.stdin,],[],[],1) 24 select.error: (10093, 'Either the application has not called WSAStartup, or WSAStartup failed') 25 26 when windows only use select socket !!!!! 27 '''
1 #/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import time 5 import socket 6 import select 7 8 #生成socket对象 9 sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 10 #绑定IP和端口 11 sk.bind(('127.0.0.1',6666)) 12 #监听,并设置最大连接数为5 13 sk.listen(5) 14 #设置setblocking为False,即非阻塞模式,accept将不在阻塞,如果没有收到请求就会报错 15 sk.setblocking(False) 16 17 while True: 18 rlist, wlist, elist = select.select([sk,],[],[],2) #监听第一个列表的文件描述符,如果其中有文件描述符发生改变,则捕获并放到rlist中 19 for r in rlist: #如果rlist非空将执行,否则不执行 20 conn,addr = r.accept() #建立连接,生成客户端的socket对象以及IP地址和端口号 21 print addr
执行程序,在浏览器中输入地址:127.0.0.1:6666
执行结果如下:
('127.0.0.1', 42510)
1 #/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import time 5 import socket 6 import select 7 8 #生成socket对象 9 sk1 = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 10 #绑定IP和端口 11 sk1.bind(('127.0.0.1',6666)) 12 #监听并设置最大连接数 13 sk1.listen(5) 14 sk1.setblocking(False) #设置setblocking为False,accept将不在阻塞,如果没有收到请求就会报错,即非阻塞模式 15 16 sk2 = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 17 sk2.bind(('127.0.0.1',7777)) 18 sk2.listen(5) 19 sk2.setblocking(False) #设置非阻塞模式 20 21 while True: 22 rlist, wlist, elist = select.select([sk1,sk2,],[],[],2) #监听第一个列表的文件描述符,如果其中有文件描述符发生改变,则捕获并放到rlist中 23 for r in readable_list: 24 conn,address = r.accept() 25 print address
执行程序,在浏览器中分别输入地址:127.0.0.1:6666 127.0.0.1:7777
执行结果如下:
('127.0.0.1', 54509) ('127.0.0.1', 53458)
1 #/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import time 5 import socket 6 import select 7 8 sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 9 sk.bind(('127.0.0.1',6666)) 10 sk.listen(5) 11 sk.setblocking(False) #非阻塞 12 inputs = [sk,] #构造select第一个参数 13 #原因:看上例conn是客户端对象,客户是一直连接着呢,连接的时候状态变了,连接上之后,还是服务端的socket有关吗?是不是的把他改为动态的? 14 15 while True: 16 rlist, wlist, elist = select.select(inputs,[],[],1) #把第一个参数设为列表动态的添加 17 time.sleep(2) #测试使用 18 print "inputs list :",inputs #打印inputs列表,查看执行变化 19 print "file descriptor :",readable_list #打印rlist ,查看执行变化 20 21 for r in rlist: 22 #当客户端第1次连接服务端时 23 if r == sk: 24 conn,address = r.accept() 25 inputs.append(conn) 26 print address 27 else: 28 # 当客户端连接上服务端之后,再次发送数据时 29 client_data = r.recv(1024) 30 r.sendall(client_data)
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import socket 5 6 client = socket.socket() 7 client.connect(('127.0.0.1',6666)) 8 client.settimeout(5) 9 10 while True: 11 client_input = raw_input('please input message:').strip() 12 client.sendall(client_input) 13 server_data = client.recv(1024) 14 print server_data
