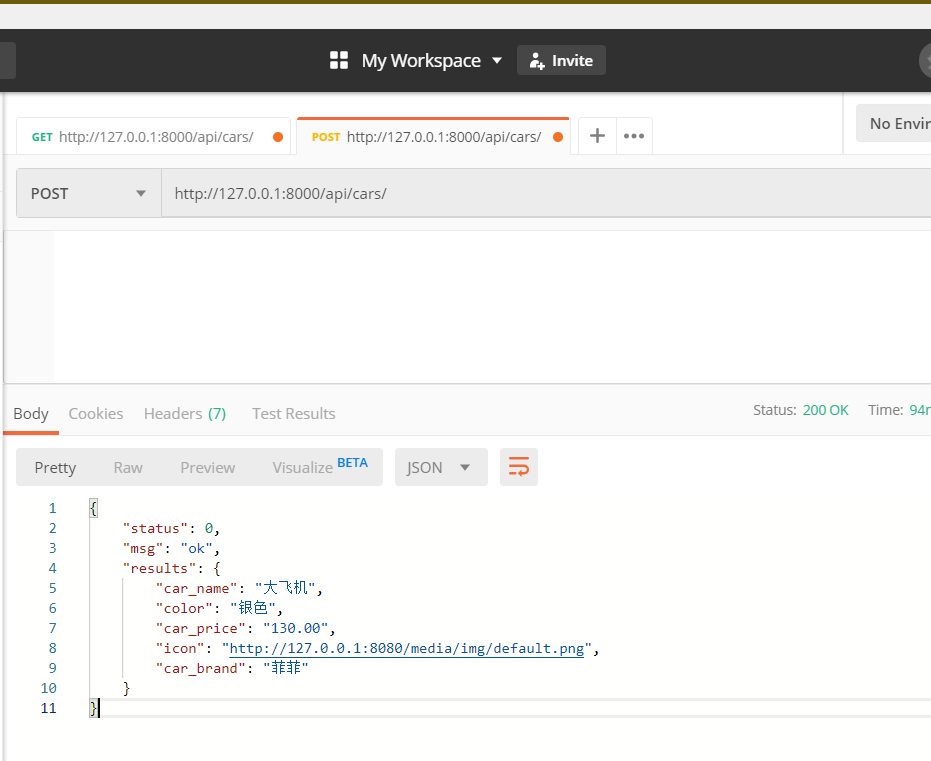
Views
from rest_framework.views import APIView
from rest_framework.response import Response
from django.conf import settings
from . import models
# 一、自定义序列化过程
class UserV1APIView(APIView):
# 单查群查
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
user_dic = models.User.objects.filter(is_delete=False, pk=pk).values('username', 'sex', 'img').first()
if not user_dic:
return Response({
'status': 1,
'msg': 'pk error',
}, status=400)
user_dic['img'] = '%s%s%s' % (settings.BASE_URL, settings.MEDIA_URL, user_dic.get('img'))
return Response({
'status': 0,
'msg': 'ok',
'results': user_dic
})
else:
user_query = models.User.objects.filter(is_delete=False).values('username', 'sex', 'img').all()
for user_dic in user_query:
user_dic['img'] = '%s%s%s' % (settings.BASE_URL, settings.MEDIA_URL, user_dic.get('img'))
user_list = list(user_query)
return Response({
'status': 0,
'msg': 'ok',
'results': user_list
})
# 二、drf序列化过程
# 视图类序列化过程
# 1)ORM操作得到数据
# 2)将数据序列化成可以返回给前台的数据
# 3)返回数据给前台
# 视图类反序列化过程
# 1)从请求对象中获取前台提交的数据
# 2)交给序列化类完成反序列化(数据的校验)
# 3)借助序列化类完成数据入库
# 4)反馈给前台处理结果
from . import serializers
class UserV2APIView(APIView):
# 单查群查
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
user_obj = models.User.objects.filter(is_delete=False, pk=pk).first()
if not user_obj:
return Response({
'status': 1,
'msg': 'pk error',
}, status=400)
user_ser = serializers.UserSerializer(user_obj, many=False) # many默认为False
user_obj_data = user_ser.data
return Response({
'status': 0,
'msg': 'ok',
'results': user_obj_data
})
else:
# 将对象对外提供的字段,已经整个序列化过程封装,形成序列化类
user_query = models.User.objects.filter(is_delete=False).all()
user_ser = serializers.UserSerializer(user_query, many=True)
user_list_data = user_ser.data
return Response({
'status': 0,
'msg': 'ok',
'results': user_list_data
})
# 单增
def post(self, request, *args, **kwargs):
request_data = request.data
user_ser = serializers.UserDeSerializer(data=request_data)
if user_ser.is_valid():
# 入库
user_obj = user_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.UserSerializer(user_obj).data # 将入库得到的user对象重新序列化的数据返回给前台
})
else:
return Response({
'status': 1,
'msg': user_ser.errors,
