声明:本文是对 xuetangx 清华大学 丁俊晖 老师 数据结构 课程的个人总结。
说到有序向量的查找算法,首先蹦入脑海的肯定是二分查找算法。
然而,即便是简单的二分查找也没有想象的那么简单。
首先考虑一些特殊情形:
1、查找的元素不存在; 2、要查找的元素值存在多个。
当然,对于不存在的情况,我们可以简单的返回一个 -1 代表未查找到,但很多时候,这样做往往是不够的。比如说,我们在调用查找之后,很有可能紧接着需要考虑插入一个值使原向量依然保持有序,而如果我们仅仅只是返回一个未查找到的 -1 ,显然是不足以作为插入操作的有效依据的。所以,即使是查找失败,我们也需要给出让新元素插入的适当位置,给后续操作作为参考的依据。同样,即便是有重复的元素,我们也需要返回一个有效的位置。
统一定义一个语义:(假定向量是从小到大有序排列的,e为待查找的元素)

(注意对向量两边都插入哨兵这样对线性数据结构通用的使用技巧,假定为一些特殊的值,无穷小、无穷大等等)
这样的语义定义是十分优秀的:因为它可以保持这个语序向量的稳定性:即在保持向量有序性的同时,也同时保持了相同元素按照插入的先后次序。
算法实现:
版本A:


当然,这里未查找到还是简明的返回 -1。
值得注意的就是中间的 if 语句,要注意的有:
1、两个条件都统一采用 “<” 号的方式,这是一种良好的习惯,便于阅读,一看就知道两元素的大小关系,即 小的在左边,大的在右边,符合人们的日常思维习惯,和我们通常画的图也是吻合的。也相当于 A[mi] 是一个界桩,e 在左右哪个区间一目了然。
2、e 在左区间和在右区间需要的比较次数是不同的。当 e 在左区间,只需要一次比较,即执行 hi = mi;而 e 在右区间,要比较两次后,才执行 lo = mi + 1。注意,大小比较操作相对于等否比较以及赋值操作来讲,效率都是很低的。
显然,这个算法渐进意义上的复杂度是 O(logn) 的。
我们现在从更加细微的地方来考察它的复杂度,也就是渐进复杂度 logn 前面的常系数。
关键在于,我们每次选取 mi 的依据都是取 lo 和 hi 的中点,也就是我们粗略的考虑,想要使两边都趋于平衡,这是很容易理解的。
当然,这里的前提是,每一个元素出现的概率是相等的。
可以证明,如果 mi 每次都取中点,复杂度大致为 O(1.50 logn) 的。
实际上,这还有可以改进的空间。
对于我们版本A的实现,左右区间并不是平衡的,也就是上面所说的要注意的第二点,每次进入右区间都比左区间要多比较一次。
即:

很自然地,我们会考虑尽可能的让待查找的目标项落入左边区间,这样就显然地可以减少比较的次数。
成本高的我们希望做的少,而成本底的我们希望做的多。
搜索树对比像这样:
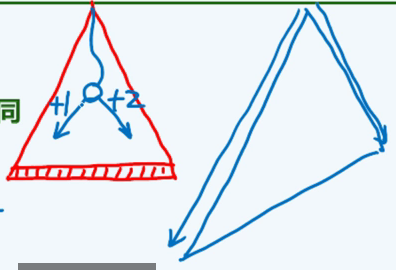

很自然,我们考虑改进。而很有意思的是,这个改进跟 Fibonacci 数密切相关(而 Fibonacci 数跟 黄金分割点 又有着神秘的密切关联)。
改进的关键在于,我们每次将 mi 选取在 lo 和 hi 的较大的黄金分割点(0.6180339)处,也即 Fibonacci 数的 a(n-1)/a(n) 处。
这也就是 Fibonacci Search:
具体实现:(注意区间 [lo, hi) 都是左闭右开的)

实际上,上述两个查找版本的本质不同就是 mi 轴点的选取位置不同,那到底选取到哪常系数上是最优的呢?
数学上的证明:

也就是黄金分割点。所以 Fibonacci Search 实际上已经对常系数的优化达到了最优。
反思以上的过程,既然我们注意到了版本A中造成效率略低的原因是左右分支的转向代价不平衡,那么我们为什么不将两者做得平衡呢?
也就是在任何一个位置,无论最后是向左还是向右,都只需要一次比较。
这样,我们每一次迭代都只能有两个分支而不是版本A的三个,也就是隐藏版本A中 a[mi] 与 e 相等那个分支。
具体来说:
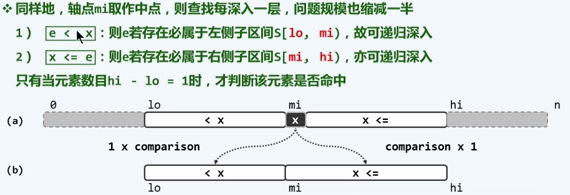
作为牺牲的是,我们不能立即判断出当前元素是否和目标元素相等,必须等到最后区间宽度变为 1 才能真正的判断。
但毕竟,正好相等的情况对比所有情况概率是极低的,整体上而言,我们相当于每次减少了一次比较,是很可观的。
二分查找,版本B实现:(注意边界哨兵)