1 ''' 2 第1点: 3 #定义1个包含服务端文件句柄sk的inputs列表,服务端利用select监听到客户端的请求时(目前对于服务端来说,就是accept和recv请求;对于客户端来说就是connect、send、sendall请求), 4 5 第2点: 6 #最开始服务端select会监听inputs=[sk,],当有新客户端connect请求时,select就会监听到服务端文件句柄sk发生了改变,此时select会把sk赋值给第1个返回值rlist,即rlist=[sk,], 7 8 #执行for循环,当r==sk时,即表示是服务端文件句柄sk发生了变化,此时服务端就会执行accpet,同时返回客户端文件句柄conn以及其IP地址和端口port,再把conn加入到inputs列表中, 9 #便于后面服务端对该客户端的其它请求的监听;当r!=sk时,说明是监听到某个客户端文件句柄发生了变化,即是之前监听到的客户端有新的请求(发送了数据),此时服务端就会recv该数据 10 #如果无任何请求,那么select就不会监听到任何变化,即rlist = [] 11 12 #程序执行的打印结果: 13 14 #1 有1个客户端连接,此后无操作 15 inputs list : [<socket._socketobject object at 0x0000000002C66798>] #初始化时inputs包含了sk对象 16 file descriptor : [<socket._socketobject object at 0x0000000002C66798>] #当客户端有conncet请求时,sk就会发生变化,此时rlist=[sk,] 17 ('127.0.0.1', 62495) #客户端的IP地址和端口号 18 inputs list : [<socket._socketobject object at 0x0000000002C66798>, <socket._socketobject object at 0x0000000002C66800>] #第2次循环时,inputs = [sk,conn1,] 19 file descriptor : [] #第2次循环时rlist = [],因为客户端无任何操作,此时select没有监听到inputs中的文件句柄有任何变化,所以rlist为空 20 21 #2 有1个新客户端连接,即有客户端向服务端发起了一个connect请求,此时sk发生了变化,那么现在inputs = [sk,conn1,conn2] rlist = [sk] 22 #本次循环完成之后再循环的时候inputs = [sk,conn1,conn2,] rlist = [],因为我们没有继续做操作 23 24 #第1个连接请求 25 inputs list : [<socket._socketobject object at 0x0000000002C56798>] #默认只有sk 26 file descriptor : [] 27 inputs list : [<socket._socketobject object at 0x0000000002C56798>] 28 file descriptor : [<socket._socketobject object at 0x0000000002C56798>] #监听到sk发生了变化,表示有新客户端请求 29 ('127.0.0.1', 62539) 30 inputs list : [<socket._socketobject object at 0x0000000002C56798>, <socket._socketobject object at 0x0000000002C56800>] #inputs列表变更为了[sk,conn1] 31 file descriptor : [] #后续无操作,所以rlist=[] 32 33 #第二个链接 34 inputs list : [<socket._socketobject object at 0x0000000002C56798>, <socket._socketobject object at 0x0000000002C56800>] 35 file descriptor : [<socket._socketobject object at 0x0000000002C56798>] #监听到inputs列表中的文件句柄发生了改变 36 ('127.0.0.1', 62548) 37 #加入到inputs列表中 38 inputs list : [<socket._socketobject object at 0x0000000002C56798>, <socket._socketobject object at 0x0000000002C56800>, <socket._socketobject object at 0x0000000002C56868>] 39 file descriptor : [] 40 inputs list : [<socket._socketobject object at 0x0000000002C56798>, <socket._socketobject object at 0x0000000002C56800>, <socket._socketobject object at 0x0000000002C56868>] 41 file descriptor : [] 42 inputs list : [<socket._socketobject object at 0x0000000002C56798>, <socket._socketobject object at 0x0000000002C56800>, <socket._socketobject object at 0x0000000002C56868>] 43 file descriptor : [] 44 '''
