一. DRF序列化
django自带有序列化组件,但是相比rest_framework的序列化较差,所以这就不提django自带的序列化组件了。
首先rest_framework的序列化组件使用同from组件有点类似,当反序列化前端返回的数据之后,需要先调用is_valid进行校验,其中也有局部钩子validate_字段名,全局钩子validate,is_valid校验过后才可调用.data与.errors。
rest_framework有两种序列化方式,分别是继承Serializer和ModelSerializer,如果序列化的数据是多条时,一定要指定many=True,不然会报错。many=True与False的区别是前者返回列表套字典,而后者只有一个字典,即就一条数据。
from rest_framework.serializers import Serializer, ModelSerializer
1.1 继承Serializer的序列化
models.py中代码如下:
from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=32) price = models.IntegerField() # db_constraint=False时,一对多表只存在逻辑上的关系,处理数据无需考虑外键关系,但是依旧可以正常使用ORM # on_delete在django1版本中默认是CASCADE,即级联删除。on_delete有四种选择,SET_NULL即外键对应一表 # 数据删除时,将该字段设置为空,需要设置null=True或default # related_name='反向查询的依据名字' # 外键对应的表点该依据名字.all来查询多关系表的数据,不需要表名小写+_set.all来获取 publish = models.ForeignKey("Publish", related_name='books', db_constraint=False, on_delete=models.SET_NULL, null=True) authors = models.ManyToManyField("Author", db_constraint=False) def __str__(self): return self.title class Publish(models.Model): name = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() def __str__(self): return self.name
序列化类BookSerializer如下:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.IntegerField() # source的作用很强大,其中的值相当于self.publish.name, # 当有字段使用choices属性时,可以指定source='get_字段名_display'来直接获取对应的值 # source 如果是字段,会显示字段,如果是方法,会执行方法,不用加括号 publish = serializers.CharField(source='publish.name') # 可以指定一个函数,函数名固定get_字段名,函数return的值就是该字段的值 # read_only是反序列化时不传,write_only是序列化时不显示 author_detail = serializers.SerializerMethodField(read_only=True) # 该函数return的值就是author_detail字段的值 def get_author_detail(self, book_obj): authors = book_obj.authors.all() # 函数内部可以直接调用其他序列化类 return AuthorSerializer(authors, many=True).data # 局部钩子 def validate_title(self, value): # value是当前的title的值 from rest_framework import exceptions if 'h' in value: # 这是将校验未通过的信息存入序列化obj.errors中 raise exceptions.ValidationError('h是不可能h的') return value # 全局钩子 def validate(self, attrs): # attrs是包含了所有字段及数据的字典 from rest_framework import exceptions if attrs.get('title') == attrs.get('price'): return attrs else: raise exceptions.ValidationError('书名怎么和价格一样')
注意,无论是局部钩子还是全局钩子函数,都要序列化对象走is_valid方法时才会触发,而且全局要所有需要序列化的字段通过校验才会触发。
上述需要的AuthorSerializer如下:
# 作者Author序列化类 class AuthorSerializer(serializers.Serializer): name = serializers.CharField(max_length=32) age = serializers.IntegerField()
在表中写入数据后,在视图views.py中写CBV继承ListAPIView:
from rest_framework.generics import ListAPIView from app01 import models from app01 import app01serializers # Create your views here. class BookAPIView(ListAPIView): queryset = models.Book.objects serializer_class = app01serializers.BookSerializer
然后开路由:
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^books/', views.BookAPIView.as_view()), ]
随后用postman测试该接口:
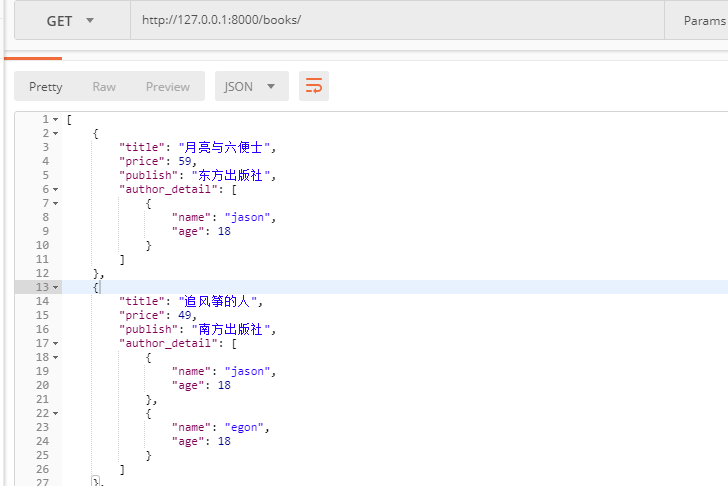
这里要注意,如果是前端往后端提交post请求创建新的数据时,要反序列化,然后调用is_valid校验数据,之后才能调用.dada与.errors。因为继承Serializer是没有指定表的,我们需要在对应的序列化类中重写create方法,将.dada当create的参数传入,然后create中写保存的逻辑,如果涉及到多表,那么要全靠自己逻辑去写了,在视图中执行is_valid前将其他表需要的参数取出执行保存操作即可。
