pycharm里安装beautifulSoup以及lxml,才能使爬虫功能强大。
做网页爬虫需要,《网页解析器:从网页中提取有价值数据的工具
http://blog.csdn.net/ochangwen/article/details/51959754
在爬取数据的时候,有两种方式post和get,这两种方式的区别和联系。
-------------------------------------------------------------------------------------------
https://www.jianshu.com/p/4231173ccc83
网络爬虫(又被称为网页蜘蛛),网络机器人,是一种按照一定的规则,自动地抓信息的程序或者脚本。假设互联网是一张很大的蜘蛛网,每个页面之间都通过超链接这根线相互连接,那么我们的爬虫小程序就能够通过这些线不断的搜寻到新的网页。
Python作为一种代表简单主义思想的解释型、面向对象、功能强大的高级编程语言。它语法简洁并且具有动态数据类型和高层次的抽象数据结构,这使得它具有良好的跨平台特性,特别适用于爬虫等程序的实现,此外Python还提供了例如Spyder这样的爬虫框架,BeautifulSoup这样的解析框架,能够轻松的开发出各种复杂的爬虫程序。
在这篇文章中,使用Python自带的urllib和BeautifulSoup库实现了一个简单的web爬虫,用来爬取每个URL地址及其对应的标题内容。
- 爬虫算法从输入中读取的一个URL作为初始地址,向该地址发出一个Request请求。
- 请求的地址返回一个包含所有内容的,将其存入一个String变量,使用该变量实例化一个BeautifulSoup对象,该对象能够将内容并且将其解析为一个DOM树。
根据自己的需要建立正则表达式,最后借助HTML标签从中解析出需要的内容和新的URL,将新的放入队列中。 - 对于目前所处的URL地址与爬去的内容,在进行一定的过滤、整理后会建立索引,这是一个单词-页面的存储结构。当用户输入搜索语句后,相应的分词函数会对语句进行分解获得关键词,然后再根据每个关键词查找到相应的URL。通过这种结构,可以快速的获取这个单词所对应的地址列表。在这里使用树形结构的存储方式,Python的字典和列表类型能够较好的构建出单词词典树。
- 从队列中弹出目前的URL地址,在爬取队列不为空的条件下,算法不断从队列中获取到新的网页地址,并重复上述过程。
环境:
- Python 3.5 or Anaconda3
- BeautifulSoup 4
未完待续
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
按照网上的很多安装包和安装教程 最后总会报错 说我安装的beautifulSoup版本不对 来来回回折腾一周 突然发现我太蠢了
其实可以直接利用一条命令搞定 但前提是要安装了pip 这样利用pip就可以直接安装最新版本的beautifulSoup了
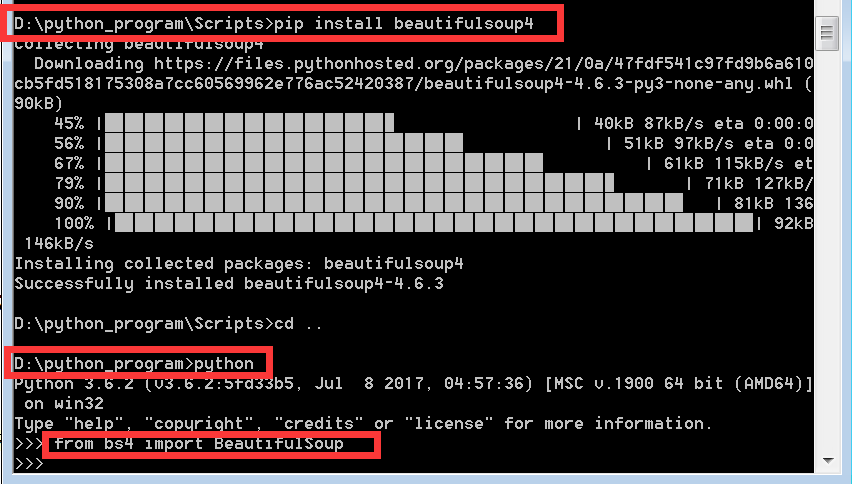
待这些模块以cmd的命令安装成功以后 执行文件还是会出错
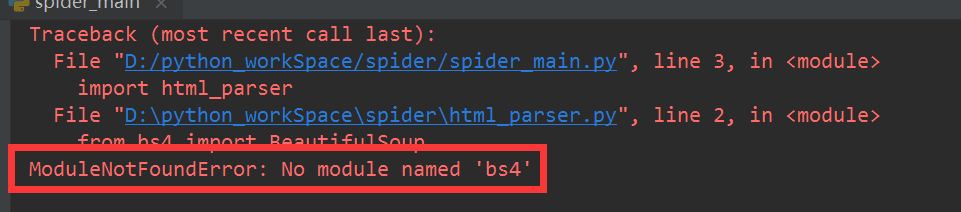
类似No module named 'bs4'等错误的解决方法
参看链接 安装pycharm的各个模块 https://www.cnblogs.com/xisheng/p/7856334.html
网页爬虫原理
https://blog.csdn.net/hanchaobiao/article/details/72860523