1 #优化点:当客户端断开连接时,从inputs列表中删除其文件描述符 2 3 #!/usr/bin/env python 4 # -*- coding:utf-8 -*- 5 6 import socket 7 import select 8 9 sk1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 10 sk1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) 11 sk1.bind(('127.0.0.1',8002)) 12 sk1.listen(5) 13 sk1.setblocking(0) 14 15 inputs = [sk1,] 16 17 while True: 18 readable_list, writeable_list, error_list = select.select(inputs, [], inputs, 1) 19 for r in readable_list: 20 # 当客户端第一次连接服务端时 21 if sk1 == r: 22 print 'accept' 23 request, address = r.accept() 24 request.setblocking(0) 25 inputs.append(request) 26 # 当客户端连接上服务端之后,再次发送数据时 27 else: 28 received = r.recv(1024) 29 # 当正常接收客户端发送的数据时 30 if received: 31 print 'received data:', received 32 # 当客户端关闭程序时 33 else: 34 inputs.remove(r) 35 36 sk1.close()
此处的Socket服务端相比与原生的Socket,他支持当某一个请求不再发送数据时,服务器端不会等待而是可以去处理其他请求的数据。但是,如果每个请求的耗时比较长时,select版本的服务器端也无法完成同时操作。
select参数注解
rlist, wlist, elist = select.select(inputs,[],[],1)
|
对于I/O多路复用,咱们上面的例子就可以了,但是为了遵循select规范需要把读和写进行分离:
#rlist -- wait until ready for reading #等待直到有读的操作
#wlist -- wait until ready for writing #等待直到有写的操作
#xlist -- wait for an ``exceptional condition'' #等待一个错误的情况
|
为了实现读写分离,需要构造一个字典,字典里为每一客户端维护一个队列。收到的信息放到队列里,然后写的时候直接从队列取数据
2.2 Queue 队列
队列的特点:
1 import Queue 2 3 q = Queue.Queue() #调用队列生成对象 4 q.put(1) #存放第一个值到队列 5 q.put(2) #存放第二个值到队列 6 7 print 'get frist one:',q.get() #获取队列的第一个值 8 print 'get second on:',q.get() #获取队列的第二个值
1 q = Queue.Queue() #调用队列生成对象 2 3 q.put(1) #存放第一个值到队列 4 q.put(2) #存放第二个值到队列 5 6 a = q.get() #获取队列的第一个值 7 print 'get frist one:%s' % a 8 b = q.get() #获取队列的第二个值 9 print 'get second one:%s' % b 10 c = q.get()#获取队列的第三个值 11 print 'get third one:%s' % c 12 13 #结果: 14 ''' 15 get frist one:1 16 get second one:2 17 #这里一直在等待着值进来~ 18 '''
1 q = Queue.Queue() #调用队列生成对象 2 3 q.put(1) #存放第一个值到队列 4 q.put(2) #存放第二个值到队列 5 6 a = q.get() #获取队列的第一个值 7 print 'get frist one:%s' % a 8 b = q.get() #获取队列的第二个值 9 print 'get second one:%s' % b 10 c = q.get_nowait()#获取队列的第三个值 ,使用:get_nowait() 11 print 'get third one:%s' % c
1 q = Queue.Queue() #调用队列生成对象
2 try:
3 q.get_nowait()
4 except Queue.Empty as f:
5 print 'The Queue is empty!'
1 q = Queue.Queue(2) #调用队列生成对象 2 3 q.put(1) #存放第一个值到队列 4 print 'put value 1 done' 5 q.put(2) #存放第二个值到队列 6 print 'put vlaue 2 done' 7 q.put(3) #存放第三个值到队列 8 print 'put value 3 done' 9 10 11 #结果: 12 ''' 13 put value 1 done 14 put vlaue 2 done 15 #这里会一直等待~ 16 '''