反序列时需要把将参数指定给data:
bs=BookSerializer(data=request.data)
如果intence参数和data参数都给予了值,那么会执行更新操作:
def put(self, request, pk): book_obj = models.Book.objects.filter(pk=pk).first() bs=BookSerializers(data=request.data, instance=book_obj) if bs.is_valid(): bs.save() # update return Response(bs.data) else: return Response(bs.errors)
1.2 继承ModelSerializer的序列化
继承Modelserializer的序列化比较方便,因为不需要逐个写字段及字段的类型等。
序列化类如下:
class BookSerializer(serializers.ModelSerializer): # 生成publish_detail的第三种方式 publish = PublishSerializer() class Meta: model = models.Book # fields = '__all__' 所有字段序列化,不过一般我们不会使用该方式 # 一般采用下列方式,里面可以填表拥有的字段, # 也可以写该表中外键字段、多对多表正向或反向对应点语法采用的字段 # 其中反向查询时我们一般采用.表名小写的方式,可以在Foreign中设置字段related_name='反向查询点语法后的名称' # 比如Book表中外键字段publish设置属性related_name='books',那么Publish表反向查询书籍时, # .books_all()即可拿到该出版社出版的所有书籍对象(不然要写.book_set.all()) fields = ['title', 'price', 'publish', 'author_detail'] # exclude=('title',) #拿出除了title的所有字段,不能跟fields同时用 # depth = 1 #深度控制,写 几 往里拿几层,层数越多,响应越慢,官方建议0--10之间,个人建议最多3层
继承ModelSerializer的类也可以写全局钩子、局部钩子,以及对字段进行处理,不过已订购要写在class Meta的外面。
fields中可以写模型表带有的字段,包含外键字段及ManyToMany字段,当指定了related_name时,反向查询的表可以写related_name指定的名字来访问另一张表。
这里提一嘴,rest_framework提供了深度属性depth,但是不建议使用,因为不可控性太强。一般涉及到多表时,我们都在模型表中进行,比如此处的author_detail,是多对多关系表中book对应的所有author对象,我们在Book模型表中增加以下方法:
@property def author_detail(self): result_list = [] authors = self.authors.all() for author in authors: dic = {'name': author.name, 'age': author.age} result_list.append(dic) return result_list
上面publish也可以在模型表中定义,比如写publish_detail:
# 生成publish_detail方式一 @property def publish_detail(self): publish_obj = self.publish return {'name': publish_obj.name, 'email': publish_obj.email} # 生成publish_detail方式二 @property def publish_detail(self): from app01 import app01serializers publish_obj = self.publish return app01serializers.PublishSerializer(publish_obj).data
然后将序列化类中的publish改为publish_detail,用postman测试接口:
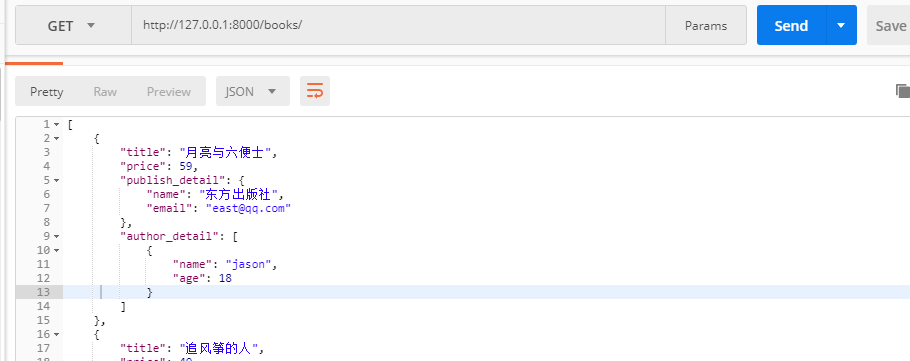
结果是一样的,继承ModelSerializer因为需要指定模型表,所有不需要重写create方法,直接调用.save方法即可。
1.3 模型层中参数的补充
比如当我们创建外键关系与多对多关系表时,django 1.x版本默认都是级联删除的,即on_delete=CASCADE,而django 2.x版本需要自己指定。
on_delete一共有四个值可以选择:
1. on_delete = models.SET_NULL # 关联表字段删除后,该ForeignKey字段的值置为空,需要设置null=True或者是设置default 2. on_delete = models.SET_DEFAULT # 关联表字段删除后,该ForeignKey字段的值置为默认值,需要设置default字段 3. on_delete = models.DO_NOTHING # 关联表字段删除后,该ForeignKey字段的值不变 4. on_delete = models.CASCADE # 关联表字段删除后,级联删除
Foreign与ManyToMany字段还有db_constraint与related_name字段。指定db_constraint=False时,一对多的表只存在逻辑上的关系(此时数据库如navicat中表关系图它们之间的线会断开),处理数据无需考虑外键关系,不过依旧可以使用ORM正常操作正反向查询等。
指定related_name字段时,反向查询无需按表名小写的方式,直接点该related_name定义的字段即可。举例,比如Book表与Author表一对多,外键在Book表中,那么Author查询Book表的数据就是反向查询,需要author_obj.book_set.all()获取作者对应的所有书籍数据。这时指定related_name='books',那么只需采用author_obj.books.all()即可。
如果不清楚可以再看看该博客:https://www.cnblogs.com/liuqingzheng/articles/9766376.html