})
class UserV3APIView(APIView):
# 单查群查
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
user_obj = models.User.objects.filter(is_delete=False, pk=pk).first()
if not user_obj:
return Response({
'status': 1,
'msg': 'pk error',
}, status=400)
user_ser = serializers.UserModelSerializer(user_obj, many=False)
return Response({
'status': 0,
'msg': 'ok',
'results': user_ser.data
})
else:
user_query = models.User.objects.filter(is_delete=False).all()
user_ser = serializers.UserModelSerializer(user_query, many=True)
return Response({
'status': 0,
'msg': 'ok',
'results': user_ser.data
})
# 单增
def post(self, request, *args, **kwargs):
user_ser = serializers.UserModelSerializer(data=request.data)
if user_ser.is_valid():
# 入库
user_obj = user_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.UserModelSerializer(user_obj).data
})
else:
return Response({
'status': 1,
'msg': user_ser.errors,
})
serializers
from rest_framework import serializers
from django.conf import settings
from . import models
""" 序列化总结
1)设置序列化字段,字段名与字段类型要与处理的model类属性名对应(只参与序列化的类型不需要设置条件)
2)model类中有的字段,但在序列化中没有对应字段,该类字段不参与序列化
3)自定义序列化字段(方法一),字段类型为SerializerMethodField(),值有 get_自定义字段名(self, model_obj) 方法提供,
一般值都与参与序列化的model对象(model_obj)有关
"""
class UserSerializer(serializers.Serializer):
# 1)字段名与字段类型要与处理的model类对应
# 2)不提供的字段,就不参与序列化给前台
# 3)可以自定义序列化字段,采用方法序列化,方法固定两个参数,第二个参数就是参与序列化的model对象
# (严重不建议自定义字段名与数据库字段名重名,由get_自定义字段名方法的返回值提供字段值)
username = serializers.CharField()
# sex = serializers.IntegerField()
# sex = serializers.SerializerMethodField() # 不建议这样命名
gender = serializers.SerializerMethodField()
def get_gender(self, obj):
return obj.get_sex_display()
# 注:在高级序列化与高级视图类中,drf默认帮我们处理图片等子资源
icon = serializers.SerializerMethodField()
def get_icon(self, obj):
return '%s%s%s' % (settings.BASE_URL, settings.MEDIA_URL, obj.img)
""" 反序列化总结
1)系统校验字段与自定义校验字段定义没有区别:字段 = serializers.字段类型(条件)
2)自定义校验字段是不能直接入库的,需要设置入库规则,或将其移除不入库(这类字段就是参与全局校验用的)
3)所有字段都可以设置对应局部钩子进行校验,钩子方法 validate_字段名(self, 字段值value)
规则:成功直接返回value,失败抛出校验失败信息ValidationError('错误信息')
4)一个序列化类存在一个全局钩子可以对所有字段进行全局校验,钩子方法 validate(self, 所有字段值字典attrs)
规则:成功直接返回attrs,失败抛出校验失败信息ValidationError({'异常字段', '错误信息'})