1 q = Queue.Queue(2) #调用队列生成对象 2 3 q.put(1) #存放第一个值到队列 4 print 'put value 1 done' 5 q.put(2) #存放第二个值到队列 6 print 'put vlaue 2 done' 7 q.put_nowait(3) #存放第三个值到队列,如果使用put_nowait()队列无法存放后会报错! 8 print 'put value 3 done' 9 #结果: 10 ''' 11 put value 1 done 12 put vlaue 2 done 13 #这里会一直等待~
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import select 5 import socket 6 import Queue 7 import time 8 9 sk = socket.socket() 10 sk.bind(('127.0.0.1',6666)) 11 sk.listen(5) 12 sk.setblocking(False) #设置非阻塞 13 inputs = [sk,] #定义一个列表,select第一个参数监听句柄序列,当有变动是,捕获并把socket server加入到句柄序列中 14 outputs = [] #定义一个列表,select第二个参数监听句柄序列,当有值时就捕获,并加入到句柄序列 15 message = {} 16 #message的样板信息 17 #message = { 18 # 'c1':队列,[这里存放着用户C1发过来的消息]例如:[message1,message2] 19 # 'c2':队列,[这里存放着用户C2发过来的消息]例如:[message1,message2] 20 #} 21 22 while True: 23 readable_list, writeable_list, error_list = select.select(inputs,outputs,[],1) 24 #文件描述符可读 readable_list 只有第一个参数变化时候才捕获,并赋值给readable_list 25 #文件描述符可写 writeable_list 只要有值,第二个参数就捕获并赋值给writeable_list 26 #time.sleep(2) 27 print 'inputs:',inputs 28 print 'output:' 29 print 'readable_list:',readable_list 30 print 'writeable_list:',writeable_list 31 print 'message',message 32 for r in readable_list: #当readable_list有值得时候循环 33 if r == sk: #判断是否为链接请求变化的是否是socket server 34 conn,addr = r.accept() #获取请求 35 inputs.append(conn) #把客户端对象(句柄)加入到inputs里 36 message[conn] = Queue.Queue() #并在字典里为这个客户端连接建立一个消息队列 37 else: 38 client_data = r.recv(1024) #如果请求的不是sk是客户端接收消息 39 if client_data:#如果有数据 40 outputs.append(r)#把用户加入到outpus里触发select第二个参数 41 message[r].put(client_data)#在指定队列中插入数据 42 else: 43 inputs.remove(r)#没有数据,删除监听链接 44 del message[r] #当数据为空的时候删除队列~~ 45 for w in writeable_list:#如果第二个参数有数据 46 try: 47 data = message[w].get_nowait()#去指定队列取数据 并且不阻塞 48 w.sendall(data) #返回请求输入给client端 49 except Queue.Empty:#反之触发异常 50 pass 51 outputs.remove(w) #因为第二个参数有值得时候就触发捕获值,所以使用完之后需要移除它 52 #del message[r] 53 print '%s' %('-' * 40)
使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多CPU,同时能够为多客户端提供服务。如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。但这个模型依旧有着很多问题。首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。很多操作系统提供了更为高效的接口,如linux提供了epoll,BSD提供了queue,Solaris提供了/dev/poll ...。如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐。遗憾的是不同的操作系统特供的epoll接口有很大差异,所以使用类似于epoll的接口实现具有较好跨平台能力的服务器程序会比较困难。
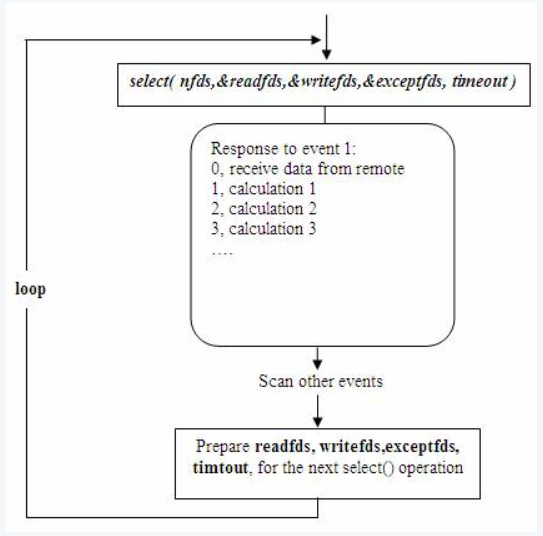
其次,该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的。如下例,庞大的执行体1的将直接导致响应事件2的执行体迟迟得不到执行,并在很大程度上降低了事件探测的及时性。
参考资料:
http://www.cnblogs.com/wupeiqi/articles/5040823.html
http://www.cnblogs.com/luotianshuai/p/5098408.html
http://www.cnblogs.com/Security-Darren/p/4746230.html