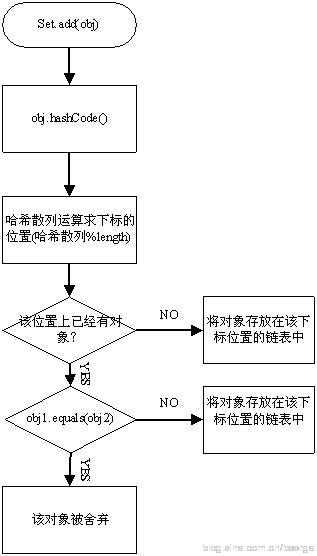
HashSet的底层用哈希散列表来存储对象(默认长度为16的数组),
假如:
Set set=new HashSet(); set.add(obj);
内部存储过程为:定义h=obj.hashCode,得到obj对象的哈希码h,再对h进行hash散列运算,对数组长度进行求余,假如长度为16,则返回一个0-15之间的值,然后这个值就是存在HashSet数组中的下标。如果下标位置没有对象(不起冲突),则把obj加到该位置;如果已近有对象(起冲突),则用equals判断两对象是否相等,相等则舍弃obj,不相等,则把obj以节点的方式加在该对象下面。
所以,只有覆盖了对象的equals方法和hashCode方法,让此方法按自己的算法运算的话才能算是相同的对象,覆盖hashCode方法的原则:
原则1:让equals相等的对象返回相同的hashCode(为了过滤掉相等的元素)
原则2:尽量保证equals不相同的对象返回不同的hashCode(为了添加不同的元素)