5)重写create方法实现增入库,返回入库成功的对象
6)重写update方法实现改入库,返回入库成功的对象
"""
class UserDeSerializer(serializers.Serializer):
# 系统校验字段
username = serializers.CharField(min_length=3, max_length=16, error_messages={
'min_length': '太短',
'max_length': '太长'
})
password = serializers.CharField(min_length=3, max_length=16)
# 不写,不参与反序列化,写就必须参与反序列化(但可以设置required=False取消必须)
# required=False的字段,前台不提供,走默认值,提供就一定进行校验;不写前台提不提供都采用默认值
sex = serializers.BooleanField(required=False)
# 自定义校验字段:从设置语法与系统字段没有区别,但是这些字段不能参与入库操作,需要在全局钩子中,将其取出
re_password = serializers.CharField(min_length=3, max_length=16)
# 局部钩子:
# 方法就是 validate_校验的字段名(self, 校验的字段数据)
# 校验规则:成功直接返回value,失败抛出校验失败信息
def validate_username(self, value):
if 'g' in value.lower():
raise serializers.ValidationError('名字中不能有g')
return value
# 全局钩子:
# 方法就是 validate(self, 所有的校验数据)
# 校验规则:成功直接返回attrs,失败抛出校验失败信息
def validate(self, attrs):
password = attrs.get('password')
re_password = attrs.pop('re_password')
if password != re_password:
raise serializers.ValidationError({'re_password': '两次密码不一致'})
return attrs
# 在视图类中调用序列化类的save方法完成入库,Serializer类能做的增入库走create方法,改入库走update方法
# 但Serializer没有提供两个方法的实现体
def create(self, validated_data):
return models.User.objects.create(**validated_data)
# instance要被修改的对象,validated_data代表校验后用来改instance的数据
def update(self, instance: models.User, validated_data):
# 用户名不能被修改
validated_data.pop('username')
models.User.objects.filter(pk=instance.id).update(**validated_data)
return instance
# 核心:单表序列化与反序列化操作
""" ModelSerializer类序列化与反序列化总结
1)序列化类继承ModelSerializer,所以需要在配置类Meta中进行配置
2)model配置:绑定序列化相关的Model表
3)fields配置:采用 插拔式 设置所有参与序列化与反序列化字段
4)extra_kwargs配置:
划分系统字段为三种:只读(read_only)、只写(write_only)、可读可写(不设置)
字段是否必须:required
选填字段:在extra_kwargs进行配置,但不设置required,且有默认值
5)自定义序列化字段:
第一种(不提倡):在序列化类中用SerializerMethodField()来实现
第二种(提倡):在模型类中用@property来实现,可插拔
6)自定义反序列化字段:
同Serializer类,且规则只能在此声明中设置,或是在钩子中设置,在extra_kwargs中对其设置的无效
自定义反序列化字段与系统字段,设置规则一样,所以必须设置 write_only
7)局部钩子,全局钩子同Serializer类
8)不需要重写create和update方法
"""
class UserModelSerializer(serializers.ModelSerializer):
# 第一种自定义序列化字段:该字段必须在fields中设置
# gender = serializers.SerializerMethodField()
# def get_gender(self, obj):
# return obj.get_sex_display()
# 自定义反序列化字段同Serializer类,且规则只能在此声明中设置,或是在钩子中设置,
# 在extra_kwargs中对其设置的无效
# 注:自定义反序列化字段与系统字段,设置规则一样,所以必须设置 write_only
re_password = serializers.CharField(min_length=3, max_length=16, write_only=True)
class Meta:
model = models.User
# fields采用 插拔式 设置所有参与序列化与反序列化字段
fields = ('username', 'gender', 'icon', 'password', 'sex', 're_password')
extra_kwargs = {
'username': { # 系统字段不设置read_only和write_only,默认都参加
'min_length': 3,
'max_length': 10,
'error_messages': {
'min_length': '太短',
'max_length': '太长'
}
},
'gender': {
'read_only': True, # 自定义的序列化字段默认就是read_only,且不能修改,可以省略
},
'password': {
'write_only': True,
},
'sex': { # 像sex有默认值的字段,为选填字段('required': True可以将其变为必填字段)
'write_only': True,
# 'required': True
}
}
# 局部全局钩子同Serializer类,是与 Meta 同缩进的
def validate_username(self, value):
if 'g' in value.lower():
raise serializers.ValidationError('名字中不能有g')
return value
def validate(self, attrs):
password = attrs.get('password')
re_password = attrs.pop('re_password')
if password != re_password:
raise serializers.ValidationError({'re_password': '两次密码不一致'})
return attrs
# create和update方法不需要再重写,ModelSerializer类已提供,且支持所有关系下的连表操作
models
from django.db import models
class User(models.Model):
SEX_CHOICES = (
(0, '女'),
(1, '男'),
)
username = models.CharField(max_length=64, verbose_name='用户名', blank=True, unique=True)
password = models.CharField(max_length=64, verbose_name='密码')
sex = models.IntegerField(choices=SEX_CHOICES, default=0, verbose_name='性别')
img = models.ImageField(upload_to='img', default='img/default.png', verbose_name='头像')
# 开发中,数据不会直接删除,通过字段控制
is_delete = models.BooleanField(default=False, verbose_name='是否注销')
# 数据库数据入库,一般都会记录该数据第一次入库时间,有时候还会记录最后一次更新时间
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
# 第二种自定义序列化字段(插拔式,提倡使用)
@property
def gender(self):
return self.get_sex_display()
@property
def icon(self):
from django.conf import settings
return '%s%s%s' % (settings.BASE_URL, settings.MEDIA_URL, self.img)
class Meta: # 配置类,给所属类提供配置信息
db_table = 'old_boy_user'
verbose_name_plural = '用户表'
def __str__(self): # 不要在这里进行连表操作,比如admin页面可能会崩溃
return self.username
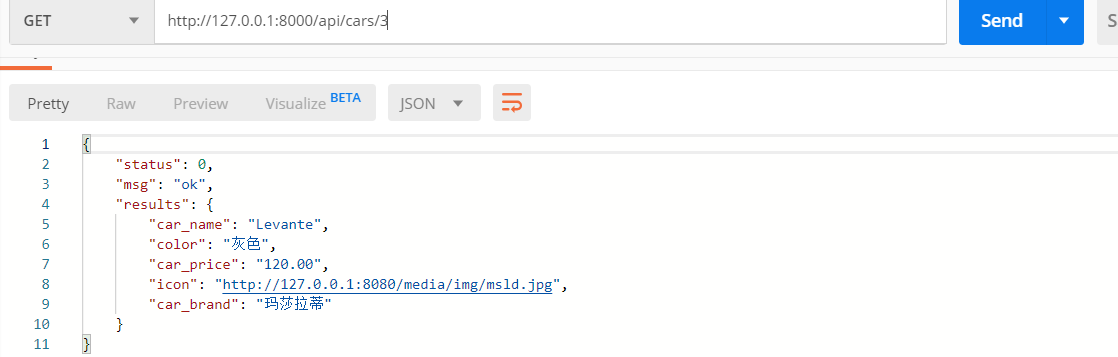
单查
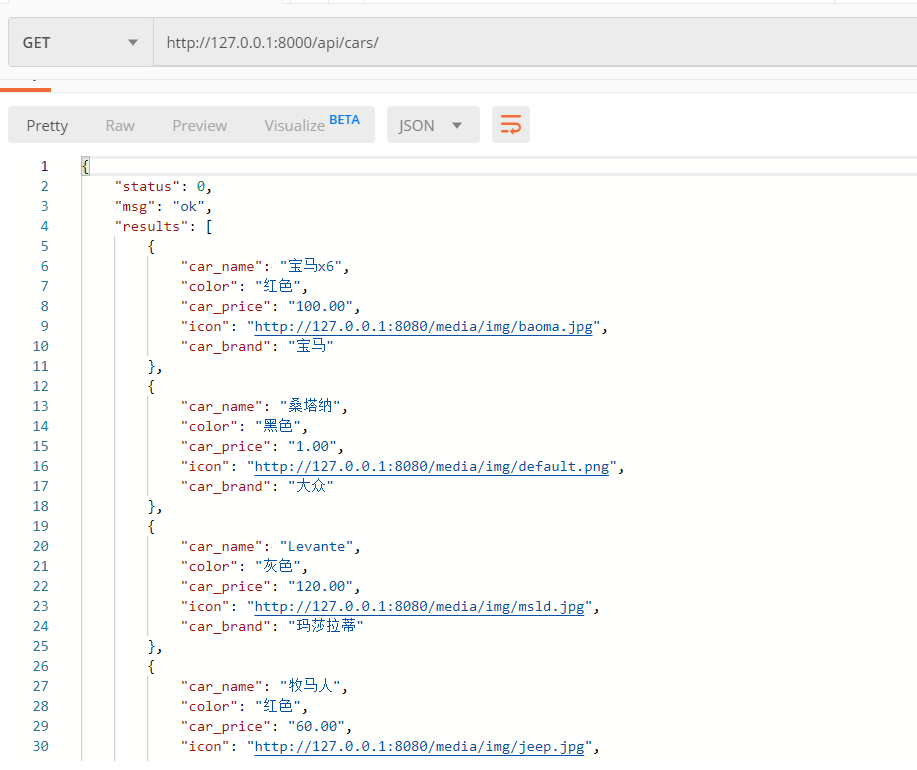
群查
单增