实际上,以上的各个版本,并没有完全实现我们之前所约定的语义:返回不大于 e 的最后一个元素(包含哨兵)。
在版本B的基础上,我们可以略作调整得到版本C:

(mi 更好的计算方式是 lo + ((hi - lo) >> 1),防止加法运算溢出)
虽然看起来和版本B差别不大,实际上很多细节有着本质上的差别:

此版本并没有任何算法上的漏洞和差错。
正确性分析:
算法的单调性是不言而喻的,问题的规模都能有效的减少。
而对于不变性:
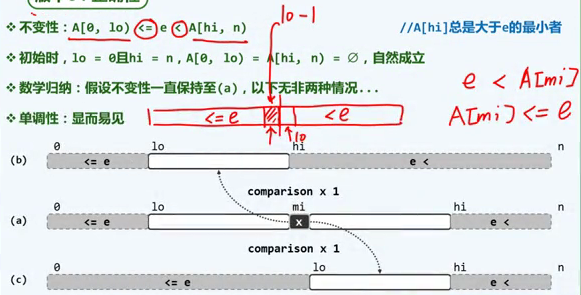
每一次迭代并未改变不变性,最后迭代到区间为空即退出循环,单调性也没有问题。
而最后返回的 --lo 也正是我们符合语义的结果。
与之对偶的“返回大于等于目标元素的最小的元素的位置(即目标元素所在位置(查找到时)或 插入目标元素后向量依然有序的位置(未查找到时))”:
1 class Solution: 2 # @param {integer[]} nums 3 # @param {integer} target 4 # @return {integer} 5 def searchInsert(self, nums, target): 6 lo, hi = -1, len(nums) - 1 7 while lo < hi: 8 mi = (lo + hi + 1) >> 1 9 if target <= nums[mi]: 10 hi = mi - 1 11 else: 12 lo = mi 13 return hi + 1
来自:https://leetcode.com/problems/search-insert-position/
继续考虑,
之前我们的版本,都是未考虑待查找元素值以及区间元素分布规律的。
假设我们的元素分布都是 均匀且独立 的随机分布,

这里给了我们另一种思路,即不一定每次都固定的选取 mi 相对于 lo 和 hi 的值,而是可以根据具体值来动态的确定 mi 。
这就是 插值查找:

注意我们的前提假设,如果不满足,有可能退化成 线性的顺序查找, 即 O(n) 的。
满足的情况下,则可以极快的收敛,甚至在第一次猜测的时候就直接命中。
而对于每次的 lo 和 hi 的确定,应遵循以下原则:
“严格地说,在插值查找过程中,向左和向右深入时,取整的方向应该不同。具体地:
- 移动lo时,向上取整(ceiling)
- 移动hi时,向下取整(floor)”
原因是为了保证问题规模严格缩小,而不致原地踏步。也就是说,lo和hi至少其一会因此移动(并彼此靠拢)。采用不同的去整方向,即可保证这一点,也就是保证算法的单调性。
插值查找算法性能分析:
有一个结论,平均情况:每经过一次比较,n 缩至 sqrt(n)。
最后可得出是 O(loglogn) 的复杂度。
怎样分析的呢?
我们并希望过多的使用准确的数学分析,而是学会如何去进行估算。
对于这个例子:
对于区间长度 n ,用二进制打印出来的长度是 logn。
而每一次将 n 变为 sqrt(n), 二进制打印宽度即变成了 1/2*logn。
即 字宽折半。
如果说 二分查找 是对 n 的数值每次折半的话,那 插值查找 实际上是对 n 的二进制位宽度来做二分查找。
二分查找的迭代次数,我们知道是 logn 的,而 长度是 logn 的,所以最后插值查找的迭代次数就是 loglogn 的。
这种字宽折半的,不用数学进行的,宏观的,把握大趋势的分析,正是我们需要锻炼的。
实际上,除非查找区间宽度极大,或者比较操作成本极高,改进并不明显,而且存在上述所说的在局部区域或者由于分布情况插值算法被“蒙骗”的情况,而计算 mi 的值需要用到乘除,也不仅仅像二分查找只要做加减法。
更加完美的方案是:
